LeetCode:350 两个阵列的交叉点II
问题描述:
给定两个数组,编写一个函数来计算它们的交集。
例1:
输入: nums1 = [1,2,2,1],nums2 = [2,2]
输出:[2,2]
例2:
输入: nums1 = [4,9,5],nums2 = [9,4,9,8,4]
输出:[4,9]
注意:
结果中的每个元素应该出现在两个数组中显示的次数。
结果可以是任何顺序。
解决代码:
用map(sort)实现:
#include<iostream>
#include<vector>
#include<map>
#include <algorithm> //sort函数
using namespace std;
class Solution {
public:
//时间复杂度:O(nlogn)
//空间复杂度:O(n)
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
//O(nlongn)
map<int, int> record; //O(n)
for (int i = 0; i < nums1.size(); i++) //O(n)
if (record.find(nums1[i]) == record.end()) //O(logn)
record.insert(make_pair(nums1[i], 1));//查找不到(不在里面),插入,并设置频次为1
else
record[nums1[i]]++;//查找到(里面含有该元素),则频次++
//O(nlogn)
vector<int> resultVector; //O(n)
for(int i=0;i<nums2.size();i++) //O(n)
if (record.find(nums2[i])!=record.end()&&record[nums2[i]] > 0) {//查找得到 O(logn)
resultVector.push_back(nums2[i]);
record[nums2[i]]--;
if (record[nums2[i]] == 0)//频次为0,则擦除
record.erase(nums2[i]);
}
return resultVector;
}
vector<int> intersectSort(vector<int>& nums1, vector<int>& nums2) {
sort(nums1.begin(), nums1.end());
sort(nums2.begin(), nums2.end());
int n1 = 0, n2 = 0;
vector<int> ans;
while (n1 < nums1.size() && n2 < nums2.size())
{
if (nums1[n1] < nums2[n2])n1++;
else if (nums1[n1] > nums2[n2])n2++;
else ans.push_back(nums1[n1]), n1++, n2++;
}
return ans;
}
};
int main() {
vector<int> nums1 = { 1,2,2,1 }, nums2 = { 2,2 };
Solution re;
vector<int> result = re.intersectSort(nums1, nums2);
for (int i = 0; i < result.size(); i++)
cout << result[i] << " ";
getchar();
return 0;
}
使用unoredered_map代码:
#include<iostream>
#include<vector>
#include<map>
#include<unordered_map>
using namespace std;
class Solution{
public:
//时间复杂度:O(n)
vector<int> intersect(vector<int>&nums1,vector<int>&nums2){
//O(n)
unordered_map<int,int> record;
for(int i=0;i<nums1.size();i++) //O(n)
record[nums1[i]]++; //O(1)
//0(n)
vector<int> resultVector;
for(int i=0;i<nums2.size();i++) //O(n)
if(record[nums2[i]]>0){ //O(1)
resultVector.push_back(nums2[i]);
record[nums2[i]]--;
}
return resultVector;
}
};
int main(){
/*c++ 98*/
int a[]= {4,9,5,4},b[]={9,4,9,8,4};
//cout<<sizeof(a)/a[0]<<endl;
vector<int> nums1(a,a+sizeof(a)/a[0]),nums2 (b,b+sizeof(b)/b[0]);
/*c++ 98*/
///else vector<int> nums1={4,9,5},nums2={9,4,9,8,4};
Solution re;
vector<int> result = re.intersect(nums1, nums2);
for (int i = 0; i < result.size(); i++)
cout << result[i] << " ";
getchar();
return 0;
}
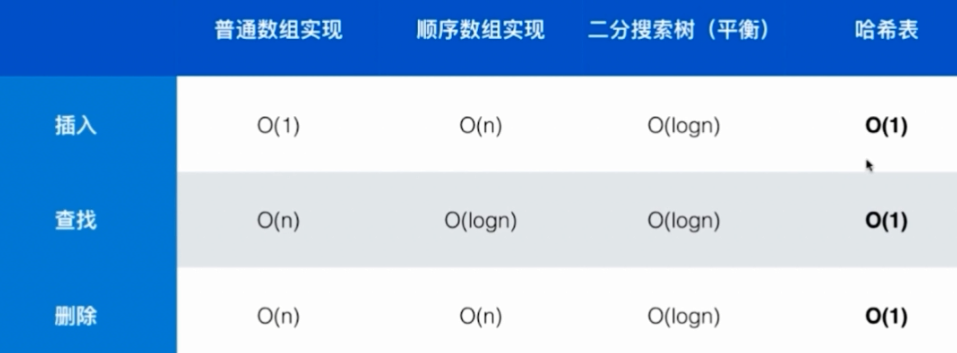
比较而言:
map的底层是用平衡二叉树实现的,unordered_map底层是用哈希表实现的,尽管哈希表的效率很高(O(1)),但哈希表会丢失数据的顺序性,二分搜索树保持数据的顺序性(很容易求数据集的最大最小值,求某个元素的前驱和后继,看某个元素的floor和ceil的值,某个元素的排位rank,选择某一个排位的元素select(选择第几大(或小)的元素))