1. Unity Shader的内置变量(数学篇)
使用Unity写shader的一个好处在于,它提供了很多内置参数,这使得我们不在需要自己手动算一些值。本文给出Unity内置的用于空间变换和摄像机以及屏幕参数的内置变量。这些内置变量可以在UnityShaderVariables.cginc文件中找到定义和说明。
1.1 变换矩阵
首先是用于坐标空间变换的矩阵。表中给出了Unity5.2版本提供的所有内置变换矩阵。下面的所有矩阵都是float4×4类型的。

上表给出了这些矩阵的常用用法。但读者可以根据需求达到不同目的,例如我们可以提取坐标空间的坐标轴。
其中有一个矩阵比较特殊,即UNITY_MATRIX_T_MV矩阵。很多对数学不了解的读者不理解这个矩阵有什么用处?我们应该知道一种非常吸引人的矩阵类型——正交矩阵。对于正交矩阵来说,它的逆矩阵就是转置矩阵。因此如果说UNITY_MATRIX_MV是一个正交矩阵的话,那么UNITY_MATRIX_T_MV就是它的逆矩阵,也即是说,我们可以使用UNITY_MATRIX_T_MV把顶点和方向矢量从观察空间变换到模型空间。那么问题是,UNITY_MATRIX_MV什么时候是一个正交矩阵呢?总结一下,如果我们只考虑旋转、平移、缩放这3种类型变换的话,如果一个模型只包括旋转,那么UNITY_MATRIX_MV就是一个正交矩阵。这个条件似乎有些苛刻,我们可以把条件在放宽一些,如果只包括旋转和统一缩放(假设缩放系数是k),那么UNITY_MATRIX_MV就几乎是一个正交矩阵了。为什么是几乎呢?因为统一缩放可能会导致每一行(或每一列)的矢量长度不为1,而是k,这不符合正交矩阵的特性,但我们可以通过除以这个统一缩放系数,来把它变成正交矩阵,在这种情况下,UNITY_MATRIX_MV的逆矩阵就是
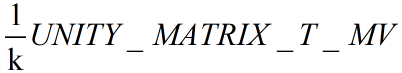
而且,如果我们只是对方向矢量进行变换的话,条件可以放的更宽,即不用考虑有没有平移变换,因为平移对方向矢量没有影响。因此我们可以截取UNITY_MATRIX_IT_MV矩阵的前3行前3列来吧方向矢量从观察空间变换到模型空间(前提是只存在旋转变换和统一缩放)。对于方向矢量,我们可以在使用前对它们进行归一化处理,来消除统一缩放的影响。
还有一个矩阵要说明一下,那就是UNITY_MATRIX_IT_MV矩阵,我们在前面已经知道,法线的变换需要使用原变换矩阵的逆矩阵。因此UNITY_MATRIX_IT_MV可以把法线从模型空间变换到观察空间。但只要我们做一点手脚,它也可以用于直接得到UNITY_MATRIX_MV的逆矩阵——我们只需要对它进行转置就可以了。因此为了把顶点或方向矢量从观察空间变换到模型空间,我们可以使用类似下面的代码:
//方法一:使用transpose函数对UNITY_MATRIX_IT_MV进行计算
//得到UNITY_MATRIX_MV的逆矩阵,然后进行列矩阵乘法,
//把观察空间中的点或方向矢量变换到模型空间中
float4 modelPos = mul(transpose(UNITY_MATRIX_IT_MV),viewPos);
//方法二:不直接使用转置函数transpose,而是交换mul参数的位置,使用行矩阵乘法
//本质和方法一是完全一样的
float 4 modelPos = mul(viewPos, UNITY_MATRIX_IT_MV)关于mul函数参数位置导致的不同,我们在后面继续讲到。
1.2 摄像机和屏幕参数
Unity提供了一些内置变量来让我们访问当前正在渲染的摄像机的参数信息。这些参数对应摄像机上的Camera组件的属性值,下表给出了Unity5.2版本提供的这些变量。

2. 答疑解惑
2.1 使用3×3还是4×4的变换矩阵
