1.函数介绍
1.1函数的定义
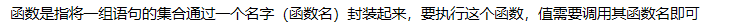
1.2函数的特性
减少重复代码,使得程序变得可扩展,是程序变得易维护
不过在以上特性之外,需要记得的是以下
print(sayhi)返回的是函数所在的内存地址
print(sayhi())返回的是函数执行的结果
2.函数参数
2.1形参与实参
形参:只有被调用的时候才会分配内存单元,调用结束后,释放分配的内存单元,形参只在函数内部有效,函数调用结束后返回到主函数,形参不能再使用该形参

实参:可以是常量,变量,表达式函数等,但是无论实参是何种类型的值,在函数调用时,必须是确定的值,不会由于函数的执行结束而丢失,在函数执行时也可以将这个值传递给形参来使用
看以下例子
def calx(x,y): res = x**y return res c = calx(a,b) print(c)
可以说函数开头调用的x,y就是形参,这些参数只是在函数内部生效,而下方调用函数中传入的a与b就是实参,他是确定存在的,并不会因为函数执行完了而丢失,同时也会将这个参数传递给函数内形参。
2.2默认参数,关键参数以及非固定参数
2.2.1看如下代码
def stu_register(name,age,country,course): print("----注册学生信息------") print("姓名:",name) print("age:",age) print("国籍:",country) print("课程:",course) stu_register("王山炮",22,"CN","python_devops") stu_register("张叫春",21,"CN","linux") stu_register("刘老根",25,"CN","linux")
发现 country 这个参数 基本都 是"CN", 就像我们在网站上注册用户,像国籍这种信息,你不填写,默认就会是中国, 这就是通过默认参数实现的,把country变成默认参数非常简单
def stu_register(name,age,course,country="CN"):
修改完之后我们就会发现,‘CN’就是这个函数的默认函数,在于此同时我们会发现country在变为默认参数后,他所在的位置也会发生改变,这个时候把参数位置还是按照原来位置放置以下,可以看一下结果。
def stu_register(name,age,country="CN",course): SyntaxError: non - default argument follows default argument
在我们调整位置后,果然报错,而错误原因是没有找到指定的变量,调整位置后函数就找不到变量了,所以切记在函数内定义默认函数需要定义在位置函数后面。
2.2.2接下来再说关键参数
关键参数的定义:正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可(指定了参数名的参数就叫关键参数),但记住一个要求就是,关键参数必须放在位置参数(以位置顺序确定对应关系的参数)之后。
def stu_register(name, age, course='PY' ,country='CN'): print("----注册学生信息------") print("姓名:", name) print("age:", age) print("国籍:", country) print("课程:", course)
可以这么调用
stu_register("王山炮",course='PY', age=22,country='JP' )
但是绝对不可以这么调用
stu_register("王山炮",course='PY',22,country='JP' )
因为22是一个位置参数,对于位置参数他应该在第二个位置,而关键参数也不能在位置函数前面,这样还是会报错,不过在调用的同时也需要紧记,定义了关键参数,不要继续调用位置位置参数,这样会引起函数混乱。
2.2.3接下来我们说一下非固定参数,对于函数传参,我们会想着一个函数会调用多个参数,这个时候我们怎么操作呢,看以下代码
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式 print(name,age,args) stu_register("Alex",22) #输出 #Alex 22 () #后面这个()就是args,只是因为没传值,所以为空 stu_register("Jack",32,"CN","Python") #输出 # Jack 32 ('CN', 'Python')
需要记住的是在函数中传入*args,会把多传入的参数编程一个元组的形式放入
除了*args还有另外一种为**kwargs
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式 print(name,age,args,kwargs) stu_register("Alex",22) #输出 #Alex 22 () {}#后面这个{}就是kwargs,只是因为没传值,所以为空 stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong") #输出 # Jack 32 ('CN', 'Python') {'province': 'ShanDong', 'sex': 'Male'}
所以我们在后面函数的学习中,我们会经常来使用这俩种方式来传入多个变量。
3.返回值
对于函数外部的代码要想获取函数内的执行结果,就可以用函数里的return语句把结果返回
看以下代码
def stu_register(name, age, course='PY' ,country='CN'): print("----注册学生信息------") print("姓名:", name) print("age:", age) print("国籍:", country) print("课程:", course) if age > 22: return False else: return True registriation_status = stu_register("王山炮",22,course="PY全栈开发",country='JP') if registriation_status: print("注册成功") else: print("too old to be a student.")
