网易云音乐评论爬虫①:全部热门歌曲及其 id 号
今天我给大家介绍一下用Python爬取网易云音乐全部歌手的热门歌曲.由于歌手个人主页的网页源代码中还嵌入了一个子网页(框架源代码里面包含了我们需要的信息),因此我们不能使用requests库来爬取,而使用selenium,接下来,让我详细讲解整个爬取过程.
一,构造歌手个人主页的URL
前段时间我们获取了网易云音乐全部歌手的id号,今天我们就利用全部歌手的id号来构造歌手个人主页的URL,从而实现用爬取全部歌手的热门歌曲及其id号的目的.以歌手 薛之谦的个人主页 为例,来看一下他的主页的URL为:
https://music.163.com/#/artist?id=5781
因此只需要根据歌手对应的id就可以构造出歌手的个人主页,在歌手的个人主页我们能看到热门作品这一栏.网易云音乐全部歌手id号点击获取(csv文件)
二,分析网页源代码
现在我们就要用Python爬虫去爬取这些内容.如果你用requests库去爬取的话,返回的网页源代码中根本就没有这些信息.这时我们打开薛之谦的个人主页鼠标右键分别查看网页的源代码和查看框架的源代码.你会发现网页源代码和用requests库请求返回的源代码一摸一样(里面没有我们要爬取的信息),而在框架源代码中有我们要爬取的热门作品的信息,因此我们只需要将框架源代码爬取下来,然后再解析即可得到我们需要的歌手的热门作品的信息.
三,网页源代码和框架源代码的区别
网页源代码是指父级网页的源代码.另外网页中还有一种节点叫iframe,也就是子Frame,相当于网页的子页面,它的结构和外部网页的结构完全一致,框架源代码就是这个子网页的源代码.
四,获取框架源代码
这里我们使用selenium库来爬取,在selenium打开页面后,默认是在父级frame里面进行操作,而此时页面中还有子frame,它是不能获取到子frame里面的节点的,因此这时我们需要使用swith_to.frame()方法来切换到子frame中去,这时请求得到的代码就从网页源代码切换到了框架源代码,于是我们便能够提取我们需要的热门作品的信息了.通过歌手的个人主页的URL来爬取其框架源代码,具体爬取框架源代码的函数:
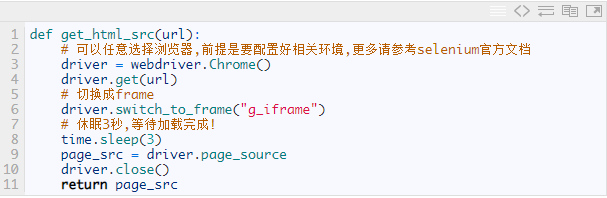
返回结果为歌手个人主页的框架源代码,里面包含了我们需要的信息.
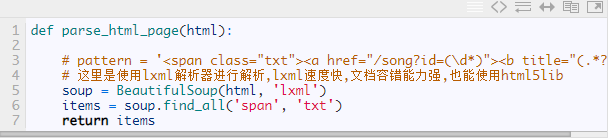
五,解析源代码
我们使用bs4库进行解析,需要的信息包含在HTML5的下面代码片段中:

因此可定义下面函数对其进行解析:
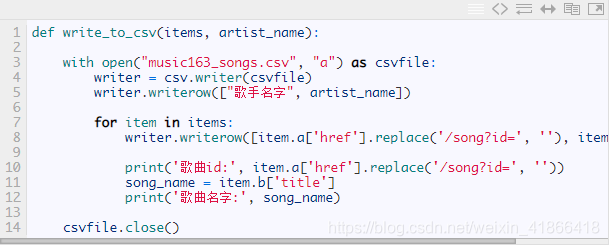
六,写入csv文件
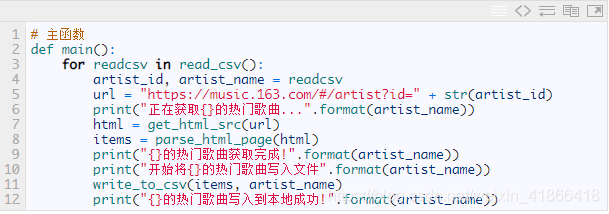
七,读取csv文件,构造全部歌手的个人主页
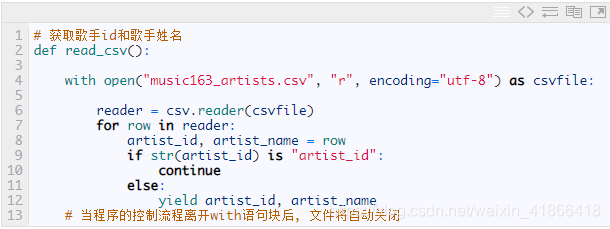
八,程序主函数