目录
- 1、运算符
- 2、基本数据类型
- 2.1、数字
- 2.2、布尔值
- 2.3、字符串(str)
- 2.3.1、字符串的乘法
- 2.3.2、字符串的用法
- 2.3.2.1、capitalize
- 2.3.2.2、lower
- 2.3.2.3、casefold
- 2.3.2.4、center
- 2.3.2.5、count
- 2.3.2.5、startwith和endswith
- 2.3.2.6、find
- 2.3.2.7、format
- 2.3.2.7、format_map
- 2.3.2.8、index
- 2.3.2.9、isalnum
- 2.3.2.10、isalpha
- 2.3.2.11、expandtabs
- 2.3.2.12、isdecimal和isdigit
- 2.3.2.13、swapcase
- 2.3.2.14、isidentifier
- 2.3.2.15、islower和isupper
- 2.3.2.16、isnumeric
- 2.3.2.17、isprintable
- 2.3.2.18、isspace
- 2.3.2.19、title
- 2.3.2.20、istitle
- 2.3.2.21、join
- 2.3.2.21、ljust和rjust
- 2.3.2.22、zfill
- 2.3.2.23、lower和upper
- 2.3.2.24、strip和lstrip、rstrip
- 2.3.2.25、maketrans和translate
- 2.3.2.26、partition和rpartition
- 2.3.2.27、split和rsplit
- 2.3.2.28、splitlines
- 2.3.2.29、startswith和endswith
- 2.3.2.30、swapcase
- 2.3.2.32、以下6个使用频率超高
- 2.3.2.33、获取字符串中的某个字符
- 2.3.2.34、len
- 2.3.2.35、将字符串中的字符逐个输出
- 2.3.2.36、range
- 2.3.2.37、字符串一旦创建不可修改
- 2.3.2.38、输入一个字符串,输出其索引和字符
- 2.4、列表(list)
- 2.4.1、列表格式
- 2.4.2、列表中可以嵌套任何类型
- 2.4.3、索引取值
- 2.4.4、切片取值
- 2.4.5、for循环
- 2.4.5、while循环
- 2.4.6、索引修改
- 2.4.7、切片修改
- 2.4.8、索引删除
- 2.4.9、切片删除
- 2.4.10、in操作
- 2.4.11、字符串转换成列表
- 2.4.12、列表中所有的元素拼后转换成字符串
- 2.4.13、append
- 2.4.13、clear
- 2.4.14、copy
- 2.4.15、count
- 2.4.16、extend
- 2.4.16、 index
- 2.4.17、 insert
- 2.4.18、pop
- 2.4.19、remove
- 2.4.20、删除方法总结
- 2.4.21、reverse
- 2.4.2、sort
- 2.5、元祖(tuble)
- 2.6、字典(dict)
1、运算符
1.1、算数运算

1.2、比较运算

1.3、赋值运算

1.4、逻辑运算

1.5、成员运算

1.5.1、in
name="中华人民共和国"
if "中华" in name:
print("OK")
else:
print("Error")
输出:OK
1.5.2、not in
#!/usr/bin/env python
# -*- coding:utf-8 -*-
name="中华人民共和国"
if "国家" not in name:
print("OK")
else:
print("Error")
输出:OK
2、基本数据类型
2.1、数字
python3:无论整数有多长都叫int
python2:跟据整数的取值范围又分int、long等
2.1.1 int的使用
2.1.1.1、将字符串转换为数字
#!/usr/bin/env python
# -*- coding:utf-8 -*-
a="123"
b=int(a) #将字符串转换成数字
print(type(a),a) #输出a的数据类型和a的值
print(type(b),b) #输出b的数据类型和b的值
输出:
<class ‘str’> 123
<class ‘int’> 123
#!/usr/bin/env python
# -*- coding:utf-8 -*-
num="0010"
v=int(num,base=16) #将num按16进制,转换成10进制
print(v)
输出:16
2.1.1.2、bit_lenght
#!/usr/bin/env python
# -*- coding:utf-8 -*-
age=8
v=age.bit_length() #age用多少位的二进制数表示
print(v)
输出:4
2.2、布尔值
- True
- False
- not True
- not False
#!/usr/bin/env python
# -*- coding:utf-8 -*-
print(not False)
print(not True)
输出:
True
False
2.3、字符串(str)
2.3.1、字符串的乘法
#!/usr/bin/env python
# -*- coding:utf-8 -*-
str="abc"
print(str*3)
输出:abcabcabc
2.3.2、字符串的用法
2.3.2.1、capitalize
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="alex"
v=test.capitalize() //首字母大写
print(v)
输出:Alex
2.3.2.2、lower
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="ABC"
v=test.lower() //字母全部转换成小写
print(v)
输出:abc
2.3.2.3、casefold
与lower功能相同,但casefold功能更强大,除了常见的英文大小写,其它语言的大小写也可以转换
2.3.2.4、center
设置宽度,并将内容居中
