9、中间件、分布式技术
9.1、缓存
1、页面缓存、浏览器缓存
2、网络缓存(Web代理缓存、CDN)
3、服务端缓存(数据库缓存如MySQL、应用级缓存如Redis)
4、多级缓存架构:Nginx本地缓存解决热点数据缓存问题;Redis分布式缓存减少访问回源率;Tomcat缓存防止缓存失效/崩溃之后的冲击;数据库换成提高查询效率
分布式ID问题,如何用?
缓存定义规范:
-
CachingProvider -> CacheManager -> Cache -> Entry
Redis相关:
支持的基本类型、Redis集群构建、同步问题等
参考:
《深入分布式缓存:从原理到实践》学习:
https://blog.csdn.net/jw598527338/article/details/80973628
https://blog.csdn.net/jw598527338/article/details/81360713
9.2、消息系统(JMS,Kafka)
1、JMS的两种模式:
- 点对点(队列模式):多个消费者读取消息队列,每条消息只发送给一个消费者
- 发布订阅:多个消费者订阅主题,主题的每条记录会发布给所有的消费者
参考:https://blog.csdn.net/heyutao007/article/details/50131089
2、Kafka
是什么?
0.10版本之前,Kafka仅仅作为一个消息系统,主要用来解决应用解耦、异步消息、流量削峰等问题。0.10版本之后,Kafka提供了连接器与流处理的能力,它从分布式的消息系统逐步成为一个流式的数据平台。
作为一个流式数据平台,Kafka具备下面三个特点:
- 类似消息系统,提供事件流的发布和订阅
- 存储事件流数据的节点具有故障容错的特点
- 能够对实时的事件流进行流式地处理和分析
原理?
Kafka如何实现上面的三个特点?
1、消息系统,Kafka使用消费组统一了队列&发布订阅两种消息模型,既可以线性扩展消息的处理能力,也允许消息被多个消费组订阅。
2、存储系统,数据写入到Kafka集群的服务节点时,还会复制多份来保证故障时仍然肯用。
3、流处理系统,Kafka提供了完整的流处理API(聚合,连接,转换)等。
4、将以上三个系统组合在一起,既能处理最新的试试数据,也能处理过去的历史数据,流处理平台的核心组件包括:
- 生产者,发布事件流到Kafka的一个或多个主题
- 消费者,订阅Kafka的一个或多个主题,并处理事件流
- 连接器,将Kafka主题和已有数据源连接,支持数据导入和导出
- 流处理,将主题消费输入流,经过处理,产生输出流到输出主题
Kafka基本概念:
1、分区模型
Kafka为每个主题(topic)维护了分布式的分区(partition)日志文件。每个分区都是一个有序的、不可变的记录序列。新的消息不断追加到提交日志中。分区中的每条消息都会按照时间顺序分配到一个单调递增的顺序编号,叫做偏移量(offset),这个偏移量能够唯一定位当前分区中的每一条消息。
Kafka以分区作为最小的粒度,将每个分区分配给消费组中不同且唯一的消费者(一份分区的消息只能被同一个消费组的一个消费者消费,但不同的消费组的不同消费者可以同时消费一个分区的消息)。每个主题有不同的分区,不同的消费者处理不同的分区,一个分区在一个消费组中只有一个消费者的线程在读取,既保证了消费的有序性,也做到了消费者的负载均衡。
2、消费模型
推还是拉?
消费模式分为推(push)模式和拉(pull)模式。推模式是指由Broker主动推送消息至消费端,实时性较好,不过需要一定的流制机制来确保服务端推送过来的消息不会压垮消费端。而拉模式是指消费端主动向Broker端请求拉取(一般是定时或者定量)消息,实时性较推模式差,但是可以根据自身的处理能力而控制拉取的消息量。
---------------------
摘自:https://blog.csdn.net/u013256816/article/details/79838428
推:
优点:有消息才推送,节省资源,实时性好
缺点:无法得知消费者消费速率,可能压垮消费端;应对多个消费者乏力(消费速率不同);消费代理推送消息,无法保证消费者真正收到消息,并且被消费者消费。
拉:
优点:(Kafka的拉取模型)消费者自己记录消费状态,每个消费者独立顺序读取每个分区的消息,可以按照任意的顺序消费消息,自己控制偏移量,也可以处理已经消费过的消息(Kafka不会根据消息消费状态清理处理,可配置消息过期时间来清理)。
缺点:实时性差,需要不断轮询(可采用阻塞/长轮询解决)
3、分布式模型
每个分区都会以副本的方式复制到多个消息代理节点上。其中一个节点作为主副本(Leader),负责所有的客户端读写操作,其他节点作为备份副本(Follower),仅仅从主副本同步数据。主副本故障时,备份副本中的一个副本会被选择为新的主副本。
生产者客户端发布消息到服务端的指定主题,会指定消息所属的分区。生产者发布消息时根据消息是否有键,采用不同的分区策略。消息没有键时,通过轮询方式进行客户端负载均衡;消息有键时根据分区语义确保相同键消息总是发送到同一分区。客户端还可以在主题创建后修改主题的分区数量(注:但是分区数量只能变大不能减小 原因参考--https://blog.csdn.net/u013256816/article/details/82804564)。
消费者通过订阅主题来消费消息,并且每个消费者都会设置一个消费组。分区中的一条消息都只会发送给消费组中的一个消费者。分区是消费者线程模型的最小并行单位。增加服务器节点会提升集群的性能,增加消费者数量会提升处理性能。Kafka保证一个分区内消息的完全有序,多个分区不保证,可通过设置一个分区来保证整个topic的有序消费。
Kafka设计与实现:
1、文件系统的持久化与数据传输效率
(1)、Raid-5顺序存储读取 & 零拷贝技术(sendFile())解决消费者快速消费数据
A、Kafka将数据写到磁盘,充分利用磁盘的顺序读。
B、应用程序----->(文件系统的持久化日志)磁盘缓存------->定期自动刷新到物理磁盘
同时,Kafka在数据写入及数据同步采用了零拷贝(zero-copy)技术,采用sendFile()函数调用,sendFile()函数是在两个文件描述符之间直接传递数据,完全在内核中操作,从而避免了内核缓冲区与用户缓冲区之间数据的拷贝,操作效率极高。Kafka还支持数据压缩及批量发送,同时Kafka将每个主题划分为多个分区,这一系列的优化及实现方法使得Kafka具有很高的吞吐量。经大多数公司对Kafka应用的验证,Kafka支持每秒数百万级别的消息
(2)、生产者发送消息
分区、分批发送,提升效率:将多条消息按照分区进行分组,并采用批量的方式一次发送一个消息集,并且对消息集进行压缩,就可以减少网络传输的带宽,进一步提高数据的传输效率。
2、生产者&&消费者
(1)、拉取模型保证可重复消费,消费有序
(2)、一个消费组中只有一个消费同一分区数据,状态维护简单,有序消费得到保证
3、副本机制和容错处理
(1)、备份副本的日志文件和主副本的日志总是相同的,都有相同的偏移量和相同顺序的消息
(2)、分区的主副本应该均匀的分布到各个服务器,主副本也会跟踪正在同步中的备副本(ISR),如果不存在,则移除
节点存活的定义:
1、节点必须与ZK保持回话
2、如果这个节点是某个分区的备份副本,必须对分区主副本的写操作进行复制,并且复制的进度不能落后太多。
(3)、复制到所有ISR完成后,提交的消息才会被消费
3、ZooKeeper的使用
Kafka重要元数据(分区,偏移量等)采用ZooKeeper存储,保证高可用
