SQL Server 2008
常用关键字、数据类型和常用语法
常用关键字:
SQL server 2008一共大约有180多个关键字。简要分为主要关键字、辅助关键字和函数类关键字。本文就常用的这三类关键字进行语法说明和用例。
说明:1、比较好的习惯是,数据库名以D_开头,表名用T_开头,字段名以F_开头,这样可以防止和关键字重名。
2、如果确实用到了系统关键字,就要在关键上加[]方括号,以与关键字进行区别。例如有一个用户表被命名为USER,则查询该表内容的时候:SELECT * FROM USER语句是错误的,应该是SELECT * FROM [USER]。因为USER是关键字。
| 编号 |
关键字 |
应用场景 |
| 主要关键字 |
||
| 1
扫描二维码关注公众号,回复:
6125355 查看本文章

|
CREATE |
创建表 |
| 2 |
ALTER |
修改表结构 |
| 3 |
DROP |
删除数据库和表 |
| 4 |
INSERT |
插入表数据 |
| 5 |
INTO |
与INSERT连用,插入表数据 |
| 6 |
VALUES |
插入表数据时,指定列值 |
| 7 |
UPDATE |
更新表数据 |
| 8 |
SET |
与UPDATE连用,设定列值 |
| 9 |
SELECT |
查询表数据 |
| 10 |
FROM |
从哪个表中查询 |
| 11 |
WHERE |
查询表数据的条件 |
| 12 |
DATABASE |
数据库 |
| 13 |
TABLE |
数据表 |
| 14 |
NOT |
|
| 15 |
NULL |
空值 |
| 16 |
IDENTITY(1,1) |
标识列 |
| 17 |
CONSTRAINT |
约束,后边跟约束名 |
| 18 |
PRIMARY |
主键,PRIMARY KEY(列名) |
| 19 |
FOREIGN |
外键 FOREIGN KEY(列名) |
| 20 |
KEY |
|
| 21 |
REFERENCES |
把…印作参考,指定外键的时候用 |
| 22 |
CHECK |
CHECK约束 |
| 23 |
UNIQUE |
唯一性约束 |
| 24 |
COLUMN |
列 |
| 25 |
DEFAULT |
默认值 |
| 26 |
AND |
和 |
| 27 |
OR |
或 |
| 28 |
TRUNCATE |
截断,快速清空表内数据 |
| 29 |
ORDER |
常与by连用 |
| 30 |
BY |
与GROUP或ORDER连用 |
| 31 |
ASC |
升序ascend(上升) |
| 32 |
DESC |
降序descend(下降;沿…向下) |
| 33 |
AS |
列名别称 |
| 34 |
DELETE |
删除表数据 |
| 35 |
LIKE |
通配符 |
| 36 |
IS |
用于NULL值 |
| 37 |
IN |
离散值 |
| 38 |
BETWEEN |
连续值,常与and连用 |
| 39 |
GROUP |
分组,常与by连用 |
| 40 |
HAVING |
对GROUP BY分组内的数据进行过滤 |
| 41 |
TOP |
筛选结果集 |
| 42 |
DISTINCT |
去重 |
| 43 |
UNION |
合并查询结果 |
| 44 |
ALL |
|
| 45 |
CASE |
类似与C#中的SWITCH--CASE语法,查询离散值 |
| 46 |
ELSE |
设定case的默认值 |
| 47 |
END |
结束case语句 |
| 48 |
WHEN |
与case连用 |
| 49 |
VIEW |
视图 |
| 50 |
INDEX |
索引 |
| 51 |
JOIN |
联合查询 |
| 52 |
ON |
与JOIN连用 |
数据类型:
SQL Server 2008一共有36种数据类型。具体如下:
| 编号 |
数据类型 |
存储空间 |
字符类型说明 |
| 整数型(4) |
|||
| 1 |
tinyint |
1字节 |
取值范围:0--255 |
| 2 |
smallint |
2字节 |
取值范围:-2768--32767 |
| 3 |
int |
4字节 |
取值范围:-231—231-1 |
| 4 |
bigint |
8字节 |
取值范围:-263—263-1 |
| 浮点类型(6) |
|||
| 5 |
decimal(p,s) |
5—17 字节 |
取值范围:-1038+1—1038-1。p (有效位数,p的取值小于38),可储存的最大十进位数总数,小数点左右两侧都包括在内。s (小数位数,0 <= s <= p <= 38) 小数点右侧的小数位数。 例如:decimal(3,1)表示,一共3位有效位,其中整数部分2位,小数部分1位,最大值是99.9,最小值是-99.9 |
| 6 |
numeric(p,s) |