对于线性变换(如旋转和缩放)来说,仅使用3×3的矩阵就足够表示所有的变换了。但如果存在平移变换,我们就需要使用4×4的变换矩阵。因为在对顶点的变换中,我们通常使用4×4变换矩阵。当然,在变换前我们需要把点坐标转换成齐次坐标表示,即把点的w分量设为1。而在对方向矢量的变换中,我们通常使用3×3矩阵就够了,这是因为平移变换对方向矢量是没有影响的。
2.2 Cg中的矢量和矩阵类型
我们通常在Unity Shader中使用Cg作为着色器编程语言。在Cg中变量类型有很多种,但现在我们是想解释如何用这些类型进行数学运算。因此,我们只是用float家族的变量来做说明。
在Cg中,矩阵类型是由float3×3、float4×4等关键词进行声明和定义的。而对于float3、float4等类型的变量,我们既可以把它当成一个矢量,也可以把它当成是一个1×n的行矩阵或一个n×1的列矩阵。这取决于运算的种类和它们在运算中的位置。例如当我们进行点积操作时,两个操作数就被当成矢量类型,如下:
float4 a = float4(1.0,2.0,3.0,4.0)
float4 b = float4(1.0,2.0,3.0,4.0)
//对两个矢量进行点积操作
float result = dot(a,b)在进行矩阵乘法时,参数的位置将决定是按列矩阵还是行矩阵进行乘法。在Cg中,矩阵乘法是通过mul函数实现的。例如:
float4 v = float4(1.0,2.0,3.0,4.0)
float4×4 M = float4×4(1.0,0.0,0.0,0.0,
0.0,2.0,0.0,0.0,
0.0,0.0,3.0,0.0
0.0,0.0,0.0,4.0);
// 把v当成列矩阵和矩阵M进行右乘
float4 column_mul_result = mul(M,v);
//把v当成行矩阵和矩阵M进行左乘
float4 row_mul_result = mul(v,M);
//注意:column_mul_result不等于row_mul_result,而是:
//mul(M,v) == mul(v,tranpose(M))
//mul(v,M) == mul(tranpose(M),v)因此参数的位置会直接影响结果值。通常在变换顶点时,我们都是使用右乘的方式来按列矩阵进行乘法。这是因为,Unity提供的内置矩阵(如UNITY_MATRIX_MVP等)都是按列存储的,但有时,我们也会使用左乘的方式,这是因为可以省去对矩阵转置的操作。
但要注意的一点是,Cg对矩阵类型中元素的初始化和访问顺序。在Cg中,对float4×4等类型的变量是按行优先的方式进行填充的。什么意思呢?我们知道要填充一个矩阵需要给定一串数字,例如要声明一个3×4矩阵,我们需要提供12个数字。那么这一串矩阵是一行一行地填充矩阵还是一列一列地填充矩阵呢?这两种方式得到的矩阵是不同的。例如我们使用(1,2,3,4,5,6,7,8,9)去填充一个3×3矩阵,如果是按行优先的方式,得到的矩阵是:
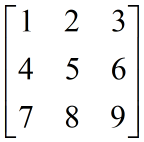
如果是按照列优先的方式,得到的矩阵是:
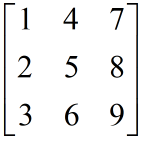
Cg使用的是行优先的方法,既是一行一行的填充矩阵的。因此,如果读者需要自己定义一个矩阵时(例如,自己构建用于空间变换的矩阵),就要注意这里的初始化方式。
类似地,当我们在Cg中访问一个矩阵中的元素时,也是按行来索引的。例如:
// 按行优先的方式初始化矩阵M
float3×3 M = float3×3(1.0,2.0,3.0,
4.0,5.0,6.0,
7.0,8.0,9.0);
//得到M的第一行,即(1.0,2.0,3.0)
float3 row = M[0];
// 得到M的第二行第一列的元素,即4.0
