【什么是HA】
HA的英文是High Availability,高可用性。从字面上的意思就是一种让服务中断尽可能少的技术。VMware的HA和微软的MSCS(Win2008以后改称Failover Clustering)类似,都是将多台主机组建成一个故障转移集群(Cluster),运行在集群上的服务(或VM)不会因为单台主机的故障而停止。
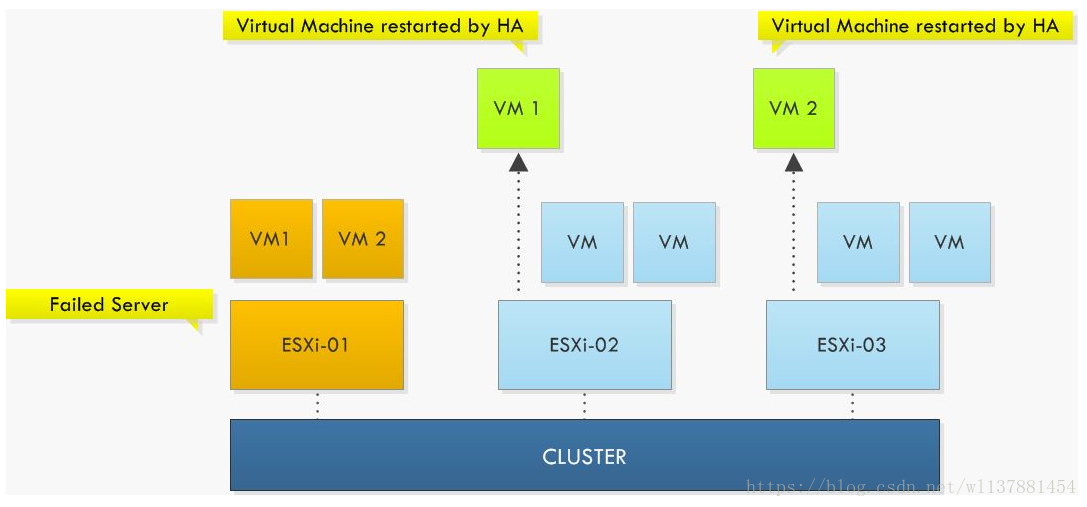
用一个图来简单说明HA的工作原理:图中橙色的主机ESXi01宕机了,其上的2台虚拟机VM1和VM2就根据HA的调度被ESXi-02和ESXi-03这2台主机接管,并重启运行起来。
但是要注意的是,HA(无论是VMware的HA还是MSCS)不是通常意义上的完全不中断服务的高可用性,HA只是一种自动的故障切换机制,当某一主机发生故障时,服务或VM(就配置了MSCS的Hyper-V来看,VM其实也被看作是一个服务)自动到另外的可用的主机上重启。这其实是一个中断然后重启的过程。就VM来说,看上去就好像是一台服务器突然被拔掉了电源线,然后又重新加电开机。这个故障然后重启的过程其实是比较长的,根据不同的VM而不同,少则1-2分钟,多的则可能达到5-6分钟。如果运行在一台缺乏资源的的主机上,这个时间可能更长。
【创建HA的前提】
一个通用的HA的集群通常有这么几个必要的条件组成:
- 2台或者更多台主机
- 这些主机共享一个外部存储
- VM是运行在共享存储上的
- 主机上至少有2个以上的网卡,其中一个需要负责传递“心跳”信号。
此外,要成功配置VMware HA,还必须具备这么几个必要条件:- 必须有vCenter Server(虽然没有vCenter HA也能发挥作用,但是创建Cluster的时候必须有vCenter的参与)
- 所有Host都必须有相同的vSwitch配置
特别要注意的是,对于ESX 4.x或之前版本,DNS是建立HA必要前提,所有Host都必须能够正确的解析其他node的DNS名字,将主机加入到一个集群也必须用其FQDN名。但是从vSphere 5开始,这已经不是必要的了,IP地址被直接用作HA集群的通信,这样减少了HA的依赖性,加快了HA的响应速度。
但是,因为VMware vSphere 5的其他一些服务和组件仍然需要DNS,使用FQDN虽然仍然是推荐做法。
【HA的组成部分】
vSphere 5的HA的组件有以下三个:
- FDM
- hostd
- vCenter
FDM是Fault Domain Manager的缩写,它的前身在ESX4叫作AAM,是用来管理HA的最重要的一个组件。它负责cluster的心跳、主机之间的通信,和vCenter的通信、协调虚拟机的位置、调度虚拟机的重启、记录日志等等。

hostd负责监控直接和虚拟机打交道,例如让虚拟机开机、监控虚拟机的状态等。FDM需要hostd的帮助来完成对虚拟机的操作(例如开机)。简而言之,FDM依赖hostd,如果hostd失效了,FDM也会暂停工作。