4字节 |
取值范围:-214,768.3648--214,768.3647。用法类似decimal |
| 7 |
smallmoney |
4字节 |
取值范围:–214 748.3648~2 14 748.3647。主要是用于货币 |
| 8 |
money |
8字节 |
取值范围:-3.438—3.438主要用于货币 |
| 9 |
real |
4或8字节 |
取值范围:-3.40E+38~-1.18E-38,0,1.18E-38~3.40E+38 |
| 10 |
float |
4字节 |
取值范围:-3.4E38~3.4E38 |
| 字符类型(8) |
|||
| 11 |
char(n) |
每字符1字节,最大可达8000字节。ANSI字符,会用空格填充。 |
|
| 12 |
nchar(n) |
每字符2字节,最大可达4000字节。UNICODE字符,会用空格填充。 |
|
| 13 |
varchar(n) |
每字符1字节,最大可达8000字节。ANSI字符,可变长度,不会用空格填充。 |
|
| 14 |
varchar(MAX) |
ANSI字符,最大可达2G |
|
| 15 |
nvarchar(n) |
每字符2字节,最大可达4000字节。UNICODE字符,可变长度,不会用空格填充。 |
|
| 16 |
nvarchar(MAX) |
最多为231–1(2 147 483 647)字符 |
|
| 17 |
text |
每字符1字节,最大可达2G。 |
|
| 18 |
ntext |
每字符2字节,最大可达2G。 |
|
| 二进制数据类型(5) |
|||
| 19 |
bit |
1比特 |
NULL,0或1 |
| 20 |
binary(n) |
固定长度二进制数据,最高可达8000字节。 |
|
| 21 |
varbinary |
可变长度二进制数据,最高可达8000字节。 |
|
| 22 |
varbinary(MAX) |
最多为232-1字节 |
|
| 23 |
image |
可变长度二进制数据,最高可达2GB。 |
|
| 日期和时间类型(7) |
|||
| 24 |
smalldatetime |
||
| 25 |
date |
3字节 |
精度一天,支持范围01/01/0000—31/12/9999。 |
| 26 |
datetime |
8字节 |
0.00333秒,支持的范围是'1000-01-01 00:00:00'到'9999-12-31 23:59:59'。以'YYYY-MM-DD HH:MM:SS'格式显示DATETIME值 |
| 27 |
datetime2(n) |
6--8字节 |
100纳秒 |
| 28 |
datetimeoffset(n) |
8--10字节 |
100纳秒 |
| 29 |
time |
3—5字节 |
100纳秒 |
| 30 |
timestamp |
TIMESTAMP值返回后显示为'YYYY-MM-DD HH:MM:SS'格式的字符串。 |
|
| 其他数据类型(6) |
|||
| 31 |
xml |
用于存储xml格式的文档,最大可达2GB,支持128级层次。 |
|
| 32 |
geography |
地理数据。 |
|
| 33 |
geometry |
几何数据。 |
|
| 34 |
hierarchyid |
主要解决的问题是拥有层次关系的表格,通常用来建立树形结构 |
|
| 35 |
sql_variant |
用于存储 SQL Server 2005 支持的各种数据类型(不包括 text、ntext、image、timestamp 和 sql_variant)的值。对于 sql_variant 数据类型,必须先将它转换为其基本数据类型值,然后才能参与诸如加减这类运算 |
|
| 36 |
uniqueidentifier |
Uniqueidentifier 是全局唯一的标识,可存储16字节的二进制值,其作用与全局唯一标记符(GUID)一样,一般用来做主键。 |
|
常用语法:
一、数据库
【创建数据库】
CREATE DATABASE <dbname>
【修改数据库】
ALTER DATABASE <dbname>
【删除数据库】
DROP DATABASE <dbname>
二、表结构
【创建数据表】
1、设定字段是允许空,非空、标识列,自增和主键约束。
(CUSTOMERID INT IDENTITY(1,1),--客户ID,标识列,从开始,每次自增
COMPANYNAME NVARCHAR(50) NOT NULL,--,如果不显示指明NOT NULL,系统默认是允许空的
USERNAME NVARCHAR(10) NOT NULL,--联系人姓名,非空
PHONENUMBER CHAR(11) NULL,--联系电话,允许为空
