文章目录
概述
Spark Streaming 支持多种实时输入源数据的读取,其中包括Kafka、flume、socket流等等,接下来将讲解SparkStreaming实时读取Kafka消息的方式
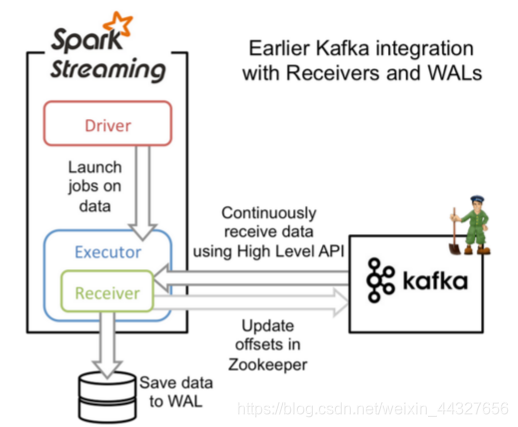
方式一:Approach 1: Receiver-based Approach(基于Receiver方式)
工作原理
基于 Receiver-based 的 createStream 方法。receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
代码实现
接下来,我们将讨论如何在流应用程序中使用这种方法。
- 引入依赖
groupId = org.apache.spark
artifactId = spark-streaming-kafka-0-8_2.11
version = 2.2.0
- 在流应用程序代码中,导入KafkaUtils并创建一个输入DStream
import org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
- 启动应用程序
./bin/spark-submit --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 ...
- 详细代码
/*读取kafka数据函数*/
def getKafkaInputStream(zookeeper: String,
topic: String,
groupId: String,
numRecivers: Int,
partition: Int,
ssc: StreamingContext): DStream[String] = {
val kafkaParams = Map(
("zookeeper.connect", zookeeper),
("auto.offset.reset", "largest"),
("zookeeper.connection.timeout.ms", "30000"),
("fetch.message.max.bytes", (1024 * 1024 * 50).toString),
("group.id", groupId)
)
val topics = Map(topic -> partition / numRecivers)
val kafkaDstreams = (1 to numRecivers).map { _ =>
KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](ssc,
kafkaParams,
topics,
StorageLevel.MEMORY_AND_DISK_SER).map(_._2)
}
ssc.union(kafkaDstreams)
}
其中
- zookeeper: ZooKeeper连接信息
- topic: Kafka中输入的topic信息
- groupId: consumer信息
- numReceivers: 打算开启的receiver个数, 并用来调整并发
- partition: Kafka中对应topic的分区数
优缺点
| 优点 | 操作简单方便,不用自己管理offset。 |
|---|---|
| 缺点 | 1. 可能会导致数据丢失,2. 导致资源严重浪费 |
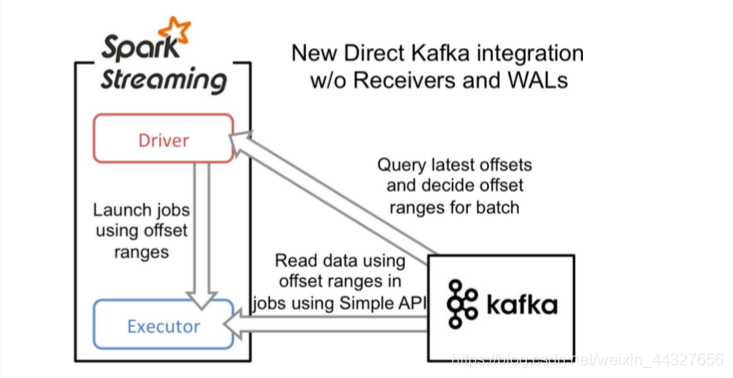
方式二:Approach 2: Direct Approach (No Receivers) (基于Direct方式)
工作原理
Direct Approach方式采用Kafka简单的consumer api方式来读取数据,无需经由ZooKeeper,此种方式不再需要专门Receiver来持续不断读取数据。当batch任务触发时,由Executor读取数据,并参与到其他Executor的数据计算过程中去。driver来决定读取多少offsets,并将offsets交由checkpoints来维护。将触发下次batch任务,再由Executor读取Kafka数据并计算。从此过程我们可以发现Direct方式无需Receiver读取数据,而是需要计算时再读取数据
代码实现
- 方法createDirectStream中,ssc是StreamingContext;kafkaParams的具体配置见Receiver-based之中的配置,与之一样;这里面需要指出的是fromOffsets ,其用来指定从什么offset处开始读取数据。
def createDirectStream[
K: ClassTag,
V: ClassTag,
KD <: Decoder[K]: ClassTag,
VD <: Decoder[V]: ClassTag,
R: ClassTag] (
ssc: StreamingContext,
kafkaParams: Map[String, String],
fromOffsets: Map[TopicAndPartition, Long],
messageHandler: MessageAndMetadata[K, V] => R
): InputDStream[R] = {
val cleanedHandler = ssc.sc.clean(messageHandler)
new DirectKafkaInputDStream[K, V, KD, VD, R](
ssc, kafkaParams, fromOffsets, cleanedHandler)
}