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="abc"
v=test.center(10,"*") //第二个参数,只能填一个字符,不填默认为空
print(v)
输出:abc*
2.3.2.5、count
count的语法
str.count(sub, start= 0,end=len(string))
参数:
-
sub – 搜索的子字符串
-
start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。(包括start)
-
end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。(不包括end)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="aaaaaaaaaa" #10个a
v=test.count('a') #统计有多少个字符a,输出10
v1=test.count('a',0) #从第0个字符算起,输出10
v2=test.count('a',1) #从第一个字符算起,输出9
v3=test.count('a',0,9) #从第0个字符算到第9个字符前,输出9
v4=test.count('a',0,10) #从第0个字符算到第10个字符前,输出10
v5=test.count('a',1,6) #从第1个字符算到第6个字符前,输出5
print(v)
print(v1)
print(v2)
print(v3)
print(v4)
print(v5)
输出结果:
3
2
3
1
2.3.2.5、startwith和endswith
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="abc"
v=test.startswith("ab") #是否以ab字符开头
v1=test.endswith("bc") #是否以bc字符结尾
print(v) #输出True
print(v1) #输出True
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="012345abc9"
v=test.startswith("ab",6) #从第6个字符开始算是否以ab字符开头
v1=test.endswith("bc",6,8) #从第6个字符开始算到第8个字符前截止,是否是bc结尾
v2=test.endswith("bc",6,9) #从第6个字符开始算到第9个字符前截止,是否是bc结尾
print(v) #True
print(v1) #False
print(v2) #True
2.3.2.6、find
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="012345abc9"
v=test.find("a") #从前往后找a并获取其位置索引
v1=test.find("c",6,8) #从第6个字符开始到第8个字符截止,找c并获取其位置索引,找不到返-1
v2=test.find("c",6,9) #从第6个字符开始到第8个字符截止,找c并获取其位置索引
print(v) #输出6
print(v1) #输出-1,表示没找到
print(v2) #输出8
2.3.2.7、format
第一种方法:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="I am {name},age{n}"
print(test) #输出:I am {name},age{n}
v=test.format(name="chuhe",n="25")
print(v) #输出:I am chuhe,age25
第二种方法:用索引占位符
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="I am {0},age{1}"
print(test) #输出:I am {name},age{n}
v=test.format("chuhe",25)
print(v) #输出:I am chuhe,age25
2.3.2.7、format_map
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="I am {name},age{n}"
print(test) #输出:I am {name},age{n}
v=test.format(name="chuhe",n="25")
print(v) #输出:I am chuhe,age25
v1=test.format_map({"name":"chuhe","n":"25"})
print(v1) #输出:I am chuhe,age25
2.3.2.8、index
功能类似find,但是index如果找不到字符会报错,不像find一样会返-1
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="012345abc9"
v=test.index("a")
print(v) #输出6
2.3.2.9、isalnum
字符串中是否只包含字母、数字和中文
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test="012345abc9"
test1="012345abc9_"
test2="012345abc9+"
v=test.isalnum()
v1=test1.isalnum()
v2=test2.isalnum()
print(v) #True
print(v1) #False
print(v2) #False
2.3.2.10、isalpha
字符串中是否只包含字母和中文
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="a1"
s1="abc"
s2="中ab"
v=s.isalpha()
v1=s1.isalpha()
v2=s2.isalpha()
print(v) #False
print(v1) #True
print(v2) #True
2.3.2.11、expandtabs
#!/usr/bin/env python
# -*- coding:utf-8 -*-
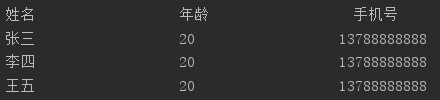