float ele = M[1][0]之所以Unity Shader中的矩阵满足上述规则,是因为使用的是Cg语言。换句话说,上面的特性都是Cg的规定。
如果读者熟悉Unity的API,可能知道Unity在脚本中提供了一种矩阵类型——Matrix4×4。脚本中这个矩阵的类型则是采用列优先的方式。这与Unity Shader中的规定不一样,希望读者在遇到时不会困惑。
2.3 Unity中的屏幕坐标:ComputeScreenPos/VPOS/WPOS
我们在以前讲了屏幕空间的转换细节。在写shader的过程中,我们有时候希望能够获得片元在屏幕上的像素位置。
在顶点/片元着色器中,有两种方式来获得片元的屏幕坐标。
一种是在片元着色器的输入中声明VPOS或WPOS语义(什么是语义,我们后面会慢慢说)。VPOS是HLSL中对屏幕坐标的语义,而WPOS是Cg中对屏幕坐标的语义。两者UnityShader中是等价的。我们可以在HLSL/Cg中通过语义的方式来定义顶点/片元着色器的默认输入,而不需要在自己定义输入输出的数据结构。这里的内容有一些超前,因为我们还没有具体的讲解到顶点/片元着色器的写法,读者在这里可以只关注VPOS和WPOS的语义。使用这种方法,可以在片元着色器中这样写:
fixed4 frag(float4 sp: VPOS): SV_Target{
//用屏幕坐标除以屏幕分辨率_ScreenParams.xy,得到视口空间中的坐标
return fixed4(sp.xy/_ScreenParams.xy,0.0,1.0);
}得到的效果如下图所示:

VPOS/WPOS语义定义的输入是一个float4类型的变量。我们已经知道了它的xy值代表了在屏幕空间中的像素坐标。如果屏幕分辨率是400×300,那么x的范围就是[0.5,400.5],y的范围是[0.5,300.5]。注意这里的像素坐标并不是整数值,这是因为OpenGL和DirectX10以后的版本认为像素的中心对应的是浮点值中的0.5。那么它的zw分量是什么呢?在Unity中,VPOS/WPOS的z分量范围是[0,1],在摄像机的近裁剪平面处,z的值是0,在远裁剪平面处,z的值是1。对于w分量,我们需要考虑摄像机的投影类型。如果使用的是透视投影,那么w分量的范围是
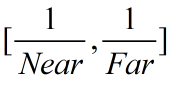
Near和Far对应了在Camera组件中设置的近裁剪平面和远裁剪平面距离摄像机的远近;如果使用的是正交投影,那么w的值恒为1。这些值是通过对经过投影矩阵变换后的w分量取倒数得到的。在代码的最后,我们把屏幕空间除以分标率来得到视口空间(viewport space)中的坐标。视口坐标很简单,就是把屏幕坐标归一化,这样屏幕左下角就是(0.0,0.0),右上角就是(1,1)。如果已知屏幕坐标的话,我们只需把xy值除以屏幕分辨率即可。
另一种方式是通过Unity提供的ComputeScreenPos函数。这个函数在UnityCG.cginc里被定义。通常的用法需要两个步骤,首先在顶点着色器中将ComputeScreenPos的结果保存在输出结构体中,然后在片元着色器中进行一个齐次除法运算后得到视口空间下的坐标。例如:
struct vertOut{
float4 pos:SV_POSITION;
float4 scrPos:TEXCOORD0;
};
vertOut vert(appdata_base v){
vertOut o;
o.pos = mul (UNITY_MATRIX_MVP, v.vertex);
//第一步:把ComputeScreenPos的结果保存到scrPos中
o.scrPos = ComputeScreenPos(o.pos);
return o;
}