不过需要知道的是,对于函数如果碰到return语句就会马上返回,后面的语句就不会再运行,也可以理解为见return就是函数的结束。
函数永远只能返回一个值,如果返回多个值只能用逗号,返回一个元组。默认函数没有返回的话,返回的就是一个空,NONE
4.局部变量与全局变量
看以下代码
name = "Alex Li" def change_name(name): print("before change:",name) name = "金角大王,一个有Tesla的男人" print("after change", name) change_name(name) print("在外面看看name改了么?",name)
我们可以清晰看到结果
before change: Alex Li
after change 金角大王,一个有Tesla的男人
在外面看看name改了么? Alex Li
这就说明函数内部的变量发生了变更,可是函数外变量并没有,或者是说函数内变量变更并没有在函数外生效,这个时候可以下以下定义:
全局变量:定义在函数外部一级代码的变量叫做全局变量,全局能用。
局部变量:在函数结束之后,局部变量全部从内存中清除,俩个局部变量是不可能互相调用的。
所以这个时候对于函数内的变量调用,就有了优先级,在函数内,局部变量存在优先局部变量,无则在调用全局变量,当全局变量与局部变量同名时,在定义局部变量的函数内,局部变量起作用;在其它地方全局变量起作用。如果全局变量是一个全局变量,在函数内调用的时候,除了重新赋值外,增删改都是可以实现的。
但是,我们任性呢,非要在函数内修改全局变量也是可以的。
name = "Alex Li" def change_name(): global name name = "Alex 又名 金角大王,路飞学城讲师" print("after change", name) change_name() print("在外面看看name改了么?", name)
这个时候就会发现在函数内发生变化后,全局变量也跟着发生了变换,是同时发生变换的。所以说必须要用到函数内修改全局变量,只能使用global这个方法。
5.嵌套函数
看以下代码
name = "Alex" def change_name(): name = "Alex2" def change_name2(): name = "Alex3" print("第3层打印", name) change_name2() # 调用内层函数 print("第2层打印", name) change_name() print("最外层打印", name)
输出结果为
第3层打印 Alex3
第2层打印 Alex2
最外层打印 Alex
如果此时,在最外层调用change_name2()会出现什么效果?结果就是出错没有任何结果
所以我们需要知道以下知识点
函数内部可以再次定义函数,函数内部的函数如果被调用
同名字的变量会一层一层的向上查找变量
需要注意的是执行的顺序以及变量的内外
关于上面出错的原因就是最外层的函数并没有被执行,只是执行内部的函数并不可行,如果为了执行,可以采用另外一种方式会在下篇文字中说明,那就是函数的高阶应用闭包
6.作用域
在python中,一个函数就是一个作用域,所有的局部变量都放在其作用域中,定义完成后,作用域已经完成,日后调用,会作用链向上查找,
比较详细的会在下篇文字中说明,那就是函数的命名空间。
7.匿名函数
匿名函数就是不需要显式的指定函数名
看以下代码
def calc(x,y): return x**y print(calc(2,5)) #换成匿名函数 calc = lambda x,y:x**y print(calc(2,5))
其实匿名函数对于正常的函数来说变更并不是特别大,他的作用就是较少代码量,看着高级,还设有就是搭配着其他函数来用
8.高阶函数
变量可以指向一个函数,而函数的参数能够接收变量,name一个函数就可以接收另外一个函数作为参数,这种函数称之为高阶函数
def add(x,y,f): return f(x) + f(y) res = add(3,-6,abs) print(res)
判定一个函数是否为高阶函数有以下特点
接收一个或者多个函数作为输入
return返回另外一个函数都可以称之为高阶函数
9.递归函数
递归函数的定义:在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
看以下代码
def calc(n): print(n) if int(n/2) ==0: return n return calc(int(n/2)) calc(10)
输出结果为
10 5 2 1
如果变更代码为
def calc(n): v = int(n/2) print(v) if v > 0: calc(v) print(n) calc(10)
