抱着免笔试的心态参加了中兴捧月比赛,赛题一下来,呦!题目可选余地很大,稳了!看完题之后,凉了!再见,中兴。。。
正题开始,博主选的是智能音频识别,题目给了几段含有大量噪声的音频数据,要求参赛者对这些音频进行去噪增强,然后提交去噪后的音频,系统进行判别。该题目是较简单的,所以最后的成绩排名也是凶残无比,前80名得分都是90分以上,不服不行,对于我们这样现学现卖的果然只有陪跑的份,不过在这里还是把比赛中关于音频的学习过程做个总结吧,说不定面试有用呢?!
中兴捧月官网:http://challenge.zte.net/
预加重
对语音信号进行预加重的目的是为了去除口唇辐射的影响,增加语音的高频分辨率。预加重一般传递函数为所以我们可以使用一阶FIR高通滤波器实现预加重,其中a为预加重系数,通常可以取0.9 < a < 1.0,预加重后的频谱在高频部分的幅度得到了提升。预加重之后我听了一下音频,真的是好了很多,神奇的我不敢相信,结果提交判分得了个0分。。。。。unbelievable
语音信号的加窗处理
进行预加重数字滤波处理后,下面就是进行加窗分帧处理,语音信号具有短时平稳性(10--30ms内可以认为语音信号近似不变),这样就可以把语音信号分为一些短段来来进行处理,这就是分帧,语音信号的分帧是采用可移动的有限长度的窗口进行加权的方法来实现的。一般每秒的帧数约为33~100帧,视情况而定。一般的分帧方法为交叠分段的方法,前一帧和后一帧的交叠部分称为帧移,帧移与帧长的比值一般为0~0.5,。
窗函数一般使用汉明窗,函数如下:
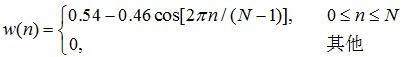

汉明窗的主瓣宽度较宽,是矩形窗的一倍,但是汉明窗的旁瓣衰减较大,具有更平滑的低通特性,能够在较高的程度上反应短时信号的频率特性。相比之下,矩形窗的主瓣宽度小于汉明窗,具有较高的频谱分辨率,但是矩形窗的旁瓣峰值较大,因此其频谱泄露比较严重。
谱减法去噪
谱减法是我使用的核心去噪方法,不同版本的谱减去噪效果有所差异,但效果都挺好。
谱减算法为最早的语音降噪算法之一,它的提出,基于一个简单的原理:假设语音中的噪声只有加性噪声,只要将带噪语音谱减去噪声谱,就可以得到纯净语音幅度。这么做的前提是噪声信号是平稳的或者缓慢变化的。
早期文献中的方法较为简单粗暴,公式如下:
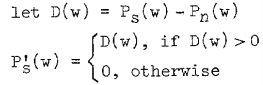
Ps(w)是输入的带噪语音的频谱,Pn(w)是估计出的噪音的频谱,两者相减得到D(w)差值频谱。由于相减后可能会出现负值,所以就简单粗暴地加上一个判断条件,将负值全部置为0,这样得到的结果作为最终输出去噪语音的频谱。
一个缺点就是由于我们估计噪音的时候取得平均值,那么有的地方噪音强度大于平均值的时候,相减后会有残留的噪音存在。在噪音波形谱上表现为一个一个的小尖峰,我们将这种残存的噪声称之为音乐噪声(music noise)从根本上,通常导致音乐噪声的原因主要有:
(1)对谱减算法中的负数部分进行了非线性处理
(2)对噪声谱的估计不准
(3)抑制函数(增益函数)具有较大的可变性
减小音乐噪声的方法是对噪声谱使用过减技术,同时对谱减后的负值设置一个下限,而不是将它们设为0,该方法将上面的公式进行了如下修改:
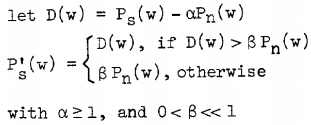
多了两个参数alpha 和 beta。alpha称之为相减因子,它主要影响语音谱的失真程度,beta称之为频谱下限阈值参数,可以控制残留噪声的多少以及音乐噪声的大小。alpha>1,这样可以保证相比于之前的方法能够有更强的去噪效果,能够去除大部分的噪声,这样残余的噪声就会少很多。但是同样的相减后差值如果为负值,这个负值也就会更大。老方法中是将负值直接设为0,这样残余噪音的峰值和0之间的差值还是较为显著,所以Berouti就想了一个办法,就是设置一个语音的下限值beta* Pn(w)。将相减后的幅值小于此下限值得统一设置为这个固定值,这个下限值其实也是宽带的噪音,只不过设置下限值的好处是残余峰值相比之下没有那么显著,从而减小了“音乐噪声”的影响。可以通过调整beta的值来调整这个宽带的噪声的强度。
使用过减因子与谱下限的动机在于:当从带噪语音谱中减去噪声谱估计的时候,频谱中会残留一些隆起的部分或谱峰,有些谱峰是宽带的,有些谱峰很窄,看起来像是频谱上的一个脉冲。通过对噪声谱的过减处理,我们可以减小宽带谱峰的幅度,有时还可以将其完全消除。但是仅仅这样还不够,因为谱峰周围可能还存在较深的谱谷。因此需要使用谱下限来“填充”这些谱谷。在高信噪比中,alpha应取小值;对低信噪比中,alpha建议取大值。Berouti等人做了大量实验来确定alpha与beta的最优值,在这里我们直接使用就可以了
参数的设置,根据输入信号的SNR做了大量实现来确定alpha和beta的值,最终给出的alpha随每一个音频帧的SNR的变换曲线是这样的:
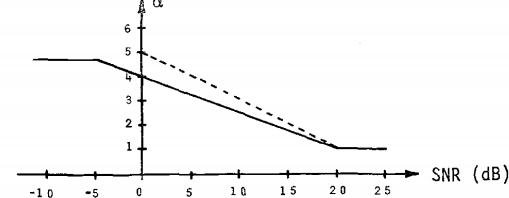
也就是说:alpha不能为一个固定值,需要根据每一个音频帧的信噪比大小来确定合适的值,这也是为什么要分帧的原因。计算alpha的公式如下,其中1/s为斜率,alpha0位期望的SNR为0时的值:
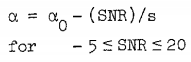
步骤:
- 读入语音数据,matlab有现成的函数waveread()。
- 设置好每帧的大小frameSize,每帧重叠大小windowOverlap等参数
- 对语音进行分帧处理,生成汉明窗hamming window,并且取前5帧估计噪声。
- 根据公式求出每一帧的去噪后的幅值sub_speech。
- 更新噪声的估计
- 从频域转换为时域,相位信息还是采用输入信号的相位。
- 输出最终去噪后的语音
function specsub(filename,outfile)
if nargin < 2
fprintf('Usage: specsub noisyfile.wav outFile.wav \n\n');
return;
end