CONSTRAINT T_CUSTOMER_PrimaryKey PRIMARY KEY (CUSTOMERID)) --设定USERID为主键,用括号括起来
/*每个单词之间是空格隔开,每个字段之间用单引号隔开,整个字段定义部分用括号括起来*/
/*T_RegUser_PrimaryKey是约束名*/
2、设定字段是UNIQUEIDENTIFIER数据类型,唯一性约束,CHECK约束和默认值约束。
CREATE TABLE T_CUSTOMER
(CUSTOMERID UNIQUEIDENTIFIER UNIQUE,--客户ID,UNIQUEIDENTIFIER类型,唯一性约束
COMPANYNAME NVARCHAR(50) NOT NULL UNIQUE,--公司名称,非空,唯一性约束
USERNAME NVARCHAR(10) NOT NULL,
PHONENUMBER CHAR(11) NULL,
AGE TINYINT NULL CHECK(AGE>0),--联系人年龄,允许空,check约束必须大于
MODIFIEDDATE DATE NULL CONSTRAINT T_CUSTOMER_DEFAULT DEFAULT GETDATE(),--默认值约束,并调用SQL函数GETDATE()
CONSTRAINT T_CUSTOMER_PrimaryKey PRIMARY KEY (CUSTOMERID))
(ORDERID INT IDENTITY(1,1),--订单ID,标识字段,自增
PRODUCT NVARCHAR(50) NOT NULL,--产品
PAYMENT MONEY NOT NULL,--货款
ORDER_CUSTOMERID UNIQUEIDENTIFIER NOT NULL,--客户ID,为外键,外键内容是T_CUSTOMER表的CUSTOMERID列
CONSTRAINT T_ORDER_PrimaryKey PRIMARY KEY(ORDERID),--设置ORDERID为主键
CONSTRAINT T_ORDER_T_CUSTOMER_ForeignKey FOREIGN KEY(ORDER_CUSTOMERID) REFERENCES T_CUSTOMER(CUSTOMERID))
/*设定外键基本语法*/
CONSTRAINT <约束名> FOREIGN KEY(<外键表列名>) REFERENCES <主键表>(<主键表列名>)
/*设置外键,T_ORDER_T_CUSTOMER_ForeignKey是外键约束名,FOREIGN KEY后边是本表内要被设置的外键列
REFERENCES后边是主键所在的表,括号内是主键表的链接列*/
/*表名后的所有内容,都要拿括号括起来*/
/*外键的数据类型要和主键一模一样,哪怕主键是UNIQUEIDENTIFIER也必须设置成一样*/
【修改表名】
/*修改表名,可能会破坏脚本和存储过程。*/
EXEC SP_RENAME '<原表名>','<新表名>'
示例:
EXEC SP_RENAME 'T_CUSTOMER2','T_CUSTOMER22'
【修改表结构】
1、添加列和列的约束
/*添加列、添加唯一性约束*/
ALTER TABLE <表名>
ADD <列名1> BIT NOT NULL,--添加多个列不用括号,用逗号分开即可
<列名2> INT NOT NULL UNIQUE--声明的时候,和创建表的时候一样
示例:
ALTER TABLE T_CUSTOMER
ADD GENDER BIT NOT NULL,--添加多个列不用括号,用逗号分开即可
CUSTOMERADDRESS INT NOT NULL UNIQUE--声明的时候,和创建表的时候一样
2、删除列
/*删除列*/
ALTER TABLE <表名>
DROP COLUMN <列名1>,<列名2>--使用关键字COLUNM(列)
示例:
ALTER TABLE T_CUSTOMER
DROP COLUMN GENDER,CUSTOMERADDRESS--使用关键字COLUNM(列)
/*每个列名之间用逗号隔开,如果列上有任何约束,则需要先删除约束*/
3、添加主键约束,唯一性约束、check约束和默认值约束
/*添加主键约束,唯一性约束,check约束和默认值约束*/
ALTER TABLE <表名>
ADD CONSTRAINT <约束名> CHECK (CHECK约束内容),--CHECK约束,每个约束之间用逗号隔开
CONSTRAINT <约束名> UNIQUE(<列名>),--唯一性约束
CONSTRAINT <约束名> DEFAULT <默认约束值或函数> FOR <列名> --默认值约束
示例:
ALTER TABLE T_CUSTOMER
ADD CONSTRAINT T_CUMSTOMER_AGE_CHECK CHECK (AGE>0),--CHECK约束
CONSTRAINT T_CUSTOMER_USERNAME_UNIQUE UNIQUE(USERNAME),--唯一性约束
