1.安装pytesseract库
pytesseract是Tesseract关于Python的接口,在cmd中可以直接使用pip install pytesseract安装
2.用电脑下载安装tesseract
下载地址 http://digi.bib.unimannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
一直点确定后完成安装,并配置环境变量

在CMD中输入tesseract -v, 如显示以下界面,则表示Tesseract安装完成且添加到系统变量

3.下载tesseract的简体中文语言包
下载地址为:https://github.com/tesseract-ocr/tessdata/find/master/chi_sim.traineddata ,再将chi_sim.traineddata放在C:\Program Files (x86)\Tesseract-OCR\tessdata目录下。

做好准备工作就可以实现OCR文字识别
import cv2 import pytesseract from PIL import Image img = Image.open('0.jpg') pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe' text = pytesseract.image_to_string(img,lang='chi_sim') print(text)
0.jpg 如下:
运行结果如下:
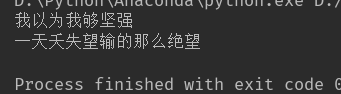
利用Ocr 能不能识别简单的验证码
为了更好的处理图片,可以将图片转为灰度图片,再去掉黑点,进行二值化降噪,
代码如下:
import cv2 import pytesseract from PIL import Image, ImageEnhance, ImageFilter # 旧版本识别 img = Image.open('6.png') pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe' text = pytesseract.image_to_string(img, lang='chi_sim') print(text) print("=" * 120) # 新版本识别 img_gray = img.convert('L') # 将图片变成灰色 img_gray.save('ode_gray.png') img_black_white = img_gray.point(lambda x: 0 if x > 200 else 255) # 转成黑白图片 pic1 = 'code_black_white.png' img_black_white.save(pic1) # 要去掉黑点,就是一个二值化降噪的过程。可以用PIL(Python Image Library) im = Image.open(pic1) im = im.filter(ImageFilter.MedianFilter()) enhancer = ImageEnhance.Contrast(im) im = enhancer.enhance(2) im = im.convert('1') im.save('jiangzao.png') im.show() # 图片弹框展示出来 # text = pytesseract.image_to_string(Image.open('jiangzao.png'),lang='chi_sim')##,lang='eng 数字 text = pytesseract.image_to_string(im, lang='chi_sim') print(text)
运行结果如下,成功!