基于YoloV3的实时摄像头记牌器
最终效果
数据准备
数据获取
从摄像头拍摄各种牌型的视频各20秒,不采用人工打标签,而是通过识别出牌的边缘,将牌经过仿射变换矫正,根据牌的实际宽高以及标注位置的实际宽高得到标注位置。通过随机生成背景图片,并且将牌在背景中随机旋转和平移,去掉标注部分被遮挡的生成图片,同时将label也做同样的变换,完成数据集的获取。
先定义好将识别到的卡片zoom到我们希望的宽高:
cardW=57#实际宽度
cardH=87#实际高度
cornerXmin=2 #牌的号码距左边的最小实际距离
cornerXmax=10.5 #牌的号码距左边的最大实际距离
cornerYmin=2.5 #牌的号码距上边的最小实际距离
cornerYmax=23 #牌的号码距上边的最大实际距离
# 下面通过一个zoom比例将真实的mm单位变换成了pixel单位
zoom=4 #变换比例
cardW*=zoom #变换之后的宽度
cardH*=zoom # 变换之后的高度
cornerXmin=int(cornerXmin*zoom) #...
cornerXmax=int(cornerXmax*zoom)#...
cornerYmin=int(cornerYmin*zoom)
cornerYmax=int(cornerYmax*zoom)
# 背景图像宽高
imgW=720
imgH=720加载backgrounds
class Backgrounds():
def __init__(self,backgrounds_pck_fn="/media/xueaoru/DATA/ubuntu/cards/backgrounds.pck"):
self._images=pickle.load(open(backgrounds_pck_fn,'rb'))
self._nb_images=len(self._images)
print("Nb of images loaded :", self._nb_images)
def get_random(self, display=False):
bg=self._images[random.randint(0,self._nb_images-1)]
if display: plt.imshow(bg)
return bg
backgrounds = Backgrounds()
创造mask用来存取卡片
bord_size=2 # 线宽
alphamask=np.ones((cardH,cardW),dtype=np.uint8)*255 #全白的图像mask
cv2.rectangle(alphamask,(0,0),(cardW-1,cardH-1),0,bord_size)#黑色举行画满mask
cv2.line(alphamask,(bord_size*3,0),(0,bord_size*3),0,bord_size)# 画一条斜线,就是四个角的斜线
cv2.line(alphamask,(cardW-bord_size*3,0),(cardW,bord_size*3),0,bord_size)
cv2.line(alphamask,(0,cardH-bord_size*3),(bord_size*3,cardH),0,bord_size)
cv2.line(alphamask,(cardW-bord_size*3,cardH),(cardW,cardH-bord_size*3),0,bord_size)
plt.figure(figsize=(10,10))#10cm高 10cm宽的 画板
plt.imshow(alphamask) # 在这个画板上显示alphamask图像
从一张图里提取卡
def varianceOfLaplacian(img):
"""
判断图像模糊度
"""
return cv2.Laplacian(img, cv2.CV_64F).var()
def extract_card (img, output_fn=None, min_focus=120, debug=False):
"""
"""
imgwarp=None
# 检查图像的模糊度
focus=varianceOfLaplacian(img)
print(focus)
if focus < min_focus:
if debug: print("Focus too low :", focus)
return False,None
# 变成灰度图
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 双边滤波降噪
gray=cv2.bilateralFilter(gray,11,17,17)
# Canny边缘检测
edge=cv2.Canny(gray,30,200)
# 在canny之后的图像中寻找Contour
_,cnts, _ = cv2.findContours(edge.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
#假定找到的轮廓具有最大确定卡片的轮廓,就是想找卡片的contour
cnt = sorted(cnts, key = cv2.contourArea, reverse = True)[0]
rect=cv2.minAreaRect(cnt)#得到cnt的最小外接矩形
box=cv2.boxPoints(rect)# 得到外界举行的四个点的坐标
box=np.int0(box)#将坐标转换为int0
areaCnt=cv2.contourArea(cnt)#计算cnt的面积
areaBox=cv2.contourArea(box)#计算外接矩形的面积
valid=areaCnt/areaBox>0.95#计算面积比
if valid:#如果面积比达到阈值
if wr>hr:
Mp=cv2.getPerspectiveTransform(np.float32(box),refCard)
else:
Mp=cv2.getPerspectiveTransform(np.float32(box),refCardRot)
# 利用透视变换将源图片里的card变换到实际图像zoom后的图像的位置对应的点的坐标(铺满整个画布)
imgwarp=cv2.warpPerspective(img,Mp,(cardW,cardH))# 之所以需要cardW和cardH是因为需要变换后的图像的size
# 添加一个Alpha层,A
imgwarp=cv2.cvtColor(imgwarp,cv2.COLOR_BGR2BGRA)
# cnt的shape是(n,1,2),type = int,我们需要将其reshape成(1,n,2),contour记录的只是坐标
cnta=cnt.reshape(1,-1,2).astype(np.float32)# 变成(1,n,2)是因为opencv里面要求的shape是这样
# cnta应用Mp变换
cntwarp=cv2.perspectiveTransform(cnta,Mp)
cntwarp=cntwarp.astype(np.int)
# 先将alpha通道的图像清空(透明)
alphachannel=np.zeros(imgwarp.shape[:2],dtype=np.uint8)