CONSTRAINT T_CUSTOMER_DEFAULT DEFAULT GETDATE() FOR MODIFIEDDATE --默认值约束
4、删除主键约束,唯一性约束、check约束和默认值约束
/*删除主键约束,删除唯一性约束、删除check约束,删除默认值约束*/
ALTER TABLE <表名>
DROP <约束名1>,<约束名2>,<约束名3>--后边直接跟约束名,用逗号隔开
示例:
ALTER TABLE T_CUSTOMER
DROP T_CUSTOMER_DEFAULT,--后边直接跟约束名,用逗号隔开
UQ__T_CUSTOM__EDBD0E1935BCFE0A,
CK__T_CUSTOMER__AGE__276EDEB3
如果创建的时候,没有显性的指定约束名,例如UNIQUE,CHECK等约束,可以通过SP_HELP T_CUSTOMER来查询所有的约束名。在查询结果的第7个结果集中,可以看到类似下图的结果,第一列是约束类型,第二列就是约束名,最后一列是列名。

5、修改列的字段类型
/*修改列的字段类型和非空*/
ALTER TABLE <表名>
ALTER COLUMN <列名> <新数据类型>
示例:
ALTER TABLE T_CUSTOMER
ALTER COLUMN CUSTOMERADDRESS NVARCHAR(100) –-修改多列的字段类型还不知道怎么改
6、设置列的空/非空
/*修改列的空和非空*/
ALTER TABLE <表名>
ALTER COLUMN <列名> <数据类型> NOT NULL—必须跟数据类型,否则会
示例:
ALTER TABLE T_CUSTOMER
ALTER COLUMN MODIFIEDDATE DATE NULL
7、修改列名
/*修改列名,可能会破坏脚本和存储过程*/
EXEC SP_RENAME '<tbname>.<原列名>','<新列名>','COLUMN'—-后边的column是固定写法
示例:
EXEC SP_RENAME 'T_CUSTOMER.PHONENUMBER','PHONE','COLUMN'--将原来的PHONENUMBER电话号码,改成PHONE电话
【删除表】
DROP TABLE <tbname>
三、表数据
【插入数据】
1、插入一行全字段数据
/*插入一行全字段数据*/
INSERT INTO <tbname>
VALUES('值1','值2','值3') –-值的数量必须和表定义的一样多,而且数据类型必须一一对应
示例:
INSERT INTO T_CUSTOMER
VALUES (NEWID(),'公司3','用户3','123',DEFAULT,'xxx') –-要到了NEWID()函数
2、插入一行部分字段数据
/*插入一行数据*/
INSERT INTO <tbname>
(列1,列2,列3..)
VALUES('值1','值2','值3') –-字符串是要用单引号括起来,数字值不用
示例:
INSERT INTO T_CUSTOMER2
(COMPANYNAME,USERNAME,PHONENUMBER)
VALUES('公司1','用户1','13999999999')—与要插入的列一一对应,可以不同于表定义的顺序,可以乱序,只要一一对应即可
/*CUSTOMERID是标识列,自增的,所以不用指定*/
INSERT INTO T_CUSTOMER2
(COMPANYNAME,USERNAME,PHONENUMBER)
VALUES('公司2','用户2','13999999999'),
('公司3','用户3','13999999999'), --用括号将每一行数据括起来,括号与括号之间用逗号隔开
('公司4','用户4','13999999999')
4、插入函数值和默认值
/*UNIQUEIDENTIFIER类型字段,使用NEWID()函数。有默认值的使用DEFAULT关键字*/
INSERT INTO <tbname>
(列1,列2,列3,列4,)
VALUES(NEWID(),'值1','值2',DEFAULT)
示例:
/*CUSTOMERID是UNIQUEIDENTIFIER类型,所以要使用NEWID()函数,MODIFIEDDATE字段有模式值,是取得当前的日期时间GETDATE()函数*/
INSERT INTO T_CUSTOMER
(CUSTOMERID,COMPANYNAME,USERNAME,PHONE,MODIFIEDDATE)
VALUES(NEWID(),'公司','用户','13999999999',DEFAULT)
【修改数据】
/*UPDATE通常是与SET和WHERE配合使用,如果不用WHERE,则会把整个列都修改*/
UPDATE <tbname>
WHERE 列='值' AND 列='值'—-可以是任何删选条件
示例:
/*将公司2的电话号码修改成13888888888*/