fixed4 frag(vertOut i):SV_Target{
//第二步:用scrPos.xy除以scrPos.w得到视口空间中的坐标
float2 wcoord = (i.scrPos.xy/i.scrPos.w);
return fixed4(wcoord, 0.0,1.0);
}上面的代码实现效果与上图一样。我们现在来看看这种方式的实现细节。这种方法实际上是手动实现了屏幕映射的过程,而且它得到的坐标直接就是视口空间中的坐标。我们在一起前已经看到了如何将裁剪坐标空间的点映射到屏幕坐标中。据此,我们可以得到视口空间的坐标,公式如下:
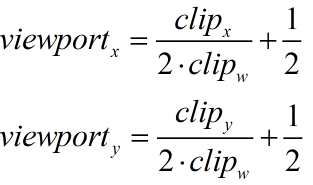
上面公式的思想就是,首先对裁剪空间下的坐标进行齐次除法,得到范围在[-1,1]的NDC,然后再将其映射到范围在[0,1]的视口空间下的坐标。那么ComputeScreenPos究竟是如何做到的呢?我们可以在UnityCG.cdnic文件中找到ComputeScreenPos函数的定义,如下:
inline float4 ComputeScreenPos (float4 pos){
float4 o = pos * 0.5f;
# if defined(UNITY_HALF_TEXEL_OFFSET)
o.xy = float(o.x,o.y*_ProjectionParams.x)+o.w*_ScreenParams.zw;
# else
o.xy = float(o.x,o.y*_ProjectionParams.x)+o.w;
# endif
o.zw = pos.zw;
return o;
}ComputeScreenPos 的输入参数pos是经过MVP矩阵变换后在裁剪空间中的顶点坐标。UNITY_HALF_TEXEL_OFFSET是Unity在某些DirectX平台上使用的宏,在这里我们可以忽略它。这样我们可以只关注#else部分。_ProjectionParams.x在默认情况下是1(如果我们使用了一个反转的投影矩阵的话就是-1,但这种情况很少见)。那么上述代码的过程实际是输出了:
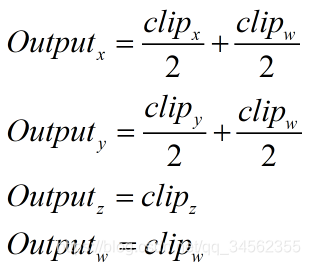
可以看出,这里的xy并不是真正的视口空间下的坐标。因此我们在片元着色器中再进行一步处理,即除以裁剪坐标的w分量。至此,完成整个映射过程。因此虽然ComputeScreenPos的函数名字似乎意味着会直接得到屏幕空间的位置,但并不是这样的,我们仍需在片元着色器中除以它的w分量来得到真正的视口空间的位置。那么为什么Unity不直接在ComputeScreenPos中为我们进行除以w分量这个步骤呢?为什么还需要我们进行这个除法?这是因为,如果Unity在顶点着色器中这么做的话,就会破坏插值结果。我们知道,从顶点着色器到片元着色器的过程实际会有一个插值的过程。如果不在顶点着色器中进行这个除法,保留x,y和w分量,那么它们在插值后再进行这个除法,得到的x/w和y/w就是正确的(我们可以认为是除法抵消了插值的影响)。但是如果我们直接在顶点着色器中进行这个除法,那么就需要对x/w和y/w直接进行插值,这样得到结果就会不准确。原因是,我们不可以在投影空间中进行插值,因为这并不是一个线性空间,而插值往往是线性的。
经过除法操作后,我们就可以得到该片元在视口空间的坐标了,也就是一个xy范围都在[0,1]之间的值。那么它的zw值是什么呢?可以看出,我们在顶点着色器中直接把裁剪空间的zw值存进了输出结构体中,因此片元着色器输入的就是这些插值后的裁剪空间中的zw值。这意味着如果使用的是透视投影,那么z值的范围是[-Near,Far],w值得范围是[Near,Far];如果使用的是正交投影,那么z值得范围是[-1,1],而w值恒为1。