就会发现代码输出为
5
2
1
0
1
2
5
10
调用alex的图片,他的原理是这样的
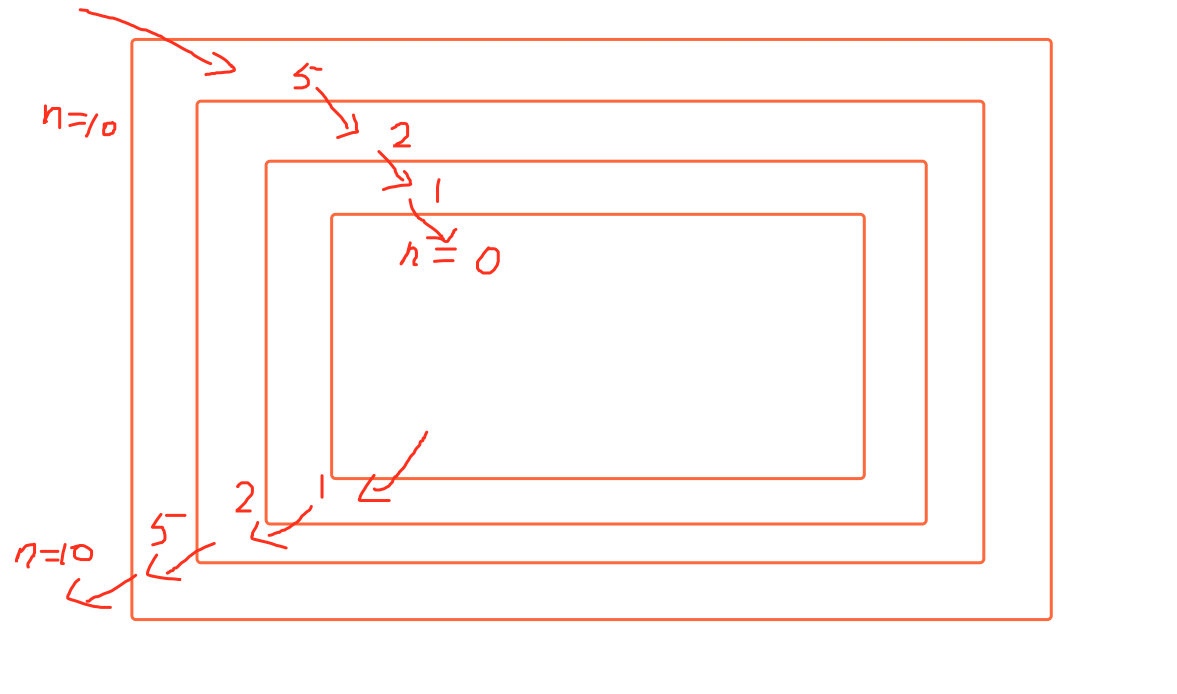 python限制递归的层数,最大层数是1000,虽然可以修改这个默认值,但是不建议,这样做可以保证计算机的内存资源不会爆掉
python限制递归的层数,最大层数是1000,虽然可以修改这个默认值,但是不建议,这样做可以保证计算机的内存资源不会爆掉
递归特性:
- 必须有一个明确的结束条件
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出
对于递归函数的确切用法,一般有广度查询以及深度查询
先看广度查询
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35] def binary_search(dataset,find_num): print(dataset) if len(dataset) >1: mid = int(len(dataset)/2) if dataset[mid] == find_num: #find it print("找到数字",dataset[mid]) elif dataset[mid] > find_num :# 找的数在mid左面 print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid]) return binary_search(dataset[0:mid], find_num) else:# 找的数在mid右面 print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid]) return binary_search(dataset[mid+1:],find_num) else: if dataset[0] == find_num: #find it print("找到数字啦",dataset[0]) else: print("没的分了,要找的数字[%s]不在列表里" % find_num) binary_search(data,66)
这就是一个典型的广度查询,先查看一半,如果没有则抛弃这一半,在另外一半查询,然后在调用函数,一层又一层,一直到找到特定的值。他的原理就是一直对折对折
在看深度查询,需求如下
menus = [ { 'text': '北京', 'children': [ {'text': '朝阳', 'children': []}, {'text': '昌平', 'children': [ {'text': '沙河', 'children': []}, {'text': '回龙观', 'children': []}, ]}, ] }, { 'text': '上海', 'children': [ {'text': '宝山', 'children': []}, {'text': '金山', 'children': [ {'text': 'wps', 'children': []}, {'text': '毒霸', 'children': []}, ]}, ] } ] # 深度查询 # 1.打印所有的节点 # 2.输入一个节点名字 # 沙河,你要遍历找,找到了,就打印ta,并返回True
代码如下
#打印所有的节点 def recurPrintPath(list): for key in list: print(key) if type(key) == type({}): for i in key.keys(): print(i) if type(key[i])==type([]): recurPrintPath(key[i]) recurPrintPath(menus)
#输入节点名字,找到了就打印,并返回true def recurPrintPath(list,input): for key in list: if key == input: print(input) print('True') else: if type(key) == type({}): for i,j in key.items(): if j == input: print(input) print('True') else: if type(key[i])== type([]): recurPrintPath(key[i],input) recurPrintPath(menus,'沙河')
10.函数内置办法

这些都是一些常用的内置函数,对于这些函数不懂其实可以使用python内置的函数help查看各种内置函数,看明白他的用法