什么叫闭包:
跨作用域访问函数变量。
又指的一个拥有许多变量和绑定了这些变量的环境的表达式(通常是一个函数),因而这些变量也是该表达式的一部分。
Spark闭包的问题引出:
在spark中实现统计List(1,2,3)的和。如果使用下面的代码,程序打印的结果不是6,而是0。这个和我们编写单机程序的认识有很大不同。为什么呢?
test.scala代码如下:
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.log4j.Logger
import org.apache.log4j.Level
object Test {
def main(args:Array[String]):Unit = {
Logger.getLogger("org").setLevel(Level.OFF)
Logger.getLogger("akka").setLevel(Level.OFF)
Logger.getRootLogger().setLevel(Level.ERROR)
val spark = SparkSession.builder
.appName("Intro")
.config("spark.master", "local")
.getOrCreate();
val rdd = spark.sparkContext.parallelize(List(1,2,3))
var counter = 0
//warn: don't do this
rdd.foreach(x => counter += x)
println("Counter value: "+counter)
spark.sparkContext.stop()
}
}
运行方法:
scala -classpath $(echo *.jar ~/bigdata/spark-2.3.1-bin-hadoop2.7/jars/*.jar| tr ' ' ':') test.scala
问题分析:
counter是在foreach函数外部定义的,也就是在driver程序中定义,而foreach函数是属于rdd对象的,rdd函数的执行位置是各个worker节点(或者说worker进程),main函数是在driver节点上(或者说driver进程上)执行的,所以当counter变量在driver中定义,被在rdd中使用的时候,出现了变量的“跨域”问题,也就是闭包问题。
问题解释:
对于上面程序中的counter变量,由于在main函数和在rdd对象的foreach函数是属于不同“闭包”的,所以,传进foreach中的counter是一个副本,初始值都为0。foreach中叠加的是counter的副本,不管副本如何变化,都不会影响到main函数中的counter,所以最终打印出来的counter为0.
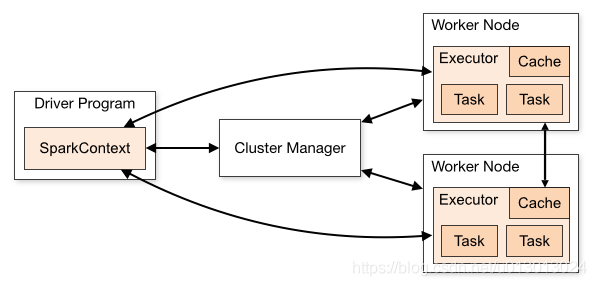
当用户提交了一个用scala语言写的Spark程序,Spark框架会调用哪些组件呢?首先,这个Spark程序就是一个“Application”,程序里面的mian函数就是“Driver Program”, 前面已经讲到它的作用,只是,dirver程序的可能运行在客户端,也有可有可能运行在spark集群中,这取决于spark作业提交时参数的选定,比如,yarn-client和yarn-cluster就是分别运行在客户端和spark集群中。在driver程序中会有RDD对象的相关代码操作,比如下面代码的newRDD.map()
class Test{
def main(args: Array[String]) {
val sc = new SparkContext(new SparkConf())
val newRDD = sc.textFile("")
newRDD.map(data => {
//do something
println(data.toString)
})
}
}涉及到RDD的代码,比如上面RDD的map操作,它们是在Worker节点上面运行的,所以spark会透明地帮用户把这些涉及到RDD操作的代码传给相应的worker节点。
如果在RDD map函数中调用了在函数外部定义的对象,因为这些对象需要通过网络从driver所在节点传给其他的worker节点,所以要求这些类是可序列化的,比如在Java或者scala中实现Serializable类,除了java这种序列化机制,还可以选择其他方式,使得序列化工作更加高效。
worker节点接收到程序之后,在spark资源管理器的指挥下运行RDD程序。
不同worker节点之间的运行操作是并行的。
在worker节点上所运行的RDD中代码的变量是保存在worker节点上面的,在spark编程中,很多时候用户需要在driver程序中进行相关数据操作之后把该数据传给RDD对象的方法以做进一步处理,这时候,spark框架会自动帮用户把这些数据通过网络传给相应的worker节点。
除了这种以变量的形式定义传输数据到worker节点之外,spark还另外提供了两种机制,分别是broadcast和accumulator。
相比于变量的方式,在一定场景下使用broadcast比较有优势,因为所广播的数据在每一个worker节点上面只存一个副本,而在spark算子中使用到的外部变量会在每一个用到它的task中保存一个副本,即使这些task在同一个节点上面。
所以当数据量比较大的时候,建议使用广播而不是外部变量。
#####################以上是转载的内容###########################
好了,这里加点东西,
如果是broadcast方式如何使用呢?代码如下:
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.log4j.Logger
import org.apache.log4j.Level
object Test {
def main(args:Array[String]):Unit = {
Logger.getLogger("org").setLevel(Level.OFF)
Logger.getLogger("akka").setLevel(Level.OFF)
Logger.getRootLogger().setLevel(Level.ERROR)
val spark = SparkSession.builder
.appName("Intro")
.config("spark.master", "local")
.getOrCreate();
val broadcastVar = spark.sparkContext.broadcast(Array("orange","apple","pear","orange"))
val dictionary = Map(("man"-> "noun"), ("is"->"verb"),("mortal"->"adjective"))
def getElementsCount(word :String, dictionary:Map[String,String]):(String,Int) =
{
dictionary.filter{ case (wording,wordType) => wording.equals((word))}.map(x => (x._2,1)).headOption.getOrElse(("unknown" -> 1))
//some dummy logic
}
val words = spark.sparkContext.parallelize(Array("man","is","mortal","mortal","1234","789","456","is","man"))
val grammarElementCounts = words.map( word =>
getElementsCount(word,dictionary)).reduceByKey((x,y) => x+y)
grammarElementCounts.collect().foreach(println)
spark.sparkContext.stop()
}
}运行方式是:
scala -classpath $(echo *.jar ~/bigdata/spark-2.3.
1-bin-hadoop2.7/jars/*.jar| tr ' ' ':') broadcast_test.scala
运行结果:
(adjective,2)
(noun,2)
(verb,2)
(unknown,3)
如果是accumulate的方式如何计数呢?accumulate_test.scala代码如下:
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.log4j.Logger
import org.apache.log4j.Level
object Test {
def main(args:Array[String]):Unit = {
Logger.getLogger("org").setLevel(Level.OFF)
Logger.getLogger("akka").setLevel(Level.OFF)
Logger.getRootLogger().setLevel(Level.ERROR)
val spark = SparkSession.builder
.appName("Intro")
.config("spark.master", "local")
.getOrCreate();
val rdd = spark.sparkContext.parallelize(List(1,2,3))
var counter = spark.sparkContext.accumulator(0)
//warn: don't do this
rdd.foreach(x => counter += x)
println("Counter value: "+counter)
spark.sparkContext.stop()
}
}运行方法:
scala -classpath $(echo *.jar ~/bigdata/spark-2.3.
1-bin-hadoop2.7/jars/*.jar| tr ' ' ':') accumulate_test.scala
运行结果:
6
#######################################
另外关于Node数量和Executor数量放个图
参考文献:
https://blog.csdn.net/liangyihuai/article/details/56840473
https://www.cnblogs.com/sunshisonghit/p/6063296.html?utm_source=itdadao&utm_medium=referral
http://www.huaxiaozhuan.com/%E5%B7%A5%E5%85%B7/spark/chapters/04_acc_broadcast.html
https://blog.knoldus.com/broadcast-variables-in-spark-how-and-when-to-use-them/