# 在alpha通道的cntwarp区域画出它
cv2.drawContours(alphachannel,cntwarp,0,255,-1)
# and操作是0就不添加,非0就覆盖掉
alphachannel=cv2.bitwise_and(alphachannel,alphamask)
# 添加alpha层到imgwarp
imgwarp[:,:,3]=alphachannel
# 保存图像
if output_fn is not None:
cv2.imwrite(output_fn,imgwarp)
if debug:
cv2.imshow("Gray",gray)
cv2.imshow("Canny",edge)
edge_bgr=cv2.cvtColor(edge,cv2.COLOR_GRAY2BGR)
cv2.drawContours(edge_bgr,[box],0,(0,0,255),3)
cv2.drawContours(edge_bgr,[cnt],0,(0,255,0),-1)
cv2.imshow("Contour with biggest area",edge_bgr)
if valid:
cv2.imshow("Alphachannel",alphachannel)
cv2.imshow("Extracted card",imgwarp)
return valid,imgwarp从多张图里提取卡
def extract_cards_from_video(video_fn, output_dir=None, keep_ratio=5, min_focus=120, debug=False):
if not os.path.isfile(video_fn):
print(f"Video file {video_fn} does not exist !!!")
return -1,[]
if output_dir is not None and not os.path.exists(output_dir):
os.makedirs(output_dir)
cap=cv2.VideoCapture(video_fn)
frame_nb=0
imgs_list=[]
while True:
ret,img=cap.read()
if not ret: break
if frame_nb%keep_ratio==0:
if output_dir is not None:
output_fn=give_me_filename(output_dir,"png")
else:
output_fn=None
#
valid,card_img = extract_card(img,output_fn,min_focus=min_focus,debug=debug)
if debug:
k=cv2.waitKey(1)
if k==27: break
if valid:
imgs_list.append(card_img)
frame_nb+=1
if debug:
cap.release()
cv2.destroyAllWindows()
return imgs_list
'''
Extracted images for As : 103
Extracted images for Ks : 94
Extracted images for Qs : 85
Extracted images for Js : 95
Extracted images for 10s : 89
Extracted images for 9s : 84
Extracted images for 8s : 97
Extracted images for 7s : 103
Extracted images for 6s : 96
Extracted images for 5s : 97
Extracted images for 4s : 103
Extracted images for 3s : 99
Extracted images for 2s : 97
Extracted images for Ah : 87
Extracted images for Kh : 108
Extracted images for Qh : 92
Extracted images for Jh : 98
Extracted images for 10h : 58
Extracted images for 9h : 129
Extracted images for 8h : 112
Extracted images for 7h : 107
Extracted images for 6h : 101
Extracted images for 5h : 110
Extracted images for 4h : 5
Extracted images for 3h : 47
Extracted images for 2h : 47
Extracted images for Ad : 130
Extracted images for Kd : 104
Extracted images for Qd : 94
Extracted images for Jd : 96
Extracted images for 10d : 72
Extracted images for 9d : 49
Extracted images for 8d : 65
Extracted images for 7d : 42
Extracted images for 6d : 61
Extracted images for 5d : 89
Extracted images for 4d : 98
Extracted images for 3d : 107
Extracted images for 2d : 97
Extracted images for Ac : 117
Extracted images for Kc : 107
Extracted images for Qc : 89
Extracted images for Jc : 92
Extracted images for 10c : 105
Extracted images for 9c : 100
Extracted images for 8c : 115
Extracted images for 7c : 99
Extracted images for 6c : 86
Extracted images for 5c : 99
Extracted images for 4c : 100
Extracted images for 3c : 96
Extracted images for 2c : 92
'''自动标注生成的样子

找到标注的凸包位置
def findHull(img, corner=refCornerHL, debug="no"):#corner指的是花色和牌值所在的位置的四个点的坐标
"""
Find in the zone 'corner' of image 'img' and return, the convex hull delimiting