s="姓名\t年龄\t手机号\t\n张三\t20\t13788888888\t\n李四\t20\t13788888888\t\n王五\t20\t13788888888"
v=s.expandtabs(20)
print(v)
将字符串分组,分组以20个字符为一组,
或遇/t为一组,\t负责将该组以空格补至20个字符
输出如下图:
2.3.2.12、isdecimal和isdigit
判断是否是数字
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="1"
v=s.isdecimal() #True
v1=s.isdigit() #True
print(v,v1)
s1="一"
v=s1.isdecimal() #False
v1=s1.isdigit() #False
print(v,v1)
s2="壹"
v=s2.isdecimal() #False
v1=s2.isdigit() #False
print(v,v1)
s3="①"
v=s3.isdecimal() #False
v1=s3.isdigit() #True
print(v,v1)
s4="ⅠⅡⅢ"
v=s4.isdecimal() #False
v1=s4.isdigit() #False
print(v,v1)
s5="㈠"
v=s5.isdecimal() #False
v1=s5.isdigit() #False
print(v,v1)
s6="⒈"
v=s6.isdecimal() #True
v1=s6.isdigit() #True
print(v,v1)
s7="⑴"
v=s7.isdecimal() #True
v1=s7.isdigit() #True
print(v,v1)
2.3.2.13、swapcase
大小写互换
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="abcD"
v=s.swapcase()
print(v)
输出:ABCd
2.3.2.14、isidentifier
是否是标识符
标识符包含数字、字母、下划线(_)
且只能以字母或下划线开头
2.3.2.15、islower和isupper
islower:是否全部是小写字母
isupper:是否全部是大写字母
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "aBC"
s1 = "abc"
v = s.islower()
v1 = s1.islower()
print(v, v1)
输出:false true
2.3.2.16、isnumeric
是否是数字,这个可以识别汉字
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "二"
v = s.isnumeric()
print(v)
输出:true
2.3.2.17、isprintable
是否含有不可见的字符,如“\n”
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "abc"
s1 = "abc\t"
v = s.isprintable()
v1 = s1.isprintable()
print(v, v1)
输出:true false
2.3.2.18、isspace
判断字符串是否全部是空格
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "a b"
s1 = " "
v = s.isspace()
v1 = s1.isspace()
print(v, v1)
输出:false true
2.3.2.19、title
将字符串转换成标题,标题的特点是每个单词首字母大写
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "today is a good day"
v = s.title()
print(v)
输出:Today Is A Good Day
2.3.2.20、istitle
判断是否是标题
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "Today is a good day"
s1="Today Is A Good Day"
v = s.istitle()
v1 = s1.istitle()
print(v,v1)
输出:False True
2.3.2.21、join
将字符串中的每一个元素按照指定分隔符进行拼接
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "ab你是风儿我是沙"
t = "_"
v = t.join(s)
print(v)
输出:a_b_你_是_风_儿_我_是_沙
2.3.2.21、ljust和rjust
ljust:字符串靠左,右边填充指定字符使字符串达到要求宽度
rjust:字符串靠右,左边填充指定字符使字符串达到要求宽度
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test = "abc"
v = test.ljust(10, "*")
print(v)
v1 = test.rjust(10, "*")
print(v1)
输出:
abc*******
*******abc
2.3.2.22、zfill
只能 以0填充,不能指定字符
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test = "abc"
v=test.zfill(10)
print(v)
输出:0000000abc
2.3.2.23、lower和upper
lower:字符串全部转换成小写
upper: 字符串全部转换成大写
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test = "ABS"
v = test.lower()
print(v)
test = "abs"
v=test.upper()
print(v)
输出:
abs
ABS
2.3.2.24、strip和lstrip、rstrip
strip:去除字符串开头和结尾的指定字符、空白字符、\t、\n等转义字符