利用ZooKeeper进行Leader选举等
参考:
Kafka入门:https://blog.csdn.net/zangdaiyang1991/article/details/84748021
消息系统对比:
Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
RocketMQ
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
Rabbitmq比kafka可靠,kafka更适合IO高吞吐的处理,比如ELK日志收集
Kafka和RabbitMq一样是通用意图消息代理,他们都是以分布式部署为目的。但是他们对消息语义模型的定义的假设是非常不同的。
a) 以下场景你比较适合使用Kafka。你有大量的事件(10万以上/秒)、你需要以分区的,顺序的,至少传递成功一次到混杂了在线和打包消费的消费者、你希望能重读消息、你能接受目前是有限的节点级别高可用或则说你并不介意通过论坛/IRC工具得到还在幼儿阶段的软件的支持。
b) 以下场景你比较适合使用RabbitMQ。你有较少的事件(2万以上/秒)并且需要通过复杂的路由逻辑去找到消费者、你希望消息传递是可靠的、你并不关心消息传递的顺序、你需要现在就支持集群-节点级别的高可用或则说你需要7*24小时的付费支持(当然也可以通过论坛/IRC工具)。
---------------------
摘自:https://blog.csdn.net/yunfeng482/article/details/72856762
参考:https://blog.csdn.net/u013256816/article/details/79838428
https://blog.csdn.net/yunfeng482/article/details/72856762
9.3、热部署
参考:
JAVA热部署原理:https://www.cnblogs.com/pfxiong/p/4070462.html
热部署与热加载:https://blog.csdn.net/haha_66666/article/details/78821498
SpringBoot热部署:https://blog.csdn.net/qq_27384769/article/details/79473992
9.4、JMX
扩展阅读:
理解JMX之介绍和简单使用:https://blog.csdn.net/lmy86263/article/details/71037316
JMX理解:https://blog.csdn.net/u013256816/article/details/52800742
9.5、redis
参考:
Redis基础:https://blog.csdn.net/zangdaiyang1991/article/details/87364542
Redis高级特性:https://blog.csdn.net/zangdaiyang1991/article/details/86468333
Redis与Memcached对比:https://blog.csdn.net/u011489043/article/details/78922390
9.6、ZooKeeper
是什么?
ZooKeeper是一个开放源代码的、高效、可靠的分布式协调服务。设计目标是:将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
设计目标:
- 简单的数据模型
- 可以构建集群
- 顺序访问
- 高性能
怎么工作?
1、分布式系统的两大经典理论:CAP & BASE(参看9.7中总结)。
拜占庭将军问题(Byzantine Generals Problem)
Leslie Lamport在1982年提出的虚拟模型,用来解释一致性问题。拜占庭作为东罗马帝国的首都,地域辽阔,在首都周边有众多将军负责城防,将军之间通过信使来传递消息,达成某些一致的决定。但由于将军中存在叛徒,叛徒会想尽一切办法干扰一致性的达成,甚至是达成叛徒想要的共识从而实现攻击。
拜占庭问题,假设节点总数是N,叛徒将军数为F,则当 N 》= 3F+1 时,问题才有解,共识才能达成,这就是Byzantine Fault Tolerant(BFT)算法。
2、基于以上两种理论,对一个分布式系统进行架构设计的过程中,往往会在系统的可用性和数据一致性之间反复权衡,于是产生了一系列的一致性协议,如2PC&3PC中涉及的一致性协议,Paxos一致性理论。
3、ZoopKeeper采用的一致性协议--ZAB(ZooKeeper Atomic Broadcast,原子消息广播协议)协议
ZAB协议的核心定义了对于那些改变ZooKeeper服务器数据状态的事务请求的处理方式,即:
所有事务请求必须有一个全局唯一的服务器来协调处理,这样的服务器被称为Leader服务器,而余下的其他服务器则成为Follower服务器。Leader服务器负责将一个客户端事务请求转换成一个事务Proposal(提议),并将该Proposal分发给集群中所有的Follower服务器。之后Leader服务器需要等待所有Follower服务器的反馈,一旦超过半数的Follower服务器进行了正确的反馈后,那么Leader就会再次向所有的Follower服务器分发Commit消息,要求其将前一个Proposal进行提交。
另,ZooKeeper中还有一种机器角色:Observer。Observer机器不参与Leader选举过程,也不参与写操作的“过半写成功”策略,因此Observer可以在不影响写性能的情况下提升集群的读性能。
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。
Leader选举过程(FastLeaderElection算法)
Leader选举是保证分布式数据一致性的关键所在。当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举。
1. 服务器启动时期的Leader选举
若进行Leader选举,则至少需要两台机器,这里选取3台机器组成的服务器集群为例。在集群初始化阶段,当有一台服务器Server1启动时,其单独无法进行和完成Leader选举,当第二台服务器Server2启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,于是进入Leader选举过程。选举过程如下
(1) 每个Server发出一个投票。由于是初始情况,Server1和Server2都会将自己作为Leader服务器来进行投票,每次投票会包含所推举的服务器的myid和ZXID,使用(myid, ZXID)来表示,此时Server1的投票为(1, 0),Server2的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下
- · 优先检查ZXID。ZXID比较大的服务器优先作为Leader。
- · 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
对于Server1而言,它的投票是(1, 0),接收Server2的投票为(2, 0),首先会比较两者的ZXID,均为0,再比较myid,此时Server2的myid最大,于是更新自己的投票为(2, 0),然后重新投票,对于Server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于Server1、Server2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了Leader。