UPDATE T_CUSTOMER
SET PHONE='13888888888'
WHERE COMPANYNAME='公司2'
【查询数据】
1、查询所有数据,或者部分行数据(用where进行过滤)
/*查询表中的所有数据用星号*/
SELECT *
FROM <tbname>
WHERE <筛选条件1> AND <筛选条件2> OR <筛选条件3>
示例:
/*查询客户表中的所有数据*/
SELECT * FROM T_CUSTOMER
2、查询表中的部分列数据,
/*查询部分列的所有数据,或者部分行部分列的数据*/
SELECT <列名1>,<列名2>,<…> --这个列名顺序可以按照自己的想法来,不用非要和表定义一致
FROM T_ORDER
WHERE <筛选条件1> AND <筛选条件2> OR <筛选条件3>
示例:
/*查询订单表中的所有数据*/
SELECT PRODUCT, PAYMENT
FROM T_ORDER
3、对查询出来的数据进行排序
/*ORDER BY 的默认排序是升序ASC,如果BY的列是数字,则是从大到小,如果是字符串,则是从A到Z,如果是时间从远至近。降序的话是加关键字DESC。假如是升序,最好也加上ASC*/
SELECT *
FROM <tbname>
WHERE <筛选条件1> AND <筛选条件2> OR <筛选条件3>
ORDER BY <列名1> ASC(升序)/DESC(降序),<列名2> ASC(升序)/DESC(降序)
/*列1和列2可以采用不一样的排序*/
示例:
/*查询客户表中的所有数据*/
SELECT *
FROM T_ORDER
WHERE PAYMENT>100 –价格大于100
ORDER BY PRODUCT ASC, PAYMENT DESC --产品名称使用升序,产品价格使用降序
【删除数据】
1、删除一般数据
/*删除公司一般数据*/
DELETE FROM <tbname>
WHERE <筛选条件1> AND <筛选条件2> OR <筛选条件3>
示例:
/*删除公司,公司ID是订单表的外键*/
DELETE FROM T_CUSTOMER
WHERE COMPANYNAME='公司1'
2、快速高效的删除表内的全部数据
/*快速高效的清空表内的全部数据,TRUNCATE本意是截短、把…截短。TRUNCATE只能用来删除表中的所有数据,不能用来删除部分数据,而且有外键约束的主键表不能被删除*/
示例:
/*删除公司,公司ID是订单表的外键*/
TRUNCATE TABLE T_CUSTOMER
3、删除有外键约束的数据
/*如果该条数据已经被外键表引用,则无法删除。被引用的数据必须置于未被使用的状况,方法就是修改外键表字段,或者删除外键表中的引用数据*/
示例:
/*删除公司,公司ID是订单表的外键*/
UPDATE T_ORDER –将所有引用公司1的数据全部改成公司2
SET ORDER_CUSTOMERID='2f20b157-a287-43e0-be99-1fb917618629'
WHERE ORDER_CUSTOMERID='c013076f-7889-400e-aa7a-b38436730d70'
/*然后才可以在主键表中删除公司1*/
DELETE FROM T_CUSTOMER
WHERE COMPANYNAME='公司1'
四、其他辅助关键字
【LIKE通配符】
1、单字符通配符,只能用于字符串匹配
/*单字符通配符_*/
SELECT *
FROM T_CUSTOMER
WHERE <列名1> LIKE '_通配符_' AND <筛选条件2> OR <筛选条件3>
示例:
SELECT *
FROM T_CUSTOMER
WHERE USERNAME LIKE '用户_'–-将客户表中包含"用户+任意字符"的行数据查出来
2、多字符通配符,只能用于字符串匹配
/*单字符通配符%,百分号代表*从0到N的字符串/
SELECT *
FROM T_CUSTOMER
WHERE <列名1> LIKE '%通配符%' AND <筛选条件2> OR <筛选条件3>
示例:
SELECT *
FROM T_CUSTOMER
WHERE USERNAME LIKE '%用户%'–-查询客户表中用户名包含"用户"二字的所有数据
【AS列名】
1、AS可以将查询结果的英文定义表头改成非英语的别名表头
/*单字符通配符_*/
SELECT <列名1> AS <别名1>,<列名2> AS <别名2>–-每个列之间用逗号隔开
FROM <tbname>
示例:
SELECT COMPANYNAME AS 公司,USERNAME AS 联系人,PHONE AS 联系电话
FROM T_CUSTOMER
【NULL值】
1、NULL值要用特殊的关键字IS 或IS NOT,而不能用!=或<>之类的符号
示例:
SELECT COMPANYNAME,USERNAME
FROM T_CUSTOMER
