1、
要求:
1.初始化start_day,end_day两个日期
from datetime import datetime
start_day=datetime(2019,4,1)
end_day=datetime(2019,4,30)
其它时间数据生成要用datetime或date模块的方法编程实现
2.不能使用calendar模块生成
from datetime import datetime from datetime import timedelta from datetime import * start_day = datetime(2019, 4, 1) end_day = datetime(2019, 4, 30) days = end_day - start_day month = start_day.month week = start_day.weekday() day = days.days + 1 count = 0 i = 0 print(" 2019年4月") l = ("星期一", " 星期二", " 星期三", " 星期四", " 星期五", " 星期六", " 星期日""\n") for n in l: print(format(n, "4"), end=" ") while i <= week: i += 1 print("\t\t", end="") count += 1 if (count % 7 == 0): print("\n") p = 1 while p <= day: print(p, "\t\t", end="") p += 1 count += 1 if (count % 7 == 0): print("\n")
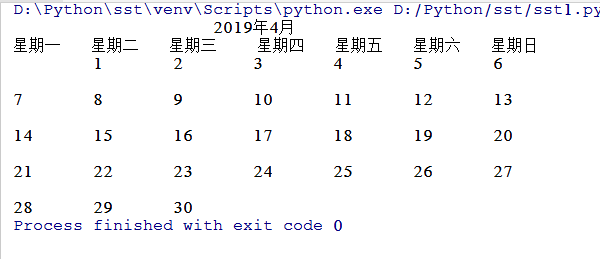
2、
1.参考“三国演义”词频统计程序,实现对红楼梦出场人物的频次统计。
import jieba excludes = {"怎么","快去","什么","一个","我们","那里","什么","东西","听见","老爷","丫头","两个","这个","就是", "平儿","众人","那里","心里","这里","太太","回来","只是","大家","只得","这些","王夫人","如此","银子","罢了", "今儿","屋里","外头","打发","还有","这话","自然","说话","一回","那边","那些","听说","知道","姑娘","这里","出来","他们","众人","这些", "不敢","出去","所以","二人","自然","今儿","罢了","还有","屋里","如此","那些","听说","小丫头","邢夫人","如何","问道","看见","紫鹃","妹妹" ,"人家","不用","媳妇","香菱","原来","一声","一面","今儿","自己","这么","这个","别处","东西","好看","舍得","远远","那里","这里","各自","一边", "咱们","回来","不能","天天"} txt = open(r"D:\Python\sst\venv\红楼梦.txt", "r", encoding='utf-8').read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue elif word == "宝玉" or word == "二爷" or word == "怡红公子" or word == "富贵闲人" or word == "无事忙" or word == "宝哥哥" \ or word == "宝兄弟" or word == "宝叔叔" or word == "混世魔王" or word == "绛洞花王" or word == "浊玉" \ or word == "遮天大王" or word == "槛内人" : rword = "贾宝玉" elif word == "林黛玉" or word == "黛玉道" or word == "林妹妹"or word=="潇湘妃子": rword = "林黛玉" elif word == "宝钗" or word == "蘅芜君" or word == "宝姐姐" or word == "宝丫头" or word == "宝姑娘": rword = "薛宝钗" elif word == "凤姐" or word == "琏二奶奶" or word == "凤辣子" or word == "凤哥儿" or word == "凤丫头" or word == "凤姐儿"or word == "熙凤道": rword = "王熙凤" elif word == "贾母" or word == "老太太": rword = "贾母" elif word == "四姑娘" or word == "四丫头": rword = "贾惜春" elif word == "秦可卿" or word == "可卿": rword = "可卿" elif word == "贾探春" or word == "探春": rword = "探春" else: rword = word counts[rword] = counts.get(rword,0) + 1 for word in excludes: del(counts[word]) items = list(counts.items()) items.sort(key=lambda a:a[1], reverse=True) for i in range(7): word, count = items[i] print ("{0:<10}{1:>5}".format(word, count))