(5) 改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。
2. 服务器运行时期的Leader选举
在Zookeeper运行期间,Leader与非Leader服务器各司其职,即便当有非Leader服务器宕机或新加入,此时也不会影响Leader,但是一旦Leader服务器挂了,那么整个集群将暂停对外服务,进入新一轮Leader选举,其过程和启动时期的Leader选举过程基本一致。假设正在运行的有Server1、Server2、Server3三台服务器,当前Leader是Server2,若某一时刻Leader挂了,此时便开始Leader选举。选举过程如下
(1) 变更状态。Leader挂后,余下的非Observer服务器都会讲自己的服务器状态变更为LOOKING,然后开始进入Leader选举过程。
(2) 每个Server会发出一个投票。在运行期间,每个服务器上的ZXID可能不同,此时假定Server1的ZXID为123,Server3的ZXID为122;在第一轮投票中,Server1和Server3都会投自己,产生投票(1, 123),(3, 122),然后各自将投票发送给集群中所有机器。
(3) 接收来自各个服务器的投票。与启动时过程相同。
(4) 处理投票。与启动时过程相同,此时,Server1将会成为Leader。
(5) 统计投票。与启动时过程相同。
(6) 改变服务器的状态。与启动时过程相同。
上边选出的只是准leader,要想变成leader还需完成数据同步。
更加详细的解释可参考《从Paxos到Zookeeper分布式一致性原理与实践》这本书。
数据同步
同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。只有当 集群过半机器都同步完成,准 leader 才会成为真正的 leader。follower 只会接收 zxid 比自己的 lastZxid 大的提议。
当完成Leader选举后,进行故障恢复的第二步就是数据同步: Leader服务器会为每一个Follower服务器准备一个队列,并将那些没有被各个Follower服务器同步的事务以Proposal的形式逐条发给各个Follower服务器,并在每一个Proposal后都紧跟一个commit消息,表示该事务已经被提交,档follower服务器将所有尚未同步的事务proposal都从leader服务器同步过来并成功应用到本地后,leader服务器就会将该follower加入到真正可用的follower列表中。(新选举周期,epoch已经更新了)
每个zookeeper 事务都有一个全局唯一的事务ID,ZXID。ZXID 高32 位是leader 周期epoch,低32 位是递增计数器。从算法角度上看:
第一阶段(准leader生成初始事务集合)
所有follower 向准leader 发送自己最后接收的事务的epoch;
准leader 选取最大的epoch,加1得到e1,将e1 发送给follower;(准leader已经是zxid最大的机器了,且已经完成epoch更新了,防止说个leader出现)
follower 收到准leader 发送的epoch 值之后,与自己的epoch 值作比较,若小于,则将自己的epoch 更新为e1,并向准leader 发送反馈ACK信息(epoch 信息、历史事务集合);
准leader 接收到ACK 消息之后,会在所有历史事务集合中选择其中一个历史事务集合作为初始化事务集合,该事务集合满足ZXID最大;
第二阶段(正式同步)
准leader 将epoch 与 初始化事务集合发送给集群中过半的follower;每个follower 会分配到一个队列,leader 会将那些没有被各个follower 同步的事务以proposal 形式发送给各个follower,并在后面追加commit 消息,表示事务已被提交;follower 接收后,会执行初始化事务集合中的事务(执行过跳过,未执行执行),反馈给leader 表明自己已经处理(追上来了)leader 收到后过半反馈后,发送commit 消息;follower 接收到commit 消息后,提交事务;注意:在zk选举中,通过投票已经确认leader服务器是最大的zxid的节点了,所以同步过程没有那么复杂。
ZAB协议与Paxos算法的异同
ZAB协议并不是 Paxos 算法的一个典型实现,在讲解 ZAB和 Paxos之间的区别之前, 我们首先看下两者的联系,
- 两者都有一个类似于Leader进程的角色,由其负责协调多个Follower运行
- Leader进程都会等待超过半数的Follower做出正确的反馈后,才会将一个提案进行提交。
- 在ZAB协议中,每个Proposal都包含了一个epoch值,用来代表当前的Leader 周期,在Paxos算法中,同样存在这样的一个标识,只是名字变成了Ballot。
- 在Paxos算法中,一个新选举产生的主进程会进行两个阶段的工作,第一阶段被称为读阶段,在这个阶段中,这个新的主进程会通过和所有其他进程进行通信的方式来收集上一个—个主进程提出的提案,并将它们提交.第二阶段被称为写阶段,在这个阶段,与前主进程开始提出自己的提案。
- 在Paxos算法设计的基础上, ZAB协议额外添加了一 个同步阶段。在同步阶段之前,ZAB协议也存在一个和Paxos算法中的读阶段I类似的过程,被称为发现( Discovery)阶段,在同步阶段中,新的 Leader会确存在过半数的Follower已经提交了之前Leader周期中的所有事物的Proposal,在这一同步阶段的引人,能够有效地保证Leader在新的周期中提出事务Proposal之前,所有的进程都已经完成了对之前所有事物的Proposal的提交。
- 一旦完成同步阶段后,那么 ZAB就会执行和 Paxos算法类似 的写阶段。
总的来汫, ZAB协议和 Paxos本质区别在于,两者的设计目标不太一样。 ZAB 协议主要用于构建一个高可用的分布式数椐主备系统,例如ZooKeeper, 而Paxos算法 则是用于构建一个分布式的一致性状态机系统,
---------------------
摘自:https://blog.csdn.net/u013679744/article/details/79240249
4、ZooKeeper中的核心概念
集群角色:Leader、Follower、Observer
会话(session):指客户端会话,客户端与服务器之间的一个TCP长连接,通过这个连接进行心跳检测和Watch事件通知
- tcp短连接:数据发送完成后就关闭连接,下次发送数据时重新建立连接,适用于连接频率很低的情况(比如网页访问)
- tcp长连接:数据发送完后,并不关闭连接,通过相互发送校验包保持连接,再次发送数据时不用再重新建立连接,适用于连接频率很高的情况
参考:https://www.cnblogs.com/onlysun/p/4520553.html
数据节点(Znode):数据节点,持久节点(持久顺序节点)和临时节点(临时顺序节点)(实现分布式锁等的重要特性)两类
版本:Znode版本、子节点版本、ACL版本(保证原子性)
Zookeeper会为每个Znode维护一个叫作Stat的数据结构,结构如图:存在三个版本信息:
version:znode数据的修改次数
cversion:znode子节点修改次数