the value and suit symbols
'corner' (shape (4,2)) is an array of 4 points delimiting a rectangular zone,
takes one of the 2 possible values : refCornerHL or refCornerLR
debug=
"""
kernel = np.ones((3,3),np.uint8)# 定义一个图像膨胀所需要的kernel大小(3,3)
corner=corner.astype(np.int)# 将参数corner转化为int类型操作
# 下面获取到corner的实际图像zoom后的坐标
x1=int(corner[0][0])
y1=int(corner[0][1])
x2=int(corner[2][0])
y2=int(corner[2][1])
w=x2-x1# zoom后的实际宽度
h=y2-y1# zoom后的实际高度
zone=img[y1:y2,x1:x2].copy()#copy这个区域到zone
strange_cnt=np.zeros_like(zone)#返回一个和zone shape一样的全0对象
gray=cv2.cvtColor(zone,cv2.COLOR_BGR2GRAY)# 将zone转化为黑白图像
thld=cv2.Canny(gray,30,200)# Canny找轮廓
thld = cv2.dilate(thld,kernel,iterations=1)# 对轮廓进行膨胀操作,迭代次数为1,目的使得原contour图像线条更浓
if debug!="no": cv2.imshow("thld",thld)
# 寻找contours
_,contours,_=cv2.findContours(thld.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
min_area=30 # 最小接收区域面积
min_solidity=0.3 # 最小接收面积比
concat_contour=None # 通过这个参数将所有的contour添加成一个contour,扩大范围
ok = True
for c in contours:
area=cv2.contourArea(c)# 计算该contour的面积,值更小
hull = cv2.convexHull(c)# 得到contour的凸包,凸包一般包含的比contour的区域要多一些
hull_area = cv2.contourArea(hull)#计算凸包的面积(一般面积更大)
solidity = float(area)/hull_area#计算一下面积比,应该是一个(0,1]的数
M=cv2.moments(c)# 计算轮廓的矩
cx=int(M['m10']/M['m00'])# 计算图像的重心x坐标
cy=int(M['m01']/M['m00'])# 计算图像重心y坐标
# abs(w/2-cx)<w*0.3 and abs(h/2-cy)<h*0.4 : TWEAK, the idea here is to keep only the contours which are closed to the center of the zone
if area >= min_area and abs(w/2-cx)<w*0.3 and abs(h/2-cy)<h*0.4 and solidity>min_solidity:# 满足实验测试的条件
if debug != "no" :
cv2.drawContours(zone,[c],0,(255,0,0),-1)
if concat_contour is None:
concat_contour=c# 如果是None就直接是contour本身
else:
concat_contour=np.concatenate((concat_contour,c))#经过上一步他已经不是None了,所以要添加上去
if debug != "no" and solidity <= min_solidity :
print("Solidity",solidity)
cv2.drawContours(strange_cnt,[c],0,255,2)
cv2.imshow("Strange contours",strange_cnt)
if concat_contour is not None:# 如果说找到了整体的contour
#通过合并后的contour把hull给确定出来
hull=cv2.convexHull(concat_contour)
hull_area=cv2.contourArea(hull)# 计算hull的面积
# 如果hull的面积太小或者太大,那都是有问题的,因此设置好实验阈值
min_hull_area=940
max_hull_area=2120
if hull_area < min_hull_area or hull_area > max_hull_area:
ok=False
if debug!="no":
print("Hull area=",hull_area,"too large or too small")
#我们上面得到的hull的坐标是在小矩形框图片也就是ROI图像中的坐标
#现在我们需要把这个坐标转换到实际图像zoom后的图像当中去
hull_in_img=hull+corner[0] #也就是 [cornerXmin,cornerYmin]
# 其实很简单,hull中每个x坐标加cornerXmin,每个y坐标加cornerYmin
else:
ok=False
if debug != "no" :
if concat_contour is not None:
cv2.drawContours(zone,[hull],0,(0,255,0),1)
cv2.drawContours(img,[hull_in_img],0,(0,255,0),1)
cv2.imshow("Zone",zone)
cv2.imshow("Image",img)
if ok and debug!="pause_always":
key=cv2.waitKey(1)
else:
key=cv2.waitKey(0)
if key==27:
return None
if ok == False:
return None
return hull_in_img
从全部视频中提取
imgs_dir="/home/xueaoru/视频/out_pics"# 图像路径
cards={}
for suit in card_suits:#每种花色
for value in card_values:# 每个value
card_name=suit + "_" + value# 拿到cardname的组合
card_dir=os.path.join(imgs_dir,card_name)# 得到对应花色对应值的文件夹名
if not os.path.isdir(card_dir):
print(f"!!! {card_dir} does not exist !!!")