- 方法createDirectStream中,该方法只需要3个参数,其中kafkaParams还是一样,并未有什么变化,不过其中有个配置auto.offset.reset可以用来指定是从largest或者是smallest处开始读取数据;topic是指Kafka中的topic,可以指定多个。具体提供的方法代码如下:
def createDirectStream[
K: ClassTag,
V: ClassTag,
KD <: Decoder[K]: ClassTag,
VD <: Decoder[V]: ClassTag] (
ssc: StreamingContext,
kafkaParams: Map[String, String],
topics: Set[String]
): InputDStream[(K, V)] = {
val messageHandler = (mmd: MessageAndMetadata[K, V]) => (mmd.key, mmd.message)
val kc = new KafkaCluster(kafkaParams)
val fromOffsets = getFromOffsets(kc, kafkaParams, topics)
new DirectKafkaInputDStream[K, V, KD, VD, (K, V)](
ssc, kafkaParams, fromOffsets, messageHandler)
}
在实际的应用场景中,我们会将两种方法结合起来使用,大体的方向分为两个方面:
- 应用启动。当程序开发并上线,还未消费Kafka数据,此时从largest处读取数据,采用第二种方法;
- 应用重启。因资源、网络等其他原因导致程序失败重启时,需要保证从上次的offsets处开始读取数据,此时就需要采用第一种方法来保证我们的场景。
优缺点
| 优点 | 降低资源,降低内存,鲁棒性更好 |
|---|---|
| 缺点 | 略 |
案例
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange}
val conf: Conf = new config.Conf("test-util.conf")
val zkHost = conf.getString("kafka.zookeeper.connect")
val brokerList=conf.getString("kafka.metadata.broker.list")
val zkClient = new ZkClient(zkHost)
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokerList,
"zookeeper.connect" -> zkHost,
"group.id" -> "testid")
var kafkaStream: InputDStream[(String, String)] = null
var offsetRanges = Array[OffsetRange]()
val sc=SparkUtil.createSparkContext("test")
val ssc=new StreamingContext(sc,Seconds(5))
val topic="TEST_TOPIC"
val topicDirs = new ZKGroupTopicDirs("TEST_TOPIC_spark_streaming_testid", topic) //创建一个 ZKGroupTopicDirs 对象,对保存
val children = zkClient.countChildren(s"${topicDirs.consumerOffsetDir}") //查询该路径下是否字节点(默认有字节点为我们自己保存不同 partition 时生成的)
var fromOffsets: Map[TopicAndPartition, Long] = Map() //如果 zookeeper 中有保存 offset,我们会利用这个 offset 作为 kafkaStream 的起始位置
if (children > 0) { //如果保存过 offset,这里更好的做法,还应该和 kafka 上最小的 offset 做对比,不然会报 OutOfRange 的错误
for (i <- 0 until children) {
val partitionOffset = zkClient.readData[String](s"${topicDirs.consumerOffsetDir}/${i}")
val tp = TopicAndPartition(topic, i)
fromOffsets += (tp -> partitionOffset.toLong) //将不同 partition 对应的 offset 增加到 fromOffsets 中
}
val messageHandler = (mmd : MessageAndMetadata[String, String]) => (mmd.topic, mmd.message()) //这个会将 kafka 的消息进行 transform,最终 kafak 的数据都会变成 (topic_name, message) 这样的 tuple
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, fromOffsets, messageHandler)
}
else {
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, Set("TEST_TOPIC")) //如果未保存,根据 kafkaParam 的配置使用最新或者最旧的 offset