aversion:znode的ACL修改次数
version是表示对数据节点数据内容的变更次数,强调的是变更次数,因此就算数据内容的值没有发生变化,version的值也会递增。采用CAS操作保证原子性。
Watcher:用户在指定节点上注册一些Watcher,事件触发时,会通知到订阅的客户端
ACL(Access Control Lists):权限控制,保证数据的安全
ZK的高可用:内存模型 + 数据快照 + ZXID事务日志存储
Zookeeper内存模型
Zookeeper的数据模型是树结构,在内存数据库中,存储了整棵树的内容,包括所有的节点路径、节点数据、ACL信息,Zookeeper会定时将这个数据存储到磁盘上。
1. DataTree
DataTree是内存数据存储的核心,是一个树结构,代表了内存中一份完整的数据。DataTree不包含任何与网络、客户端连接及请求处理相关的业务逻辑,是一个独立的组件。
2. DataNode
DataNode是数据存储的最小单元,其内部除了保存了结点的数据内容、ACL列表、节点状态之外,还记录了父节点的引用和子节点列表两个属性,其也提供了对子节点列表进行操作的接口。
3. ZKDatabase
Zookeeper的内存数据库,管理Zookeeper的所有会话、DataTree存储和事务日志。ZKDatabase会定时向磁盘dump快照数据,同时在Zookeeper启动时,会通过磁盘的事务日志和快照文件恢复成一个完整的内存数据库。
DataTree是整个树的核心,不与任何网络、客户端以及请求事务有关。DataTree利用CurrentHashMap<String,DataNode>的属性nodes来存储着整个树的所有节点以及对应的路径,对于临时节点单独放在一个CurrentHashMap中。DataNode是最小的存储单元,保存着节点的数据,ACL,父节点和子节点列表。
对于目标节点的查找并不是使用树的结构层层查找,而是在DataTree中的属性nodes--CurrentHashMap<String,DataNode>根据路径作为key直接查找DataNode,提高了查找效率。
Zookeeper数据与存储
我们知道Zookeeper是将全量数据存储在内存中,但他是怎样进行容错的呢?当节点崩溃后或重新初始化时,是怎么会发到宕机之前的数据呢?这就需要Zookeeper的数据存储实现。感觉大多数内存存储的组件容错机制都差不多,都是利用快照和事务日志来保证节点宕机恢复工作。比如:zookeeper,HDFS的namenode,redis,都是采用快照+事务日志来进行数据持久化,来实现底层数据的一致性。
事务日志:
在配置Zookeeper集群时需要配置dataDir目录,其用来存储事务日志文件。也可以为事务日志单独分配一个文件存储目录:dataLogDir。若配置dataLogDir为/home/admin/zkData/zk_log,那么Zookeeper在运行过程中会在该目录下建立一个名字为version-2的子目录,该目录确定了当前Zookeeper使用的事务日志格式版本号,当下次某个Zookeeper版本对事务日志格式进行变更时,此目录也会变更,即在version-2子目录下会生成一系列文件大小一致(64MB)的文件。
事务日志记录了对Zookeeper的操作,命名为log.ZXID,后缀是一个事务ID。并且是写入该事务日志文件第一条事务记录的ZXID,使用ZXID作为文件后缀,可以帮助我们迅速定位到某一个事务操作所在的事务日志。同时,使用ZXID作为事务日志后缀的另一个优势是:ZXID本身由两部分组成,高32位代表当前leader周期(epoch),低32位则是真正的操作序列号,因此,将ZXID作为文件后缀,我们就可以清楚地看出当前运行时的zookeeper的leader周期。
事务日志的写入是采用了磁盘预分配的策略。因为事务日志的写入性能直接决定看Zookeeper服务器对事务请求的响应,也就是说事务写入可被看做是一个磁盘IO过程,所以为了提高性能,避免磁盘寻址seek所带来的性能下降,所以zk在创建事务日志的时候就会进行文件空间“预分配”,即:在文件创建之初就想操作系统预分配一个很大的磁盘块,默认是64M,而一旦已分配的文件空间不足4KB时,那么将会再次进行预分配,再申请64M空间。
数据快照:
数据快照是Zookeeper数据存储中非常核心的运行机制,数据快照用来记录Zookeeper服务器上某一时刻的全量内存数据内容,并将其写入指定的磁盘文件中。也是使用ZXID来作为文件 后缀名,并没有采用磁盘预分配的策略,因此数据快照文件在一定程度上反映了当前zookeeper的全量数据大小。
与事务文件类似,Zookeeper快照文件也可以指定特定磁盘目录,通过dataDir属性来配置。若指定dataDir为/home/admin/zkData/zk_data,则在运行过程中会在该目录下创建version-2的目录,该目录确定了当前Zookeeper使用的快照数据格式版本号。在Zookeeper运行时,会生成一系列文件。
针对客户端的每一次事务操作,Zookeeper都会将他们记录到事务日志中,同时也会将数据变更应用到内存数据库中,Zookeeper在进行若干次(snapCount)事务日志记录后,将内存数据库的全量数据Dump到本地文件中,这就是数据快照。
过半随机策略:每进行一次事务记录后,Zookeeper都会检测当前是否需要进行数据快照。理论上进行snapCount次事务操作就会开始数据快照,但是考虑到数据快照对于Zookeeper所在机器的整体性能的影响,需要避免Zookeeper集群中所有机器在同一时刻进行数据快照。因此zk采用“过半随机”的策略,来判断是否需要进行数据快照。即:符合如下条件就可进行数据快照:
logCount > (snapCount / 2 + randRoll) randRoll位1~snapCount / 2之间的随机数。这种策略避免了zk集群的所有机器在同一时刻都进行数据快照,影响整体性能。
进行快照:
开始快照时,首先关闭当前日志文件(已经到了该快照的数了),重新创建一个新的日志文件,创建单独的异步线程来进行数据快照以避免影响Zookeeper主流程,从内存中获取zookeeper的全量数据和校验信息,并序列化写入到本地磁盘文件中,以本次写入的第一个事务ZXID作为后缀。
数据恢复:
在Zookeeper服务器启动期间,首先会进行数据初始化工作,用于将存储在磁盘上的数据文件加载到Zookeeper服务器内存中。
数据恢复时,会加载最近100个快照文件(如果没有100个,就加载全部的快照文件)。之所以要加载100个,是因为防止最近的那个快照文件不能通过校验。在逐个解析过程中,如果正确性校验通过之后,那么通常就只会解析最新的那个快照文件,但是如果校验和发现最先的那个快照文件不可用,那么就会逐个进行解析,直到将这100个文件全部解析完。如果将所有的快照文件都解析后还是无法恢复出一个完整的“DataTree”和“sessionWithTimeouts”,则认为无法从磁盘中加载数据,服务器启动失败。当基于快照文件构建了一个完整的DataTree实例和sessionWithTimeouts集合了,此时根据这个快照文件的文件名就可以解析出最新的ZXID,该ZXID代表了zookeeper开始进行数据快照的时刻,然后利用此ZXID定位到具体事务文件从哪一个开始,然后执行事务日志对应的事务,恢复到最新的状态,并得到最新的ZXID。
崩溃恢复相关问题:https://blog.csdn.net/world6/article/details/79873132
