2019-05-09
关键字:Flume 架构、Flume 轻松学、Flume 代理、source channels sink
这篇文章不撸代码,纯聊天,聊聊 Flume 的架构。先弄懂架构,再去谈代码会轻松很多。
1、Flume 是什么
Flume 诞生于 2011 年,并于 2012 年在 Apache 中孵化成功。
Flume 其实共可分 2 个版本
1、0.x 版本
2、1.x 及以上版本
这两个版本可以认为架构不同。但我们不必去深究它们之间的区别,直接选择最新稳定版本来使用就可以了。
Flume 在大数据领域的应用非常广泛。如果您初次接触 Flume ,那么简单地将它理解成是一个日志收集工具就好了。举个例子,我们知道有很多软件都会产生日志文件。在大数据领域,日志文件是分析的重点之一。但日志文件是持续不断生成的啊,尤其是现在进入实时流计算时代的情况下,我们经常会有每产生一条日志,就分析一条日志的需求。而我们的大数据分析引擎是不能直接从日志文件里去读取数据的,因此,就诞生了 Flume ,Flume 会负责帮助我们将刚产生的日志文件送到我们指定的地方去,以供进一步的分析使用。
2、Flume 架构图概览
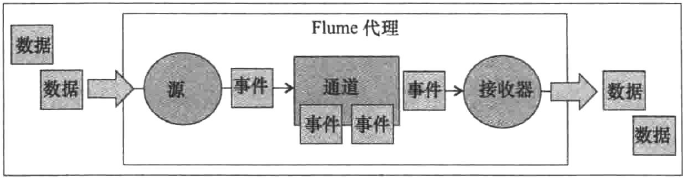
图1 Flume 架构
上图 1 是一个完整的 Flume 架构图。很多同学仅仅将 Flume 代理中的几大模块称之为 Flume 架构,这在笔者看来是不严谨的。真正的架构,除了软件自身组成以外,与软件息息相关的外部数据也必须得算进去。因此,以上图从左至右来看,Flume 架构主要包含以下几个模块
1、外部输入数据
2、源(source)
3、通道(channel)
4、接收器(sink)
5、事件(event)
6、输出数据
其实关于这个架构啊,我们可以拿它和我们厨房里的水槽来类比。

图2 水槽与Flume
这个外部数据,可以类比成水厂供到我们家里来的水。
而架构图中的 源(source)则可以类比成是上图中的水龙头。
通道(channel)呢,则可以类比成上图中的盛水盆。
接收器(sink)则可以类比成是盛水盆下方的漏水装置。
事件(Event)可以类比成是暂存在盛水盆里的水。
而最后的输出数据,毫无疑问就是从漏水装置中流出去的水咯。
可能有些同学会有个疑问:Flume 自身的软件架构,官方称它为 代理(Agent)。为什么会将 Flume 称之为代理呢?
关于这个问题,其实笔者也不知道正确答案是什么,但是笔者有一个能自圆其说的解释。通过前面第 1 节的介绍我们知道了 Flume 大概就是一个倒腾日志倒腾数据的软件,但其实 Flume 并不仅仅只是简单的做一个 “搬运工” 的角色,它可以对我们的数据 “做一些手脚” 的。因此 Flume 在这里的角色就有点像是中介了。中介说好听一点就是代理啊。因此,将 Flume 称为代理是各种没毛病的操作啊。
好,上面简单了解了一下 Flume 架构的组成。接下来,我们再来深入探究探究各个组成的内里。
3、source
源(source)是将外部数据转换成适合于在 Flume 内部流传的事件的组件。为什么 Flume 要如此大费周章将日志转换成事件呢?其实在前面也提到过,Flume 的角色更像是一个中介,它有可能要对流经它的数据做一些额外的处理,而原始的数据文件可能不太方便做额外处理,所以不计代价地将原始数据转换成了 Flume 事件了。关于事件,后面的章节中会有更详细的解释。
关于 Flume 源可以接受的数据来源有很多种,这里没法将各种类型的源都解释一遍,事实上笔者目前也并没有了解所有的源类型。这里将 flume 支持的源类型官网链接贴出来,大家有需要的时候再去官网查询即可。Flume 支持的源类型 进到这个官网页面后留意一下左侧边栏,在下方找到 Flume Source 项,该项下面的子标签都是 Flume 所支持的源类型
图3 Flume 官网源类型
外部数据进到源以后会被封装成事件(Event),随后再传送到通道(Channel)中去。在这里需要额外提一下,一个 Flume 实例中是可以有多个源的,想象一下,确实是有些厨房里的水槽中安装了有多个水龙头的,比如一个龙头供应冷水,另一个龙头供应热水,甚至你乐意的话还可以有一个龙头供应冰水。
同时呢,同一个源中的数据,是支持往多个通道中去写的。这可以类比成我们厨房里的水槽有多个盛水盆,然后我们安装了一个具有分流功能的水龙头,这样就可以将同一个源头的水同时往不同的盛水盆中送了。如下图所示

图4
这种控制事件往哪个通道中写的模块就被称为通道选择器。Flume 中目前有两种通道选择器
1、复制通道选择器
2、多路通道选择器
复制通道选择器的功能简单,仅仅是将源产生的事件的副本分别写到每一个通道中去。它是雨露均沾型的分发事件。
而多路通道选择器则需要根据事件中的某些条件来决定写到哪个通道中去。多路通道选择器通常要配合拦截器才能发挥出其作用。关于拦截器,后面的章节会有介绍。
4、channel
通道(channel)在 Flume 中的定位是事件的暂存区。通道接收来自源的事件,并将这些事件输出到接收器(sink)中去。Flume 中的通道也有很多种,按需选择不同类型的通道即可。这里直接给出官网贴的所有通道类型,如下图

图5 通道类型
一个 Flume 实例中允许有多个通道存在。
5、sink
接收器(sink)的翻译其实不是很准确,只是为了形象一点,才将它强行译成是接收器的。不过如果将它与厨房中的水槽来类比,sink 就是盛水盆底部的漏槽。事件在到达接收器以后会做解封装处理,重新将事件解封装成数据文件送到设定的地方去。
与源所不同的是,一个接收器仅能接收一个通道的事件数据。厨房中的盛水盆也确实是只能安装一个漏槽啊。
Flume 支持的接收器类型也非常多。大家同样按需去官网查询想要的接收器相关的信息即可。
图6 接收器
一般对于大数据领域来说,比较常用的接收器输出类型是 HDFS 类型,将收集到的数据直接存到 HDFS 上去。
同时,Flume 在关于路径与名称的配置中,支持时间转义序列。诸如 %Y , %m , %D 这些来表示当前年月日这种还是很常用的,它们能很有效地降低我们的工作量。
6、事件
前面说过,外部数据在 Flume 中是以事件的形式传递的。事件由若干个事件头和事件体组成。
事件头是一些键值对,用于记载一些描述性的信息。
事件体则是字节数组,用于承载实际数据用的。
前面有提到,Flume 之所以要费如此大代价将原始数据转换成事件,根本原因还是为了提供一个便于在传递过程中修改数据内容的机会。而这种修改数据内容的机制被称为 拦截器。
拦截器可以被放置在源产生了事件以后以及接收器写出事件之前。
拦截器的一种用途是和多路通道选择器配合,用于控制源中的事件进入到哪个通道。另一种用途可以用以修改事件中的数据,比如有时可能所传递的数据中包含一些敏感信息,这个时候就可以通过拦截器将这些数据做脱敏处理了。