lstrip:去除字符串开头的指定字符、空白字符、\t、\n等转义字符
rstrip:去除字符串结尾的指定字符、空白字符、\t、\n等转义字符
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test = "ABcdeABB"
v = test.strip("AB") #字符串开头和结尾只要是A或B就删除
print(v)
test = "ABcdeABB"
v = test.lstrip("AB") #删除字符串开头A或B字符
print(v)
test = "ABcdeABB"
v = test.rstrip("AB") #删除字符串结尾的A或B字符
print(v)
输出:
cde
cdeABB
ABcde
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test = " ABC "
v = test.strip() #删除两边的空格
print("9"+v+"9")
test = " ABC "
v = test.lstrip() #删除左边的空格
print("9"+v+"9")
test = " ABC "
v = test.rstrip() #删除右边的空格
print("9"+v+"9")
输出结果:
9ABC9
9ABC 9
9 ABC9
#!/usr/bin/env python
# -*- coding:utf-8 -*-
test = "\t\nABC\t\n"
v = test.strip() #删除两边的\t\n
print("第一个输出:"+v+"9")
test = "\t\nABC\t\n"
v = test.lstrip() #删除左边的\t\n
print("第二个输出:"+v+"9")
test = "\t\nABC\t\n"
v = test.rstrip() #删除右边的\t\n
print("第三个输出:"+v+"9")
输出:
第一个输出:ABC9
第二个输出:ABC
9
第三个输出:
ABC9
2.3.2.25、maketrans和translate
这两个函数通常联合使用
maketrans:建立一个对应关系
translate:根据对应关系,替换字符串中的字符
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "abcdefghijk"
m = str.maketrans("aeg", "157") #建立对应关系
new_s = s.translate(m) #根据建立的对应关系,替换字符
print(new_s)
输出:1bcd5f7hijk
2.3.2.26、partition和rpartition
partition:从左边查找字符串中指定字符串,将其分三份
rpartition:从右边查找字符串中指定字符串,将其分三份
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="abscdefsgh"
v=s.partition("s") #
print(v)
v=s.rpartition("s")
print(v)
输出:
(‘ab’, ‘s’, ‘cdefsgh’)
(‘abscdef’, ‘s’, ‘gh’)
2.3.2.27、split和rsplit
split:从左边开始分隔字符,不指定次数默认全分隔
rsplit:从右边开始分隔字符,不指定次数默认全分隔
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="abcsdefsefgs"
v=s.split("s")
print(v)
输出:[‘abc’, ‘def’, ‘efg’, ‘’]
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="abcsdefsefgs"
v=s.split("s",2) #分隔两次
print(v)
2.3.2.28、splitlines
按换行符分隔
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="abc\ndef\nghi\njkl"
v=s.splitlines() #默认不保留换行符
print(v)
v=s.splitlines(False) #不保留换行符
print(v)
v=s.splitlines(True) #保留换行符
print(v)
输出:
[‘abc’, ‘def’, ‘ghi’, ‘jkl’]
[‘abc’, ‘def’, ‘ghi’, ‘jkl’]
[‘abc\n’, ‘def\n’, ‘ghi\n’, ‘jkl’]
2.3.2.29、startswith和endswith
startswith:是否以指定字符串开头
endswith:是否以指定字符串结尾
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="abcdef"
v=s.startswith("ab") #是否以ab开头
print(v)
v=s.endswith("ef") #是否以ef结尾
print(v)
输出:
True
True
2.3.2.30、swapcase
字符串中的大写变成小写,小写变成大写
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="AbCdE"
v=s.swapcase()
print(v)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="abcdefabcdef"
v=s.replace("ab","xx") #替换所有的
print(v)
v=s.replace("ab","xx",1) #只替换第一个
print(v)
输出:
xxcdefxxcdef
xxcdefabcdef
2.3.2.32、以下6个使用频率超高
join
split
find
strip
upper
lower
replace
2.3.2.33、获取字符串中的某个字符
索引
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "abcd"
v = s[0]
print(v)
v = s[0:2] #取从第0个开始,小于2的字符
print(v)