更多:
摘自:ZK核心概念及数据存储:https://blog.csdn.net/u013679744/article/details/79230418
5、ZooKeeper开源客户端
- ZkClient
- Curator
Curator解决了很多ZooKeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException等,通过ZooKeeper原生API,提供了一套易用性和可读性更强的Fluent风格的客户端API框架。除此之外,Curator还提供了还提供了ZooKeeper各种应用场景(Recipe,如共享锁服务、Master选举机制和分布式计数器等)的抽象封装。
6、ZooKeeper的典型应用场景
Zookeeper的两大特性(节点特性和watcher机制):
- · 客户端如果对Zookeeper的数据节点注册Watcher监听,那么当该数据及诶单内容或是其子节点列表发生变更时,Zookeeper服务器就会向订阅的客户端发送变更通知。
- · 对在Zookeeper上创建的临时节点,一旦客户端与服务器之间的会话失效,那么临时节点也会被自动删除。
ZooKeeper是一个典型的发布/订阅模式的高可用的分布式数据管理与协调框架,开发人员可以使用它来进行分布式数据的发布与订阅。另一方面,通过对ZooKeeper中丰富的数据节点类型进行交叉使用,配合Watcher通知机制,可以非常方便地构建一系列分布式应用中都会涉及的核心功能,如
- 数据发布/订阅、
- 负载均衡、基本原理是,每个应用的Server启动时创建一个EPHEMERAL(临时)节点,应用客户端通过读取节点列表获得可用服务器列表,并订阅节点事件,有Server宕机断开时触发事件,客户端监测到后把该Server从可用列表中删除
- 命名服务、
-
基本原理:通过调用Zookeeper节点创建的API接口就可以创建一个顺序节点,并且在API返回值中会返回这个节点的完整名字,利用此特性,可以生成全局ID,其步骤如下
1. 客户端根据任务类型,在指定类型的任务下通过调用接口创建一个顺序节点,如"job-"。
2. 创建完成后,会返回一个完整的节点名,如"job-00000001"。
3. 客户端拼接type类型和返回值后,就可以作为全局唯一ID了,如"type2-job-00000001"。
- 分布式协调/通知、
- 集群管理、
- Master选举、
基本原理:
利用Zookeeper的一致性,能够很好地保证在分布式高并发情况下节点的创建一定能够保证全局唯一性,即Zookeeper将会保证客户端无法重复创建一个已经存在的数据节点(由其分布式数据的一致性保证)。
首先创建/master_election/2016-11-12节点,客户端集群每天会定时往该节点下创建临时节点,如/master_election/2016-11-12/binding,这个过程中,只有一个客户端能够成功创建,此时其变成master,其他节点都会在节点/master_election/2016-11-12上注册一个子节点变更的Watcher,用于监控当前的Master机器是否存活,一旦发现当前Master挂了,其余客户端将会重新进行Master选举。
- 分布式锁、
基本原理:
1. 客户端调用create接口常见类似于/shared_lock/[Hostname]-请求类型-序号的临时顺序节点。
2. 客户端调用getChildren接口获取所有已经创建的子节点列表(不注册任何Watcher)。
3. 如果无法获取共享锁,就调用exist接口来对比自己小的节点注册Watcher。对于读请求:向比自己序号小的最后一个写请求节点注册Watcher监听。对于写请求:向比自己序号小的最后一个节点注册Watcher监听。
4. 等待Watcher通知,继续进入步骤2。
此方案改动主要在于:每个锁竞争者,只需要关注/shared_lock节点下序号比自己小的那个节点是否存在即可。
- 分布式队列等。
基本原理:
① FIFO先入先出,先进入队列的请求操作先完成后,才会开始处理后面的请求。FIFO队列就类似于全写的共享模型,所有客户端都会到/queue_fifo这个节点下创建一个临时节点,如/queue_fifo/host1-00000001。
创建完节点后,按照如下步骤执行。
1. 通过调用getChildren接口来获取/queue_fifo节点的所有子节点,即获取队列中所有的元素。
2. 确定自己的节点序号在所有子节点中的顺序。
3. 如果自己的序号不是最小,那么需要等待,同时向比自己序号小的最后一个节点注册Watcher监听。
4. 接收到Watcher通知后,重复步骤1。
② Barrier分布式屏障,最终的合并计算需要基于很多并行计算的子结果来进行,开始时,/queue_barrier节点已经默认存在,并且将结点数据内容赋值为数字n来代表Barrier值,之后,所有客户端都会到/queue_barrier节点下创建一个临时节点,例如/queue_barrier/host1。
创建完节点后,按照如下步骤执行。
1. 通过调用getData接口获取/queue_barrier节点的数据内容,如10。
2. 通过调用getChildren接口获取/queue_barrier节点下的所有子节点,同时注册对子节点变更的Watcher监听。
3. 统计子节点的个数。
4. 如果子节点个数还不足10个,那么需要等待。
5. 接受到Wacher通知后,重复步骤3
更多参考:https://blog.csdn.net/u013679744/article/details/79371022
参考:
分布式锁、ZoopKeeper学习:https://blog.csdn.net/zangdaiyang1991/article/details/86487082
https://www.cnblogs.com/leeSmall/p/9571514.html
分布式学习,一致性Hash,ZooKeeper,Redis:https://blog.csdn.net/u013679744/article/category/7424631
更多阅读:
ZooKeeper基于CP构建:https://blog.csdn.net/paincupid/article/details/80610441
ZooKeeper与Eureka(基于AP构建)区别:http://www.cnblogs.com/zgghb/p/6515062.html
9.7、分布式事务
1、数据库事务
是什么?
是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。一个逻辑工作单元要成为事务,必须满足所谓的ACID(原子性、一致性、隔离性和持久性)属性。
特性?
原子性:事务必须是原子工作单元,对于其数据修改,要么全部执行,要么全部不执行。MySQL redo日志保证原子性。
一致性:指一个事务在执行之前和之后数据库都必须处于一致性状态。而数据库的一致性,指的是数据库的状态满足所有的完整性约束。MySQL redo undo日志保证一致性。
隔离性:由并发事务所作的修改必须与任何其他并发事务所作的修改隔离。事务查看数据时数据所处的状态,到底是另一个事务执行之前的状态还是中间某个状态,相互之间存在什么影响,是可以通过隔离级别的设置来控制的。
持久性:事务结束后,事务处理的结果必须能够得到固化,即写入数据库文件中,即使机器宕机数据也不会丢失,它对于系统的影响是永久性的。
隔离级别?