WHERE PHONE IS NULL--选出电话号码是NULL的行,也可以与其他条件一起使用
或者
SELECT COMPANYNAME,USERNAME
FROM T_CUSTOMER
WHERE PHONE IS NOT NULL--选出电话号码不是NULL的行
【IN匹配离散值】
1、如果要查询离散值,一个方法是很多个OR条件,可以可以用IN或NOT IN关键字。
示例:
SELECT *
FROM T_DOCTOR
WHERE AGE IN (23,24,34) --选出年龄是23,24和34岁的医生
或者
SELECT *
FROM T_DOCTOR
WHERE AGE NOT IN (23,24,34) –-选出年龄不是23,24和34岁的医生
【BETWEEN匹配连续值】
1、如果要查询离散值,一个方法是很多个OR条件,可以可以用IN或NOT IN关键字。
示例:
SELECT *
FROM T_DOCTOR
WHERE AGE BETWEEN 20 AND 50--查询出年龄介于20到50之间的医生数据
或者
SELECT *
FROM T_DOCTOR
WHERE AGE NOT BETWEEN 20 AND 50--查询出年龄不介于20到50之间的医生数据
【GROUP分组】
1、按照某列分组
/*先按照GROUP BY字段进行分组,然后在分组内进行操作。所以SELECT后的列名只能是GROUP BY内的列,或者是聚合函数。如果有WHERE的话,GROUP和ORDER都必须放在WHERE之后*/
SELECT分组列名 AS 列别名,聚合函数1,聚合函数2
FROM <tbname>
GROUP BY 分组列名
示例:
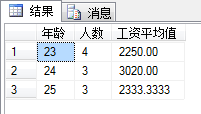
SELECT F_AGE AS 年龄,COUNT(*) AS 人数, AVG(F_SALARY) AS 工资平均值
FROM T_EMPLOYEE
GROUP BY F_AGE—按照年龄分组
输出结果:
2、按照多列分组
/*先按照列名1分组,再按照列名2分组。如列名1分为3组,每一组里边按照列名2又分为2组,则输出就是6行数据*/
SELECT列名1,列名2,聚合函数
FROM <tbname>
GROUP BY 列名1,列名2--直接用逗号隔开多个列名即可
示例:
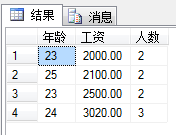
SELECT F_AGE AS 年龄,F_SALARY AS 工资, COUNT(*) AS 人数
FROM T_EMPLOYEE
GROUP BY F_AGE,F_SALARY--按照年龄分组,再按照工资分组,然后统计人数
ORDER BY F_AGE ASC--ORDER BY也可以一起使用
输出结果:

【HAVING数据分组后的再筛选】
1、数据分组后的筛选
/*HAVING 是对分组以后的数据进行过滤。有了GROUP BY才能使用HAVING,无GROUP BY 是不能使用HAVING的。HAVING中的列,也只能和SELECT语句一样,使用GROUP BY列或者聚合函数*/
SELECT列名1,列名2,聚合函数
FROM <tbname>
GROUP BY 列名1,列名2--直接用逗号隔开多个列名即可
HAVING 聚合函数的筛选条件
示例:
SELECT F_AGE AS 年龄,F_SALARY AS 工资, COUNT(*) AS 人数
FROM T_EMPLOYEE
GROUP BY F_AGE,F_SALARY--按照年龄分组,再按照工资分组,然后统计人数
HAVING COUNT(*)>1--在分组中剔除count数为的小分组
输出结果:
【TOP限制结果集】
1、对查询出的前几条数据的筛选
/*一般是与ORDER BY连用,而且TOP 必须放在*型号或者列名的前面。不和ORDER BY也可以使用,但是查询结果不确定*/
SELECT TOP 数量列1,列2
FROM <tbname>
ORDER BY 排序列1,排序列2 DESC/ASC
示例:
SELECT TOP 3 F_NAME,F_SALARY--选出工资最高的三个人
FROM T_EMPLOYEE
ORDER BY F_SALARY DESC
2、对查询出的中间结果进行筛选,使用子查询。这个非常重要的是用在分页上。
/*如果要选择从X开始后Y个结果的子集,第一步先查询出TOP X-1个结果子集,然后把它排除掉就是从X到X+Y的结果子集。删除的时候一般是用主键,或者没有重复的数据列。最主要的是NOT IN关键字*/
SELECT TOP X 列名1,列名2
FROM <tbname>
WHERE主键列 NOT IN (SELECT TOP X-1 主键 FROM <tbname> ORDER BY 排序列名 DESC )
ORDER BY 排序列名 DESC
/*WHERE后的列名必须和子查询的SELECT列名一致*/