continue
cards[card_name]=[]
for f in glob(card_dir+"/*.png"):# 拿到对应花色对应值的所有图片路径
img=cv2.imread(f,cv2.IMREAD_UNCHANGED)
hullHL=findHull(img,refCornerHL,debug="no")#利用上面的findHull函数得到上凸包
if hullHL is None:
print(f"File {f} not used.")
continue
hullLR=findHull(img,refCornerLR,debug="no") # 同理得到下凸包
if hullLR is None:
print(f"File {f} not used.")
continue
# We store the image in "rgb" format (we don't need opencv anymore)
# 将img转换为rgb格式
img=cv2.cvtColor(img,cv2.COLOR_BGRA2RGBA)
cards[card_name].append((img,hullHL,hullLR))# 对cards的每个花色和value对应的list添加img 左凸包 右凸包
print(f"Nb images for {card_name} : {len(cards[card_name])}")# 输出每种花色每种value得到了多少张可以操作的对象
print("Saved in :",cards_pck_fn)# 保存在设置好的pck文件中
pickle.dump(cards,open(cards_pck_fn,'wb'))# 输出保存
cv2.destroyAllWindows()定义aug
# imgaug具有的图像格式是keypoints,也就是kps
# 一个seq对象具有多个变换函数,可以对图像变换、keypoints变换等等
# 一张画布里面两张牌的情况
decalX=int((imgW-cardW)/2)
decalY=int((imgH-cardH)/2)
# 这个decalX和decalY使得card能够在画布的正中间
# 一张画布里面三张牌的情况
decalX3=int(imgW/2)
decalY3=int(imgH/2-cardH)
def kps_to_polygon(kps):
"""
把imgaug格式的kps(特征点)变成shapely的polygon
"""
pts=[(kp.x,kp.y) for kp in kps]
return Polygon(pts)
def hull_to_kps(hull, decalX=decalX, decalY=decalY):
"""
将hull变成imgaug的keypoints
"""
# hull的shape = (n,1,2)
kps=[ia.Keypoint(x=p[0]+decalX,y=p[1]+decalY) for p in hull.reshape(-1,2)]
kps=ia.KeypointsOnImage(kps, shape=(imgH,imgW,3))
return kps
def kps_to_BB(kps):
"""
通过keypoints确定图像中的Bbox
"""
extend=3 #
kpsx=[kp.x for kp in kps.keypoints] #取每个keypoints的kp的x值
minx=max(0,int(min(kpsx)-extend))# 左x
maxx=min(imgW,int(max(kpsx)+extend))#右x
kpsy=[kp.y for kp in kps.keypoints]#取每个keypoints的kp的y值
miny=max(0,int(min(kpsy)-extend))# 左y
maxy=min(imgH,int(max(kpsy)+extend)) # 右y
if minx==maxx or miny==maxy:# 面积为0的情况--返回
return None
else:
return ia.BoundingBox(x1=minx,y1=miny,x2=maxx,y2=maxy)# 否则返回一个Bbox
#定义一个整个zoom后的图像的keypoints的bbox,一张图的情况
cardKP = ia.KeypointsOnImage([
ia.Keypoint(x=decalX,y=decalY),#左上角的点
ia.Keypoint(x=decalX+cardW,y=decalY), #右上角的点
ia.Keypoint(x=decalX+cardW,y=decalY+cardH),#右下角的点
ia.Keypoint(x=decalX,y=decalY+cardH)#左下角的点
], shape=(imgH,imgW,3))
# 利用imgaug将一张画布一张图变换为一张画布两张图
transform_1card = iaa.Sequential([# 定义一个贯序的变换
iaa.Affine(scale=[0.65,1]),#缩放范围
iaa.Affine(rotate=(-180,180)),#旋转范围
iaa.Affine(translate_percent={"x":(-0.25,0.25),"y":(-0.25,0.25)}),#平移范围百分比