vCenter是企业中虚拟架构的集中管理平台,HA虽然不依赖它运转,但是在组建HA cluster的时候必须通过vCenter来发起。它的主要作用是,在主机上安装HA的Agent(指FDM和hostd agent),在Cluster配置更改的时候通知各主机。
【Master和Slave】
ESX4的时候,节点分成Primary和Secondary,最先加入cluster的5个节点成为Primary,并各自存有一份AAM Database。
vSphere 5对此进行了简化。现在不再有Primary和Secondary的概念了,取而代之的是Master和Slave。一个Cluster中只有一台Master,其余都是Slave。
Master的作用是管理整个集群,作为集群的主要管理者,它监控虚拟机的运行状态,判断某一个主机是否宕机,它监控每个VM的位置,并判断VM是否需要在其他主机上重启。对于一个集群来说,Master是其上所有虚拟机的“主人”。
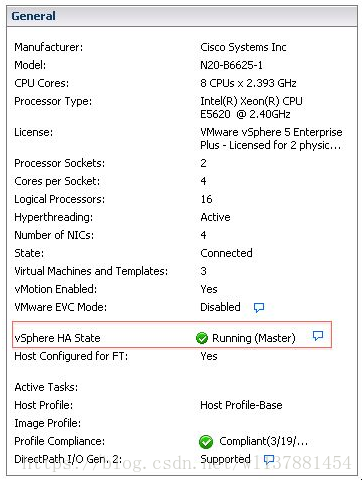
在哪里可以看出主机是否Master?参见下图
没有Master的集群就会群龙无首,群龙无首的集群就fail了。
当Master失效时怎么办?集群不能没有Master,因此Master的选举会马上被触发。

【Master的选举】
选举会在以下情况被触发:
- HA创建时;
- Master宕机;
- Master处于isolated或者集群出现了partitioned状态;
- Master被置于维护状态或Standby状态;
- 集群被重新配置时;
- Master和vCenter失去了联系;
选举需要15秒时间。选举通过UDP协议(端口8182)进行。
选举的规则是:拥有最多的datastore的主机当选。如果主机拥有的datastore一样多,那么Managed Objective ID号最大的那台主机当选。
(注:这里的最大不是数值最大,而是从左向右比较依次比较每一位上的数字的大小,例如99就比100大,因为第一位的数字首先比较,9大于1)
【Master伸张其主权】
当选后,新的master会伸张其主人的权力,试图接管所有datastore。
Q: 如何接管?(或者说怎样才算接管了datastore)
A: 通过锁定(lock)一个文件的方式,这个文件存在每个datastore上,名字叫“protectedlist”
该文件的位置是:
//.vSphere-HA//protectedlist
这个文件里面存放的是受HA保护的VM列表。
若Master坏掉,则其lock会过期,新当选的master就可以接管这个文件,并重新上锁。
Master还负责监控Slave的状态,如果发现slave不响应其心跳,则会判断是否要重启slave上的虚拟机。
Slave之间是不相互通信的,除了选举Master的时候。
(注:以上内容均来自于http://blog.51cto.com/delxu/717516,个人觉得写得不错,方便自己记忆和学习)