读未提交(Read Uncommitted):即使一个事务的更新语句没有提交,别的事务也可以读到,没有安全性,几乎不使用。
读已提交(Read Committed):一个事务只能看到其他事务已经提交的更新(Oracle,Sqlserver等数据库的默认隔离级别)。可防止脏读(一个事务读取了另一个事务修改了但是未提交的数据。举个例子,事务一更新了count=101,但是没有提交,事务二此时读取count,值为101而不是100,然后事务一出于某种原因回滚了,然后第二个事务读取的这个值就是噩梦的开始)。
可重复读(Repeatable Read):一个事务中进行了两次或多次同样的对于数据结果的查询,得到的结果是一样的,但不保证对于数据条数的查询是一样的,只要存在读改行数据就禁止写,消除了不可重复读(MySQL数据库的默认隔离级别)。可防止不可重复读(一个事务对同一行数据执行了两次或更多次查询,但是却得到了不同的结果,也就是在一个事务里面你不能重复(即多次)读取一行数据,如果你这么做了,不能保证每次读取的结果是一样的,有可能一样有可能不一样。造成这个结果是在两次查询之间有别的事务对该行数据做了更新操作。举个例子,事务一先查询了count,值为100,此时事务二更新了count=101,事务一再次读取count,值就会变成101,两次读取结果不一样)。
串行化(Serializable):这个事务执行的时候不允许别的事务并发执行.完全串行化的读,只要存在读就禁止写,但可以同时读,消除了幻读。这是事务隔离的最高级别,虽然最安全最省心,但是效率太低,一般不会用。可防止幻读(幻读和不可重复读有点像,只是针对的不是数据的值而是数据的数量。此种异常是一个事务在两次查询的过程中数据的数量不同,让人以为发生幻觉,幻读大概就是这么得来的吧。举个例子,事务一查询order表有多少条记录,事务二新增了一条记录,然后事务一查了一下order表有多少记录,发现和第一次不一样,这就是幻读)。
数据库锁(此分析较局限,更多参考:https://blog.csdn.net/zangdaiyang1991/article/details/88095278)?
一般可以分为两类,一个是悲观锁,一个是乐观锁,悲观锁一般就是我们通常说的数据库锁机制,乐观锁一般是指用户自己实现的一种锁机制。
悲观锁,它对于数据被外界修改持保守态度,认为数据随时会修改,所以整个数据处理中需要将数据加锁。按作用范围划分为两类:
- 行锁
- 表锁
乐观锁,每次自己操作数据的时候认为没有人回来修改它,所以不去加锁,但是在更新的时候会去判断在此期间数据有没有被修改,需要用户自己去实现。既然都有数据库提供的悲观锁可以方便使用为什么要使用乐观锁呢?对于读操作远多于写操作的时候,大多数都是读取,这时候一个更新操作加锁会阻塞所有读取,降低了吞吐量。
实现方式大概包括:
- 版本号(记为version):就是给数据增加一个版本标识,在数据库上就是表中增加一个version字段,每次更新把这个字段加1,读取数据的时候把version读出来,更新的时候比较version,如果还是开始读取的version就可以更新了,如果现在的version比老的version大,说明有其他事务更新了该数据,并增加了版本号,这时候得到一个无法更新的通知,用户自行根据这个通知来决定怎么处理,比如重新开始一遍。这里的关键是判断version和更新两个动作需要作为一个原子单元执行,否则在你判断可以更新以后正式更新之前有别的事务修改了version,这个时候你再去更新就可能会覆盖前一个事务做的更新,造成第二类丢失更新,所以你可以使用update … where … and version=”old version”这样的语句,根据返回结果是0还是非0来得到通知,如果是0说明更新没有成功,因为version被改了,如果返回非0说明更新成功。
- 时间戳(timestamp):和版本号基本一样,只是通过时间戳来判断而已,注意时间戳要使用数据库服务器的时间戳不能是业务系统的时间。
- 待更新字段:和版本号方式相似,只是不增加额外字段,直接使用有效数据字段做版本控制信息,因为有时候我们可能无法改变旧系统的数据库表结构。假设有个待更新字段叫count,先去读取这个count,更新的时候去比较数据库中count的值是不是我期望的值(即开始读的值),如果是就把我修改的count的值更新到该字段,否则更新失败。java的基本类型的原子类型对象如AtomicInteger就是这种思想。
-
所有字段:和待更新字段类似,只是使用所有字段做版本控制信息,只有所有字段都没变化才会执行更新。
参考:
https://blog.csdn.net/hemeinvyiqiluoben/article/details/80928070
2、分布式事务理论
CAP理论:
C (Consistency 一致性):对某个指定的客户端来说,读操作能返回最新的写操作。
对于数据分布在不同节点上的数据来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据,那么就称为强一致,如果有某个节点没有读取到,那就是分布式不一致。
A (Availability 可用性):非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的响应。
合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的,这里的正确指的是比如应该返回 50,而不是返回 40。
P (Partition Tolerance 分区容错性):当出现网络分区后,系统能够继续工作。打个比方,这里集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正常工作。
熟悉 CAP 的人都知道,三者不能共有,如果感兴趣可以搜索 CAP 的证明,在分布式系统中,网络无法 100% 可靠,分区其实是一个必然现象。
Base理论:
BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写,是对 CAP 中 AP 的一个扩展。
基本可用:分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。
软状态:允许系统中存在中间状态,这个状态不影响系统可用性,这里指的是 CAP 中的不一致。
最终一致:最终一致是指经过一段时间后,所有节点数据都将会达到一致。
BASE 解决了 CAP 中理论没有网络延迟,在 BASE 中用软状态和最终一致,保证了延迟后的一致性。
BASE 和 ACID 是相反的,它完全不同于 ACID 的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
分布式事务理论:
2PC & 3PC:
详细参考:https://blog.csdn.net/u013679744/article/details/79188945
| 区别 | 2PC | 3PC |
|---|---|---|
| 阶段 | 提交事务请求 以及 执行事务提交 | 只有协调者有超时判断。3PC将2PC的提交事务请求分成了CanCommit以及PreCommit |
| 超时 | 只有协调者有超时判断 | 3PC上参与者和协调者都有超时的判断 |
优点:降低参与者阻塞范围,并能够在出现单点故障后继续达成一致
缺点:引入preCommit阶段,在这个阶段如果出现网络分区,协调者无法与参与者正常通信,参与者依然会进行事务提交,造成数据不一致。
TCC:

解决了协调者单点,由主业务方发起并完成这个业务活动。业务活动管理器也变成多点,引入集群。
同步阻塞:引入超时,超时后进行补偿,并且不会锁定整个资源,将资源转换为业务逻辑形式,粒度变小。
数据一致性,有了补偿机制之后,由业务活动管理器控制一致性。
对于 TCC 的解释:
Try 阶段:尝试执行,完成所有业务检查(一致性),预留必需业务资源(准隔离性)。
Confirm 阶段:确认真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作满足幂等性。要求具备幂等设计,Confirm 失败后需要进行重试。
Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源,Cancel 操作满足幂等性。Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致。
举个简单的例子:如果你用 100 元买了一瓶水, Try 阶段:你需要向你的钱包检查是否够 100 元并锁住这 100 元,水也是一样的。
如果有一个失败,则进行 Cancel(释放这 100 元和这一瓶水),如果 Cancel 失败不论什么失败都进行重试 Cancel,所以需要保持幂等。
如果都成功,则进行 Confirm,确认这 100 元被扣,和这一瓶水被卖,如果 Confirm 失败无论什么失败则重试(会依靠活动日志进行重试)。