])
# 先分别对三张图片进行变换,然后统一进行一个变换
#对一张画布一张图
trans_rot1 = iaa.Sequential([#贯序模型(第一次变换)
iaa.Affine(translate_px={"x": (10, 20)}),#平移的x范围
iaa.Affine(rotate=(22,30))#旋转角度范围
])
trans_rot2 = iaa.Sequential([#贯序模型(第二次变换)
iaa.Affine(translate_px={"x": (0, 5)}),#平移范围
iaa.Affine(rotate=(10,15))#旋转角度范围
])
transform_3cards = iaa.Sequential([#定义一个三卡场景的变换
iaa.Affine(translate_px={"x":decalX-decalX3,"y":decalY-decalY3}),#左移cardW/2 上移cardH/2
iaa.Affine(scale=[0.65,1]),#缩放范围
iaa.Affine(rotate=(-180,180)),#旋转范围
iaa.Affine(translate_percent={"x":(-0.2,0.2),"y":(-0.2,0.2)})#平移范围百分比
])
scaleBg=iaa.Scale({"height": imgH, "width": imgW})#对背景进行缩放变换到画布的高宽
def augment(img, list_kps, seq, restart=True):# 变换函数(参数img是一张图像) 参数seq是变换方法,也就是上面定义的一种
"""
将seq作用在img和kps的list上
"""
while True:
if restart:
myseq=seq.to_deterministic()# 不deterministic的话每次变换都是一样的,不具有随机性
else:
myseq=seq
img_aug = myseq.augment_images([img])[0]#取图像变换后的img
list_kps_aug = [myseq.augment_keypoints([kp])[0] for kp in list_kps]# 对list kps进行变换
list_bbs = [kps_to_BB(list_kps_aug[1]),kps_to_BB(list_kps_aug[2])]# 将kps转化为bbox对象
valid=True
for bb in list_bbs:
if bb is None or int(round(bb.x2)) >= imgW or int(round(bb.y2)) >= imgH or int(bb.x1)<=0 or int(bb.y1)<=0:
valid=False
break
if valid: break
elif not restart:
img_aug=None
break
return img_aug,list_kps_aug,list_bbs
class BBA: # Bounding box + annotations
def __init__(self,bb,classname):
self.x1=int(round(bb.x1))
self.y1=int(round(bb.y1))
self.x2=int(round(bb.x2))
self.y2=int(round(bb.y2))
self.classname=classname
class Scene:
def __init__(self,bg,img1, class1, hulla1,hullb1,img2, class2,hulla2,hullb2,img3=None, class3=None,hulla3=None,hullb3=None):
if img3 is not None:
self.create3CardsScene(bg,img1, class1, hulla1,hullb1,img2, class2,hulla2,hullb2,img3, class3,hulla3,hullb3)
else:
self.create2CardsScene(bg,img1, class1, hulla1,hullb1,img2, class2,hulla2,hullb2)
def create2CardsScene(self,bg,img1, class1, hulla1,hullb1,img2, class2,hulla2,hullb2):#这里的img就是card
#kpsa1是img1的左上角的kps,其他同理
kpsa1=hull_to_kps(hulla1)
kpsb1=hull_to_kps(hullb1)
kpsa2=hull_to_kps(hulla2)
kpsb2=hull_to_kps(hullb2)
# 对传入的img1进行随机变换
self.img1=np.zeros((imgH,imgW,4),dtype=np.uint8)
self.img1[decalY:decalY+cardH,decalX:decalX+cardW,:]=img1
self.img1,self.lkps1,self.bbs1=augment(self.img1,[cardKP,kpsa1,kpsb1],transform_1card)
