版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_26963433/article/details/90053661
参考博客
https://blog.csdn.net/lzwglory/article/details/53810588
一:原因分析
多次格式化导致/home/hadoop/hdpdata/dfs/name/current目录下version文件id发生冲突
,注意:格式化只能执行一次
clusterID=CID-510eb0a4-284b-494c-8ff5-a362cd1516b5
cTime=0
datanodeUuid=c0b675da-1523-4d87-9bbd-f4ad051f5688
二:解决方案
方式1:比较麻烦
先找到/etc/hadoop/hdfs-site.xml
里面有datanode的路径,在那个路径下找:/current/VERSION文件,即可修改clusterID
方式2:删除data,然后格式化
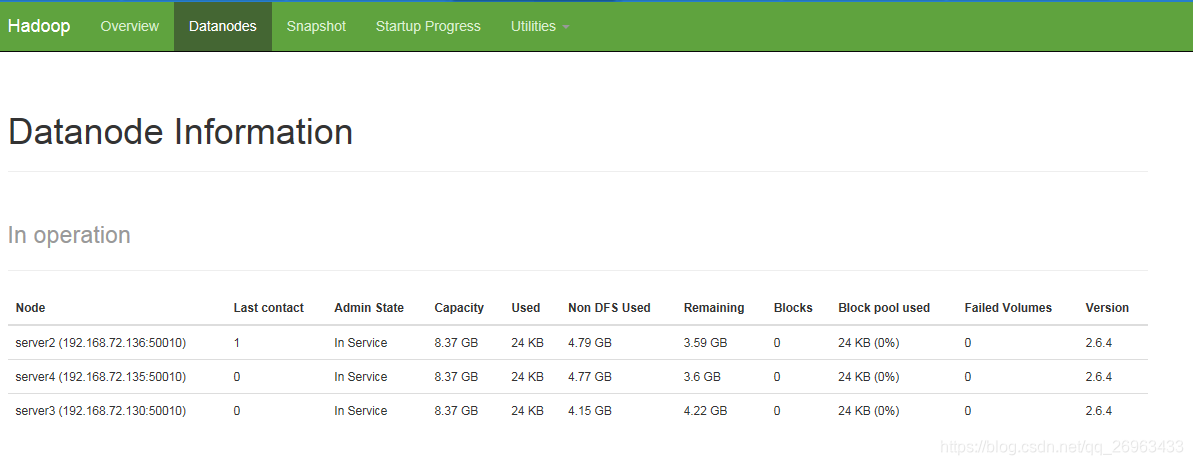
集群中各个服务器的data文件目录都应删除,如果只是删除主节点的,将就启动一个datanode
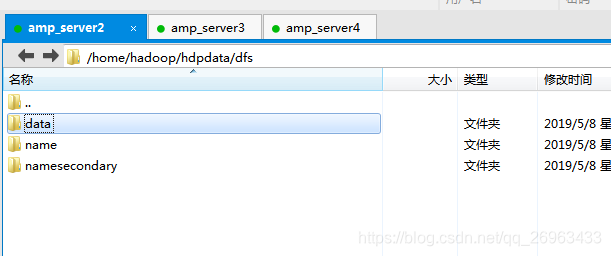
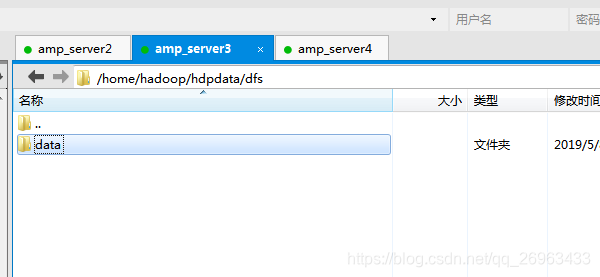
删除后,先格式化
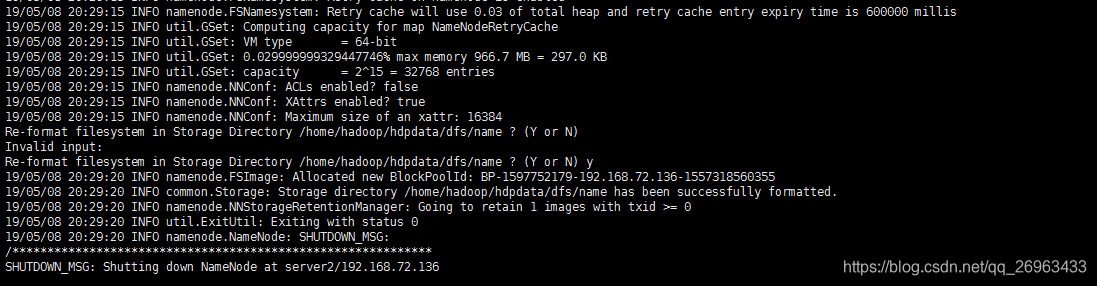
然后启动
start-dfs.sh和start-yarn.sh,这样就会在之前的目录下重新创建一个新的data文件目录了,然后就会产生新的version
三:测试