本地消息表(异步确保)
本地消息表这种实现方式应该是业界使用最多的,其核心思想是将分布式事务拆分成本地事务进行处理,这种思路是来源于ebay。我们可以从下面的流程图中看出其中的一些细节:

基本思路就是:
消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
这种方案遵循BASE理论,采用的是最终一致性,笔者认为是这几种方案里面比较适合实际业务场景的,即不会出现像2PC那样复杂的实现(当调用链很长的时候,2PC的可用性是非常低的),也不会像TCC那样可能出现确认或者回滚不了的情况。
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性。
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
消息机制(跟踪事务进行情况):
RocketMQ实现机制

SAGA:
多个事件组合成大事务的方式。有结合CQRS的开源实现(Axon)。
该模型其核心思想就是拆分分布式系统中的长事务为多个短事务,或者叫多个本地事务,然后由 Sagas 工作流引擎负责协调,如果整个流程正常结束,那么就算是业务成功完成,如果在这过程中实现失败,那么Sagas工作流引擎就会以相反的顺序调用补偿操作,重新进行业务回滚。
比如我们一次关于购买旅游套餐业务操作涉及到三个操作,他们分别是预定车辆,预定宾馆,预定机票,他们分别属于三个不同的远程接口。可能从我们程序的角度来说他们不属于一个事务,但是从业务角度来说是属于同一个事务的。

参考:
分布式事务:http://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html
RocketMQ事务实现:https://www.jianshu.com/p/453c6e7ff81c
浅谈数据库并发控制 - 锁和 MVCC:https://draveness.me/database-concurrency-control
分布式事务讲解(推荐):https://www.jianshu.com/p/16b1baf015e8
9.8、分布式锁
三种实现方式:
redis、zookeeper、数据库
参考:
分布式锁(zookeeper&redis&mysql实现)学习:https://blog.csdn.net/zangdaiyang1991/article/details/86487082
9.9、缓存组件、消息组件对比
redis&memcached:https://www.sojson.com/blog/108.html
rabbitMQ:https://www.sojson.com/blog/48.html
9.10、API网关
是什么?
API网关是一个服务器,是系统的唯一入口。从面向对象设计的角度看,它与外观模式类似。API网关封装了系统内部架构,为每个客户端提供一个定制的API。它可能还具有其它职责,如身份验证、监控、负载均衡、缓存、请求分片与管理、静态响应处理。
API网关方式的核心要点是,所有的客户端和消费端都通过统一的网关接入微服务,在网关层处理所有的非业务功能。通常,网关也是提供REST/HTTP的访问API。服务端通过API-GW注册和管理服务。
为什么?
- 客户端请求多个微服务,增加客户端复杂度
- 存在跨域,认证不统一问题
- 与微服务耦合太强,微服务变更,客户端需要变更
怎么做?
客户端统->统一网关->内部微服务
- 易于监控
- 统一认证
- 减少客户端与微服务交互,解耦接口依赖
大致分为:
- 单节点API网关

- Backends for frontends网关

开源网关:
Netflix zuul:Zuul是一种提供动态路由、监视、弹性、安全性等功能的边缘服务。Zuul是Netflix出品的一个基于JVM路由和服务端的负载均衡器(Spring Cloud使用)。
提供能力:
- 身份认证与安全
- 审查与监控
- 动态路由
- 压力测试
- 负载分配
- 静态响应处理
问题:
拿单节点网关来说,这种网关相当于是处于 Web 层和 Service 之间,用来聚合服务的?注意,我们需要的是聚合服务,而以上这些开源项目都不具备这个功能,我说的聚合具体指的是开箱即用。
除了单点问题,
还有一个问题,网关需要承担日志,监控,安全,服务发现,版本控制等,甚至超时,熔断,重试,聚合查询等职能,这很容易造成性能问题。
解决:
单点问题:KeepAlived
性能问题:双重网关(双重网关,外部网关处理安全,认证,限流,监控,日志等,内部网关处理缓存,重试,熔断等)

参考:
API网关:https://www.cnblogs.com/savorboard/p/api-gateway.html
9.11、高并发、稳定、可用性、性能理解
参考:
大型网站技术架构理解:https://blog.csdn.net/zangdaiyang1991/article/details/86486957
9.12、大数据处理
参考:
Hadoop架构:https://blog.csdn.net/baiye_xing/article/details/76228522
Spark架构及原理:https://blog.csdn.net/zjh_746140129/article/details/80463895
https://blog.csdn.net/zxc123e/article/details/79912343
Spark架构:https://blog.csdn.net/swing2008/article/details/60869183
Hadoop与Spark区别:https://blog.csdn.net/yanjiangdi/article/details/78260186
Yarn:https://www.cnblogs.com/wcwen1990/p/6737985.html
9.13、供应链
供应链岗位需要--
10、领域驱动模型
10.1、领域驱动与CQRS
参考:
https://blog.csdn.net/zangdaiyang1991/article/details/85984614
10.2、微服务架构
SOA与微服务区别:

摘自:https://blog.csdn.net/chszs/article/details/78515231
参考:
SOA与微服务架构区别:https://blog.csdn.net/zangdaiyang1991/article/details/86694173
10.3、SpringCloud
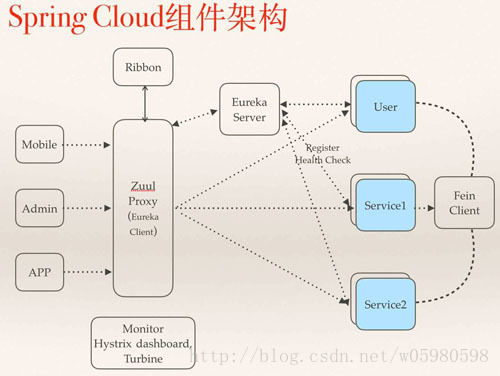
参考:
SpringCloud架构:https://blog.csdn.net/qq_39291929/article/details/81030317
11、SpringBoot
1、设计思想
- 约定优于配置
- 开箱即用
2、模块设计
- 支持开箱即用
- 支持覆写模块内的部分组件
- 支持模块全部推翻重写
3、如何自定义一个spring-starter模块
参考:https://blog.csdn.net/vbirdbest/article/details/79863883
12、UML
参考:
UML绘制:https://blog.csdn.net/zangdaiyang1991/article/details/84982563
13、负载均衡
参考:
负载均衡的总结与思考:http://www.cnblogs.com/xybaby/p/7867735.html
Web负载均衡方案:https://blog.csdn.net/u012562943/article/details/78247781
几种负载均衡:https://blog.csdn.net/github_37515779/article/details/79953788
Nginx架构简介:https://blog.csdn.net/zangdaiyang1991/article/details/84424260
14、连接池
1、数据库连接池
实现原理
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数制约。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
连接池基本的思想是在系统初始化的时候,将数据库连接作为对象存储在内存中,当用户需要访问数据库时,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。使用完毕后,用户也并非将连接关闭,而是将连接放回连接池中,以供下一个请求访问使用。而连接的建立、断开都由连接池自身来管理。同时,还可以通过设置连接池的参数来控制连接池中的初始连接数、连接的上下限数以及每个连接的最大使用次数、最大空闲时间等等。也可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