# 对img2进行随机变换.
# 如果img2经过变换后遮住的img1的一角,则重新变换
while True:
self.listbba=[]
#对img2进行随机变换
self.img2=np.zeros((imgH,imgW,4),dtype=np.uint8)
self.img2[decalY:decalY+cardH,decalX:decalX+cardW,:]=img2
self.img2,self.lkps2,self.bbs2=augment(self.img2,[cardKP,kpsa2,kpsb2],transform_1card)
#将img2变换之后的整个card区域的kps转换为polygon
mainPoly2=kps_to_polygon(self.lkps2[0].keypoints[0:4])
invalid=False
intersect_ratio=0.1#交叉比率阈值
for i in range(1,3):
# 将img1的左上角框定区域变换后转化为polygon
smallPoly1=kps_to_polygon(self.lkps1[i].keypoints[:])# 这里不取0是因为lkps[0]是cardKp变换后的结果
a=smallPoly1.area # 计算该区域面积
# 计算img2的polygon与img1的框定polygon的交集
intersect=mainPoly2.intersection(smallPoly1)
ai=intersect.area # 计算交集的面积,表示的是被覆盖掉的面积
if (a-ai)/a > 1-intersect_ratio: # 面积达到一定值,则break重新进行变换
self.listbba.append(BBA(self.bbs1[i-1],class1))
# 遮挡面积过大,重新变换
elif (a-ai)/a>intersect_ratio:
invalid=True
break
if not invalid: break
self.class1=class1# 第一张牌的class
self.class2=class2# 第二张牌的class
for bb in self.bbs2: # 对第二张牌的四个关键点遍历
self.listbba.append(BBA(bb,class2))
self.bg=scaleBg.augment_image(bg)# 执行背景变换
mask1=self.img1[:,:,3] #alpha层 img1 除了有牌的部分其他的全为0,包括alpha层
self.mask1=np.stack([mask1]*3,-1)# 堆三个alpha层出来w*h*channel(3)
self.final=np.where(self.mask1,self.img1[:,:,0:3],self.bg)# np.where 在mask1中非0位置从前景图中获取,0位置从bg中获取
mask2=self.img2[:,:,3]# 下面同理
self.mask2=np.stack([mask2]*3,-1)
self.final=np.where(self.mask2,self.img2[:,:,0:3],self.final)
def create3CardsScene(self,bg,img1, class1, hulla1,hullb1,img2, class2,hulla2,hullb2,img3, class3,hulla3,hullb3):
# 创建三张牌的场景,同理
kpsa1=hull_to_kps(hulla1,decalX3,decalY3)# 第一张牌左上角的keypoints
kpsb1=hull_to_kps(hullb1,decalX3,decalY3)# 第一张牌右上角的keypoints
kpsa2=hull_to_kps(hulla2,decalX3,decalY3)# 以此类推
kpsb2=hull_to_kps(hullb2,decalX3,decalY3)
kpsa3=hull_to_kps(hulla3,decalX3,decalY3)
kpsb3=hull_to_kps(hullb3,decalX3,decalY3)
self.img3=np.zeros((imgH,imgW,4),dtype=np.uint8)
self.img3[decalY3:decalY3+cardH,decalX3:decalX3+cardW,:]=img3
self.img3,self.lkps3,self.bbs3=augment(self.img3,[cardKP,kpsa3,kpsb3],trans_rot1)
self.img2=np.zeros((imgH,imgW,4),dtype=np.uint8)
self.img2[decalY3:decalY3+cardH,decalX3:decalX3+cardW,:]=img2
self.img2,self.lkps2,self.bbs2=augment(self.img2,[cardKP,kpsa2,kpsb2],trans_rot2)
self.img1=np.zeros((imgH,imgW,4),dtype=np.uint8)