v = s[0:-1] #切片,切成abc和d
print(v)
输出:
a
ab
abc
2.3.2.34、len
2.3.2.34.1、len获取当前字符串中字符数
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "abc"
v=len(s) #v=3
print(v)
s = "中国"
v=len(s) #v=2
print(v)
输出:
3
2
以上输出结果是python3的结果
len("中国") #python2.7这个值为6
2.3.2.34.2、用len计算列表的长度
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[11,22,33] #这个列表有3个元素
v=len(s)
print(v)
输出:
3
2.3.2.35、将字符串中的字符逐个输出
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s="中华人民共和国万岁"
for item in s:
print(item)
输出:
中
华
人
民
共
和
国
万
岁
2.3.2.36、range
1、创建连续的数字
#!/usr/bin/env python
# -*- coding:utf-8 -*-
v=range(100) #0≤v<99
print(v)
输出:range(0, 100)
以上输出是python3的一个优化,python2.7中会立即输出大于等于0且小于100的所有数,如果第二个参数比较大,对于内存来说可能是个灾难
2、上例中的v中有在for循环中调用时才会显示
#!/usr/bin/env python
# -*- coding:utf-8 -*-
v=range(100)
for item in v:
print(item,end=" ") #第二个参数表示:默认输出时不换行,而是用" "替换"\n"
输出:0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99
3、步进
#!/usr/bin/env python
# -*- coding:utf-8 -*-
v=range(0,100,5)
for item in v:
print(item,end=" ")
输出:0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80 85 90 95
2.3.2.37、字符串一旦创建不可修改
字符串一旦创建不可修改
一旦修改或者拼接,都会造成重新生成字符串
所有的编程语言都是这样处理的
2.3.2.38、输入一个字符串,输出其索引和字符
# -*- coding:utf-8 -*-
s=input(">>>" )
for item in(range(0,len(s))):
print(item,end=" ")
print(s[item])
输入:abcde
输出:
0 a
1 b
2 c
3 d
4 e
2.4、列表(list)
2.4.1、列表格式
1、中括号括起来
2、用,分割每个元素
[1, 2, [11,22,"33"], False,"aa"]
2.4.2、列表中可以嵌套任何类型
列表中的元素可以是数字,字符串,列表,布尔值… …所有的都能放
集合,内部放置任何东西
[1, 2, [11,22,"33"], False,"aa"]
2.4.3、索引取值
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11,22,"33"], False,"aa"]
print(s[3])
输出:False
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11, 22, "35"], False,"aa"]
v= s[2][2][1]
print(v)
输出:5
2.4.4、切片取值
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11,22,"33"], False,"aa"]
print(s[3:4])
输出:False
2.4.5、for循环
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11,22,"33"], False,"aa"]
for item in s:
print(item)
输出:
1
2
[11, 22, ‘33’]
False
aa
2.4.5、while循环
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11,22,"33"], False,"aa"]
i = 0
length = len(s)
while i < length:
print(s[i])
i += 1
输出:
1
2
[11, 22, ‘33’]
False
aa
2.4.6、索引修改
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11,22,"33"], False,"aa"]
s[2] = True
print(s)
输出:
[1, 2, True, False, ‘aa’]
2.4.7、切片修改
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11, 22, "33"], False,"aa"]
s[1:2]=[11,22] #索引为1且索引小于2,即s[1],
#1个元素却改成了两个值,这里相当于又多加了一个值
#如果我想将这个元素改成列表呢?用索引修改可以实现
#这句代码写成s[1:2]=11,22效果是一样的
#如果切片取的是两个值,只赋一个值会报错
print(s)
输出:
[1, 11, 22, [11, 22, ‘33’], False, ‘aa’]
2.4.8、索引删除
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11, 22, "33"], False,"aa"]
del s[2]
print(s)
输出:
[1, 2, False, ‘aa’]
2.4.9、切片删除
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11, 22, "33"], False,"aa"]