注意事项
1、数据库连接池的最小连接数是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费。
2、数据库连接池的最大连接数是连接池能申请的最大连接数,如果数据库连接请求超过此数,后面的数据库连接请求将被加入到等待队列中,这会影响之后的数据库操作。
3、最大连接数具体值要看系统的访问量.要经过不断测试取一个平衡值
4、隔一段时间对连接池进行检测,发现小于最小连接数的则补充相应数量的新连接
5、最小连接数与最大连接数差距,最小连接数与最大连接数相差太大,那么最先的连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接。不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,它将被放到连接池中等待重复使用或是空闲超时后被释放。
以上摘自:
数据库连接池原理:https://blog.csdn.net/fuyuwei2015/article/details/72419975
更多:
参考:
数据库连接池原理:https://www.cnblogs.com/wym789/p/6374440.html
数据库连接池:https://blog.csdn.net/phpduang/article/details/80184899
2、线程池
ThreadPoolExecutor 原理与数据库连接池原理类似。
《Effective java》作者指出,维护连接池的成本也是比较高的,除非池中的事物建立消耗较严重,否则要综合考虑成本,连接池一个优秀的实践是数据库连接池。
15、Linux基础
参考:
Linux命令:https://www.cnblogs.com/gaojun/p/3359355.html
https://www.cnblogs.com/yjd_hycf_space/p/7730690.html
16、基本算法
package com.csdn.test.sort;
import java.util.Arrays;
public class Sort
{
// 插入排序
private static void insertSort(int[] arr)
{
int len = arr.length;
int j = 0;
for (int i = 0; i < len; i++)
{
int temp = arr[i];
for (j = i; j > 0 && temp < arr[j - 1]; j--)
{
arr[j] = arr[j - 1];
}
arr[j] = temp;
}
}
// 冒泡排序
private static void bubbleSort(int[] arr)
{
int len = arr.length;
for (int i = 0; i < len - 1; i++)
{
for (int j = 0; j < len - 1 - i; j++)
{
if (arr[j] > arr[j+1])
{
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
private static int getMiddle(int[] arr, int low, int high)
{
int baseValue = arr[low];
while (low < high)
{
while (low < high && baseValue < arr[high])
{
high--;
}
arr[low] = arr[high];
while (low < high && baseValue > arr[low])
{
low++;
}
arr[high] = arr[low];
}
arr[low] = baseValue;
return low;
}
// 快排
private static void quickSort(int[] arr, int low, int high)
{
if(low < high)
{
int middle = getMiddle(arr, low, high);
quickSort(arr, low, middle - 1);
quickSort(arr, middle + 1, high);
}
}
public static void main(String[] args)
{
int[] arr = {20,3,45,34,5};
// quickSort(arr, 0, arr.length - 1);
// bubbleSort(arr);
insertSort(arr);
System.out.println(Arrays.toString(arr));
}
}
手写快速排序:
https://blog.csdn.net/zangdaiyang1991/article/details/86286879
堆排序:
package com.csdn.test.sort;
import java.util.Arrays;
public class HeapSort
{
public static void main(String[] args)
{
int[] a = { 49, 38, 65, 97, 76, 13, 27, 49, 78, 34, 12, 64 };
int arrayLength = a.length;
// 循环建堆
for (int i = 0; i < arrayLength - 1; i++)
{
// 建堆
buildMaxHeap(a, arrayLength - 1 - i);
// 交换堆顶和最后一个元素
swap(a, 0, arrayLength - 1 - i);
System.out.println(Arrays.toString(a));
}
}
// 对data数组从0到lastIndex建大顶堆
public static void buildMaxHeap(int[] data, int lastIndex)
{
// 从lastIndex处节点(最后一个节点)的父节点开始
for (int i = (lastIndex - 1) / 2; i >= 0; i--)
{
// k保存正在判断的节点
int k = i;
// 如果当前k节点的子节点存在
while (k * 2 + 1 <= lastIndex)
{
// k节点的左子节点的索引
int biggerIndex = 2 * k + 1;
// 如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if (biggerIndex < lastIndex)
{
// 若果右子节点的值较大
if (data[biggerIndex] < data[biggerIndex + 1])
{
// biggerIndex总是记录较大子节点的索引
biggerIndex++;
}
}
// 如果k节点的值小于其较大的子节点的值
if (data[k] < data[biggerIndex])
{
// 交换他们
swap(data, k, biggerIndex);
// 将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
k = biggerIndex;
}
else
{
break;
}
}
}
}
// 交换
private static void swap(int[] data, int i, int j)
{
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
}
堆排序:http://www.cnblogs.com/0201zcr/p/4764705.html
JDK的排序算法:
https://blog.csdn.net/xlgen157387/article/details/79863301
其中使用的TimeSort参考:
https://blog.csdn.net/lingzhm/article/details/45022385
参考:
十大排序图文解释:http://www.cnblogs.com/guoyaohua/p/8600214.html
冒泡、快排:https://www.cnblogs.com/0201zcr/p/4763806.html
选择、插入、希尔:https://www.cnblogs.com/0201zcr/p/4764427.html
二叉树与堆:https://blog.csdn.net/qq_28171461/article/details/78855987