/*主查询的ORDER BY 列名必须和子查询的ORDER BY列名一致,而且排序方式也必须一致*/
示例:
/*查询出工资排名是4,5,6名*/
SELECT TOP 3 F_NAME,F_SALARY
FROM T_EMPLOYEE
WHERE F_ID NOT IN (SELECT TOP 3 F_ID FROM T_EMPLOYEE ORDER BY F_SALARY DESC )
ORDER BY F_SALARY DESC
【DISTINCT去除重复数据】
1、查询一列中的无重复数据
/*只能查询列的结果集。DISTINCT要放在SELECT之后,和所有列名的前面*/
SELECT DISTINCT 去重列名
FROM <tbname>
示例:
SELECT DISTINCT F_DEPARTMENT--查询出的部门列去重
FROM T_EMPLOYEE
2、多列组合去重
/*每个列都一样的,才算重复。如果一列不一样,就不算重复*/
SELECT DISTINCT 去重列名1,去重列名2
FROM <tbname>
示例:
SELECT DISTINCT F_DEPARTMENT,F_SUBCOMPANY
FROM T_EMPLOYEE
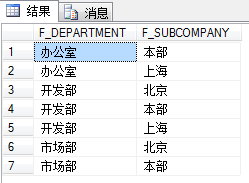
【UNION合并查询结果】
1、合并查询结果
/*合并查询结果集,所以每个每个结果集必须有相同的列数,每个结果集的列必须类型相容,位置也必须一致,可以合并2个以上的查询结果。但是默认会合并重复数据*/
/*如果列数不一样,必须再相应的位置补齐。默认查询结果是对第一列排序*/
/*如果列名不一致,则表头默认是采用第一个查询的列名*/
/*外键是把多个列组合在一起,而UNION是把多个行组合在一起*/
SELECT 列1,列2,补齐列 FROM <tbname1>
UNION
SELECT列1,列2, 列3 FROM <tbname2>
示例:
SELECT FNAME,FAGE,0 AS "工资" FROM T_TEMPEMPLOYEE--临时工没工资,所以要补齐
UNION
SELECT F_NAME,F_AGE,F_SALARY FROM T_EMPLOYEE
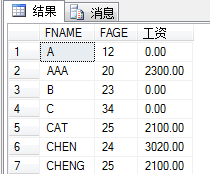
2、ALL合并查询出的所有结果,不去重
/*除非程序需要,一般要加ALL,因为判断去重,会让数据库消耗掉大量的资源*/
SELECT 列1,列2,补齐列 FROM <tbname1>
UNION ALL
SELECT列1,列2, 列3 FROM <tbname2>
示例:
SELECT FNAME FROM T_TEMPEMPLOYEE--名字里头有重复的
UNION ALL
SELECT F_NAME FROM T_EMPLOYEE
3、利用UNION 多加一行,做一些函数操作
示例:
SELECT F_NAME,F_SALARY FROM T_EMPLOYEE
UNION ALL
SELECT '工资合计',SUM(F_SALARY) FROM T_EMPLOYEE--工资合计
UNION ALL
SELECT '平均工资',AVG(F_SALARY) FROM T_EMPLOYEE--平均工资
五、常用函数:
| 函数名 |
函数意义 |
示例 |
| 数学函数 |
||
| SUM() |
求某一列的和 |
|
| AVG() |
求某一列的平均值 |
|
| MAX() |
取出某一列的最大值 |
|
| MIN() |
取出某一列的最小值 |
|
| ABS() |
求绝对值 |
|
| CEILING() |
舍入到比它大的、最近的最大整数。注意不是数学意义上的四舍五入 |
例如:3.33舍入到4,-3.33舍入到-3 |
| FLOOR() |
舍入到比它小的、最近的最大整数。注意不是数学意义上的四舍五入 |
例如:3.33舍入到3,-3.33舍入到-4 |
| ROUND() |
舍入到离我半径的整数,就是传统意义上的数学上的四舍五入 |
例如:3.65舍入到4,-3.65舍入到-4。 ROUND(3.14159,3)就是保留小数点后3位,将舍入为3.14200 |
| 字符串函数 |
||
| LEN() |
字符串的长度 |
括号里头是字符串或列名 |
| LOWER() |
字符串转成小写 |
同上 |
| UPPER() |
字符串转成大写 |
同上 |
| LTRIM() |
去掉字符串左边的空格 |
同上 |
| RTRIM() |
去掉字符串右边的空格 |
同上。如果要去掉两边的空格,就想L再R,或者先R再L |
| SUBSTRING() |
取子字符串。有三个参数,SUBSTRING(STRING START_POSITION LENGHT)取子字符串 |
SELECT SUBSTRING('abcdef111',2,3) |
| 日期函数 |
||
| GETDATE() |