del s[2:4]
print(s)
输出:
[1, 2, ‘aa’][1, 2, ‘aa’]
2.4.10、in操作
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s=[1, 2, [11, 22, "33"], False,"aa"]
v="aa" in s
print(v)
输出:
True
2.4.11、字符串转换成列表
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = "abcdefghijk"
v=list(s)
print(v)
输出:
[‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘g’, ‘h’, ‘i’, ‘j’, ‘k’]
2.4.12、列表中所有的元素拼后转换成字符串
第一种情况:列表里有数字有字符串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = [11,22,"aa","BB"]
v=""
for iteam in s:
v += str(iteam)
print(v)
输出:1122aaBB
第二种情况:列表里全部是字符串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = ["aa","bb"]
v="".join(s)
print(v)
输出:
aabb
2.4.13、append
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = ["aa","bb"]
v=s.append(5) #append没的逶回值
print(v) #打印出来是None
print(s)
输出:
None
[‘aa’, ‘bb’, 5]
2.4.13、clear
清空列表
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = ["aa","bb"]
s.clear()
print(s)
输出:
[]
2.4.14、copy
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = ["aa","bb"]
v=s.copy() #有返回值,浅拷贝
print(s)
print(v)
输出:
[‘aa’, ‘bb’]
[‘aa’, ‘bb’]
2.4.15、count
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = ["aa","bb",11,11]
v=s.count(11) #统计列表中有多少个为11的元素
print(v)
输出:
2
2.4.16、extend
def extend(self, iterable)
iterable:必须是可迭代的
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = [11, 22, 33, 44]
v=[55,66]
s.extend(v)
print(s)
输出:[11, 22, 33, 44, 55, 66]
字符串也是可迭代的,也可以跟一个字符串
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = [11, 22, 33, 44]
s.extend("567")
print(s)
输出:
[11, 22, 33, 44, ‘5’, ‘6’, ‘7’]
2.4.16、 index
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = [11, 22, 11, 44,11]
v=s.index(22)
print(v)
v=s.index(11) #从前往后找只找第一个
print(v)
v=s.index(11,3) #从前往后找,从索引为3处开始找
print(v)
v=s.index(11,3,5) #从前往后找,从索引为3处开始找,到5结束(不包括5,最后一个参数写4会报错)
print(v)
输出:
1
0
4
4
2.4.17、 insert
指定索引处插值
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = [11, 22, 33]
s.insert(0,99)
print(s)
输出:
[99, 11, 22, 33]
2.4.18、pop
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = [11, 22, 33]
v=s.pop() #默认删除最后一个值,并返回删除的这个值
print(v)
print(s)
s = [11, 22, 33]
v=s.pop(1) #删除指定索引为1的值,并返回删除的这个值
print(v)
print(s)
输出:
33
[11, 22]
22
[11, 33]
2.4.19、remove
删除列表中指定元素
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = [11, 22, 33,22]
s.remove(22) #从左删,只删除第一个
print(s)
输出:
[11, 33, 22]
2.4.20、删除方法总结
pop
remove
del索引删除
del切片删除
clear
2.4.21、reverse
列表顺序反转
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = [11, 22, 33]
s.reverse()
print(s)
输出:
[33, 22, 11]
2.4.2、sort
排序
#!/usr/bin/env python
# -*- coding:utf-8 -*-
s = [11, 22,44,22, 33]
s.sort()
print(s) #默认reverse=False,升序
s.sort(reverse=False)
print(s)
s.sort(reverse=True)
print(s)
输出:
[11, 22, 22, 33, 44]
[11, 22, 22, 33, 44]
[44, 33, 22, 22, 11]