self.img1[decalY3:decalY3+cardH,decalX3:decalX3+cardW,:]=img1
while True:
det_transform_3cards = transform_3cards.to_deterministic()
_img3,_lkps3,self.bbs3=augment(self.img3,self.lkps3,det_transform_3cards, False)
if _img3 is None: continue
_img2,_lkps2,self.bbs2=augment(self.img2,self.lkps2,det_transform_3cards, False)
if _img2 is None: continue
_img1,self.lkps1,self.bbs1=augment(self.img1,[cardKP,kpsa1,kpsb1],det_transform_3cards, False)
if _img1 is None: continue
break
self.img3=_img3
self.lkps3=_lkps3
self.img2=_img2
self.lkps2=_lkps2
self.img1=_img1
self.class1=class1
self.class2=class2
self.class3=class3
self.listbba=[BBA(self.bbs1[0],class1),BBA(self.bbs2[0],class2),BBA(self.bbs3[0],class3),BBA(self.bbs3[1],class3)]
self.bg=scaleBg.augment_image(bg)# 背景变换
mask1=self.img1[:,:,3]# img1的alpha层,除了牌部分其他全为0
self.mask1=np.stack([mask1]*3,-1)# mask1*3堆叠,RGB全为mask
self.final=np.where(self.mask1,self.img1[:,:,0:3],self.bg)#final图片mask1有值就是img1,否则就用bg
mask2=self.img2[:,:,3]
self.mask2=np.stack([mask2]*3,-1)
self.final=np.where(self.mask2,self.img2[:,:,0:3],self.final)
mask3=self.img3[:,:,3]
self.mask3=np.stack([mask3]*3,-1)
self.final=np.where(self.mask3,self.img3[:,:,0:3],self.final)
def display(self):
fig,ax=plt.subplots(1,figsize=(8,8))
ax.imshow(self.final)# 显示变换后的图片
for bb in self.listbba:# 每个bbox
rect=patches.Rectangle((bb.x1,bb.y1),bb.x2-bb.x1,bb.y2-bb.y1,linewidth=1,edgecolor='b',facecolor='none')
ax.add_patch(rect)# 在ax里面画出来
def res(self):
return self.final# 返回变换后的图片
def write_files(self,save_dir,display=False):
jpg_fn, xml_fn=give_me_filename(save_dir, ["jpg","xml"])# 保存
plt.imsave(jpg_fn,self.final)
if display: print("New image saved in",jpg_fn)
create_voc_xml(xml_fn,jpg_fn, self.listbba,display=display)

大功告成。
训练
训练这里简要说一下,下一篇博客详细说一说yolo的论文和代码。
训练使用的是pytorch开源的yolov3,照官网一步步配置就好了。训练代码的注释还没写完,下一篇补上所有注释和论文理解。
我是花了一天多时间train (RTX 2070),得到了best.pt。
github:https://github.com/ultralytics/yolov3
检测
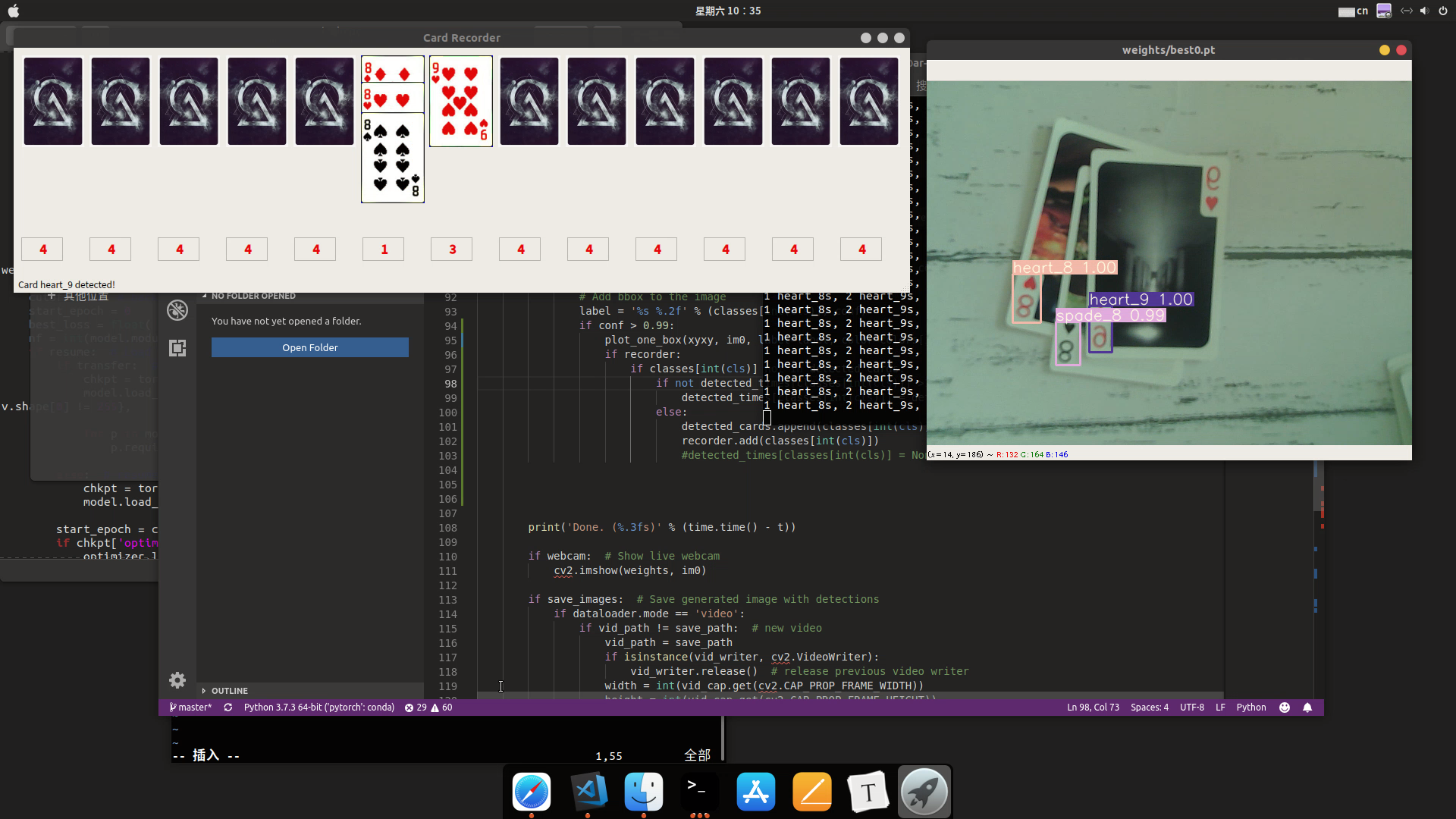
首先要做一个记牌器的界面,首选的当然是pyqt,半小时入门就写出来一个可应用的界面了,如图:
每检测一张图就在相应位置上插一张牌的图片就好了。
#...
if detections is not None and len(detections) > 0:
# Rescale boxes from 416 to true image size
scale_coords(img_size, detections[:, :4], im0.shape).round()
# Print results to screen
for c in detections[:, -1].unique():
n = (detections[:, -1] == c).sum()