获取服务器当前日期和时间 |
|
| DATEADD() |
DATEADD (datepart , number, date ),计算增加以后的日期。参数date为待计算的日期;参数number为增量;参数datepart为计量单位(可取值year、quarter季度、month、day、week、hour、minute、second等,具体参考书) |
SELECT DATEADD(MONTH ,-8,GETDATE()) --为计算日期date的个月之前的日期 |
| DATEDIFF() |
DATEDIFF(datepart,startdate,enddate):计算两个日期之间的差额。 datepart 为计量单位,可取值参考DateAdd。 |
统计不同工龄的员工的个数: select DateDiff(year,FInDate, getdate()),count(*) from T_Employee group by DateDiff(year, FInDate,getdate()) |
| DATEPART() |
DATEPART (datepart,date):返回一个日期的特定部分。datepart 为计量单位,可取值参考DateAdd。 |
select DatePart(year,FInDate),count(*) from T_Employee group by DatePart(year,FInDate) |
| 类型转换函数 |
||
| CAST() |
CAST ( expression AS data_type) expression是要转换的对象,data_type是要转换的数据类型 |
SELECT CAST('123' ASINT)+1, CAST('2009-09-09' AS DATE) |
| CONVERT() |
CONVERT ( data_type, expression) expression是要转换的对象,data_type是要转换的数据类型 |
SELECT CONVERT(DATETIME,'2012-12-12'), CONVERT(INT,'123')+2 |
| 其他函数 |
||
| ISNULL() |
ISNULL(expression,value) expression是列名,如果不为空则返回具体的列值,如果未空,则用value填充 |
SELECT ISNULL(FName,'佚名') as 姓名 FROM T_Employee 如果名字为空,则用佚名来代替 |
| CASE() |
用法1:非常类似于C#中的SWITCH-CASE用法。用来判断离散值 离散单值判断,相当于switch case CASE 列名 WHEN value1 THEN ReturnValue1 WHEN value2 THEN ReturnValue2 WHEN value3 THEN ReturnValue3 ELSE DefaultReturnValue END 用法2:非常类似于C#中的IF-ELSE用法 CASE WHEN 表达式1 THEN ReturnValue1 WHEN 表达式2 THEN ReturnValue2 WHEN 表达式3 THEN ReturnValue3 ELSE DefaultReturnValue END CASE后边什么也不写 ELSE不一定要有,但必须有END |
用法1: SELECT FName, (CASE FLevel WHEN 1 THEN 'VIP客户' WHEN 2 THEN '高级客户' WHEN 3 THEN '普通客户' ELSE '客户类型错误' END) as FLevelName FROM T_Customer 用法2: SELECT F_NAME, (CASE WHEN F_SALARY<2000 THEN '穷人' WHEN 2000<=F_SALARY AND F_SALARY<3000 THEN '中产' WHEN 3000<=F_SALARY AND F_SALARY<5000 THEN '富人' WHEN 5000<=F_SALARY THEN '贵族' ELSE '未知' END )AS 收入水平 FROM T_EMPLOYEE 用法3: SELECT F_NAME, (CASE WHEN F_SALARY<2000 THEN F_SALARY*1.5 WHEN 2000<=F_SALARY AND F_SALARY<3000 THEN F_SALARY*1.2 WHEN 3000<=F_SALARY AND F_SALARY<5000 THEN F_SALARY*1.0 WHEN 5000<=F_SALARY THEN F_SALARY*0.90 END )AS 涨工资 FROM T_EMPLOYEE |
| COUNT() |
求某一列的行数 |
|
| NEWID() |
数据库自带的函数,生成一个GUID的id号 |
|