1、实现Base64编码
在python 内部,提供了base4 的编码功能,导入即可使用
import base64
base64.b64encode(b'abc')
>>>b'YWJj'
但是,如果自己编写一个base64的编码又该如何实现呢?
先复习下字节的知识
字节的移位操作:
i = 0b01100001
i,hex(i)
>>>(97, '0x61')
i >>2 ,i//4 # 字节向右移两位后,相当于整除4.
>>>24 , 24
# 右移的实质是将字节的末尾去掉两位
字节的与操作
0b011000010110 &0x3F# 0x3F --->0x3F='0b000000111111' 进行与操作,只留下相同部分
>>>22 ('0b10110')
# 相当于取后六位
字节转化------大端模式
int.from_bytes(bytes, byteorder, *, signed=False) -> int #至少传两个参数 (bytes ,大小端)
x= int.from_bytes(b'abc','little')
Y= int.from_bytes(b'abc','big')
print(x,hex(x))
print(Y,hex(Y))
>>>6513249 0x636261#返回的是 一个大端模式的整数模式
6382179 0x616263#注意大端模式与小端模式的区别,不能使用错误
现在在来学习下base64 编码的原理
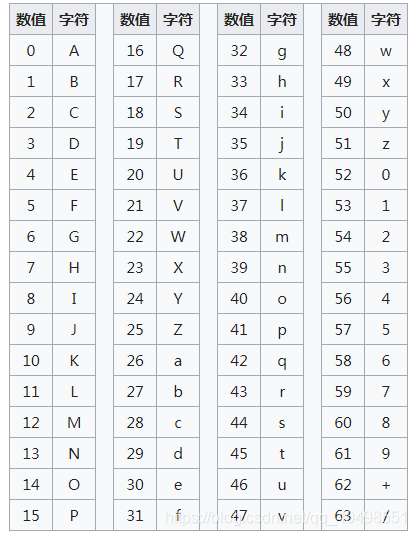
base64 编码就是将ASCII 编码中3x8的24位转化为4x6位的字节,在转化成索引去已知编码表查找对应的字符.
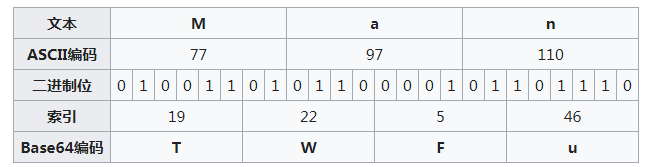
编码过程中如果ASCII的字符数小于三时,则就在此字符后面补ASCII字节中的真正的0(非数字’0’),凑齐24位
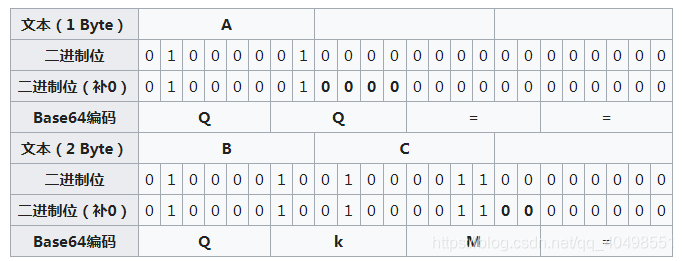
上面的尾部补了多于的0,这样在索引base64编码表时,最一几位会多出不是原本待编码的字符,这里,上面补了几个0,末尾就会出现几个多余的字符’A’,所以需要将其替换,用"="将其替换.
好了,掌握了字节部分的基础知识与base64编码的基本原理,下面我们就可以进行base 64编码了
alphabet=b'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmopqrstuvwxyz0123456789\+'
def b64encode(src:str):
ret = bytearray() # bytes是不可改变的,所以只能使用bytearray
if isinstance(src,str):
_src = src.encode()
else:
return
length = len(_src)
offset = 0
for offset in range(0,length,3):
triple = _src[offset:offset+3]
print(triple)
r =3-len(triple)
if r:
triple+=b'\x00'*r # 尾部不足3个字节的,补ASCII码的0
#此时一定会有三个字节了
x = int.from_bytes(triple,'big') # 字节的移位需要int格式才能进行,大端模式
for i in range(18,-1,-6):
index =x >> i if i ==18 else x >>i & 0x3F
ret.append(alphabet[index])
# for i in range(r): 尾部的"="替换
# ret[-i-1]=61 # bytearray的替换使用的是整型,不能使用b'='进行替换
# # ret[-i-1]=b'=' # 是错误的,不能使用
if r:#
ret[-r:]=b'='* r# 切片赋值时,后边加的是可迭代对象,因此直接用b'='
print(ret)
return bytes(ret) # 可迭代对象转化为bytes类型
b64encode('abcde')