print('%g %ss' % (n, classes[int(c)]), end=', ')
# Draw bounding boxes and labels of detections
for *xyxy, conf, cls_conf, cls in detections:
if save_txt: # Write to file
with open(save_path + '.txt', 'a') as file:
file.write(('%g ' * 6 + '\n') % (*xyxy, cls, conf))
# Add bbox to the image
label = '%s %.2f' % (classes[int(cls)], conf)
if conf > 0.99:
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)])
if recorder:
if classes[int(cls)] not in detected_cards:
if not detected_times[classes[int(cls)]] >10:
detected_times[classes[int(cls)]] = detected_times[classes[int(cls)]] + 1
else:
detected_cards.append(classes[int(cls)])
recorder.add(classes[int(cls)])
#detected_times[classes[int(cls)] = None
UI的代码不写上,太大了,都放在github上。
界面操作
import sys
from PyQt5.QtWidgets import QApplication,QMainWindow,QWidget,QMessageBox
from PyQt5 import QtCore
_translate = QtCore.QCoreApplication.translate
from card_recorder import *
class MyWindow(QMainWindow,Ui_MainWindow):
def __init__(self):
super(MyWindow,self).__init__()
self.setupUi(self)
def message(self):
reply = QMessageBox.information(self, #使用infomation信息框
"标题",
"消息",
QMessageBox.Yes | QMessageBox.No)
class Recorder():
def __init__(self,window):
self.window = window
self.cards = {
"card_3":[],
"card_4":[],
"card_5":[],
"card_6":[],
"card_7":[],
"card_8":[],
"card_9":[],
"card_10":[],
"card_j":[],
"card_q":[],
"card_k":[],
"card_a":[],
"card_2":[]
}
self.recg_cards = []
def add(self,card):# 給number,添加一張牌
number = card.split("_")[-1] # 3
self.window.statusbar.showMessage("Card {} detected!".format(card))
if not card in self.cards["card_{}".format(number)]:
idx = len(self.cards["card_{}".format(number)]) + 1
self.cards["card_{}".format(number)].append(card)
eval("self.window.label_{}_{}.setStyleSheet('image: url(:/cards/pukeImage/{}.jpg)')".format(number,idx,card))
eval("self.window.label_{}.setText(_translate('MainWindow', '<html><head/><body><p align=\"center\"><span style=\" font-size:12pt; font-weight:600; color:#ff0000;\">{}</span></p></body></html>'))".format(number,4-idx))
if __name__ == '__main__':
'''
主函数
'''
app = QApplication(sys.argv)
mainWindow = MyWindow()
mainWindow.show()
recorder = Recorder(mainWindow)
recorder.add("diamond_3")
recorder.add("diamond_4")
sys.exit(app.exec_())