}
kafkaStream.transform{rdd=>
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //得到该 rdd 对应 kafka 的消息的 offset
rdd
}.map(_._2).foreachRDD(rdd=>{
for (o <- offsetRanges) {
val zkPath = s"${topicDirs.consumerOffsetDir}/${o.partition}"
ZkUtils.updatePersistentPath(zkClient, zkPath, o.fromOffset.toString) //将该 partition 的 offset 保存到 zookeeper
}
rdd.foreach(s=>println(s))
})
ssc.start()
ssc.awaitTermination()
调优
合理的批处理时间(batchDuration)
几乎所有的Spark Streaming调优文档都会提及批处理时间的调整,在StreamingContext初始化的时候,有一个参数便是批处理时间的设定。如果这个值设置的过短,即个batchDuration所产生的Job并不能在这期间完成处理,那么就会造成数据不断堆积,最终导致Spark Streaming发生阻塞。而且,一般对于batchDuration的设置不会小于500ms,因为过小会导致SparkStreaming频繁的提交作业,对整个streaming造成额外的负担。在平时的应用中,根据不同的应用场景和硬件配置
合理的Kafka拉取量(maxRatePerPartition重要)
配置参数为:spark.streaming.kafka.maxRatePerPartition。这个参数默认是没有上线的,即kafka当中有多少数据它就会直接全部拉出。而根据生产者写入Kafka的速率以及消费者本身处理数据的速度,同时这个参数需要结合上面的batchDuration,使得每个partition拉取在每个batchDuration期间拉取的数据能够顺利的处理完毕,做到尽可能高的吞吐量
缓存反复使用的Dstream(RDD)
Spark中的RDD和SparkStreaming中的Dstream,如果被反复的使用,最好利用cache(),将该数据流缓存起来,防止过度的调度资源造成的网络开销。
设置合理的GC
长期使用Java的小伙伴都知道,JVM中的垃圾回收机制,可以让我们不过多的关注与内存的分配回收,更加专注于业务逻辑,JVM都会为我们搞定。对JVM有些了解的小伙伴应该知道,在Java虚拟机中,将内存分为了初生代(eden generation)、年轻代(young generation)、老年代(old generation)以及永久代(permanent generation),其中每次GC都是需要耗费一定时间的,尤其是老年代的GC回收,需要对内存碎片进行整理,通常采用标记-清楚的做法。同样的在Spark程序中,JVM GC的频率和时间也是影响整个Spark效率的关键因素。在通常的使用中建议:
--conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC"
设置合理的CPU资源数
CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例如,很常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高(因为一个executor并不总能充分利用多核的能力),这个时候可以考虑让么个executor占用更少的core,同时worker下面增加更多的executor,或者一台host上面增加更多的worker来增加并行执行的executor的数量,从而增加CPU利用率。但是增加executor的时候需要考虑好内存消耗,因为一台机器的内存分配给越多的executor,每个executor的内存就越小,以致出现过多的数据spill over甚至out of memory的情况。
设置合理的parallelism
partition和parallelism,partition指的就是数据分片的数量,每一次task只能处理一个partition的数据,这个值太小了会导致每片数据量太大,导致内存压力,或者诸多executor的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降低。在执行action类型操作的时候(比如各种reduce操作),partition的数量会选择parent RDD中最大的那一个。而parallelism则指的是在RDD进行reduce类操作的时候,默认返回数据的paritition数量(而在进行map类操作的时候,partition数量通常取自parent RDD中较大的一个,而且也不会涉及shuffle,因此这个parallelism的参数没有影响)。所以说,这两个概念密切相关,都是涉及到数据分片的,作用方式其实是统一的。通过spark.default.parallelism可以设置默认的分片数量,而很多RDD的操作都可以指定一个partition参数来显式控制具体的分片数量。
使用高性能的算子
使用reduceByKey/aggregateByKey替代groupByKey
使用mapPartitions替代普通map
使用foreachPartitions替代foreach
使用filter之后进行coalesce操作
使用repartitionAndSortWithinPartitions替代repartition与sort类操作