[x,fs,nbits] = wavread(filename);
len = floor(20*fs/1000); % Frame size in samples
if rem(len,2) == 1, len=len+1; end;
PERC = 50; % window overlap in percent of frame size
len1 = floor(len*PERC/100);
len2 = len-len1;
Thres = 3; % VAD threshold in dB SNRseg
Expnt = 2.0; % 标志位,“1”表示幅度谱,“2”表示功率谱
beta = 0.002;
G = 0.9; %用于平滑噪声
win = hamming(len); %生成汉明窗
winGain = len2/sum(win); % normalization gain for overlap+add with 50% overlap
% 噪声幅度计算 - 假设前五帧音频是环境噪声
nFFT = 2*2^nextpow2(len);
noise_mean = zeros(nFFT,1);
j=1;
for k = 1:5
noise_mean = noise_mean+abs(fft(win.*x(j:j+len-1),nFFT));%win.*x(j:j+len-1)用汉明窗分帧
j = j+len;
end
noise_mu = noise_mean/5;%求得平均噪声
%--- allocate memory and initialize various variables
k = 1;
img = sqrt(-1);
x_old = zeros(len1,1);
Nframes = floor(length(x)/len2)-1;
xfinal = zeros(Nframes*len2,1);
%========================= Start Processing ===============================
for n = 1:Nframes
insign = win.*x(k:k+len-1); % 分帧,取帧
spec = fft(insign,nFFT); % 计算每帧音频的频谱
sig = abs(spec); % 频域幅值
%save the noisy phase information
theta = angle(spec); %计算相位角
SNRseg = 10*log10(norm(sig,2)^2/norm(noise_mu,2)^2);%信噪比
if Expnt == 1.0 % 幅度谱
alpha = berouti1(SNRseg);
else
alpha = berouti(SNRseg); % 功率谱,alpha会根据每一帧的SNR取不同的值
end
sub_speech = sig.^Expnt - alpha*noise_mu.^Expnt;%进行谱减
diffw = sub_speech - beta*noise_mu.^Expnt; % 计算纯净信号与噪声信号的功率的差值
% beta negative components
z = find(diffw <0);
if~isempty(z) % % 当纯净信号小于噪声信号的功率时
sub_speech(z) = beta*noise_mu(z).^Expnt; % 用估计出来的噪声信号表示下限值
end
% --- implement a simple VAD detector --------------
if (SNRseg < Thres) %如果信噪比低于阈值,更新噪声谱
noise_temp = G*noise_mu.^Expnt+(1-G)*sig.^Expnt; % 平滑处理噪声功率谱
noise_mu = noise_temp.^(1/Expnt); % 新的噪声幅度谱
end
% flipud函数实现矩阵的上下翻转,是以矩阵的“水平中线”为对称轴,交换上下对称元素
sub_speech(nFFT/2+2:nFFT) = flipud(sub_speech(2:nFFT/2));
x_phase = (sub_speech.^(1/Expnt)).*(cos(theta)+img*(sin(theta)));
% take the IFFT
xi = real(ifft(x_phase));%谱减后的纯净信号作反傅里叶变换
% 将每一帧重新拼接在一起
xfinal(k:k+len2-1)=x_old+xi(1:len1);
x_old = xi(1+len1:len);
k = k+len2;
end
function a = berouti1(SNR)
if SNR >= -5.0 & SNR <= 20
a = 3-SNR*2/20;
else
if SNR < -5.0
a = 4;
end
if SNR > 20
a = 1;
end
end
function a = berouti(SNR)
if SNR >= -5.0 & SNR <= 20
a = 4-SNR*3/20;
else
if SNR < -5.0
a = 5;
end
if SNR > 20
a = 1;
end
endfrom:https://blog.csdn.net/leixiaohua1020/article/details/47276353
from:https://blog.csdn.net/weixin_40398288/article/details/78500278
上面的方法中,谱减参数alpha和beta通过实验确定,无论如何都不会是最优的选择。MMSE谱减法能够在均方意义下最优地选择谱减参数。具体请参考论文:A parametic formulation of the generalized spectral subtractor method
MMSE-LSA算法实现步骤
1、对带噪信号分帧,加窗(这里是汉明窗)
2、对每帧带噪信号计算FFT :
3、估计后验信噪比 :
在非语音片段(语音开始之前几帧或语音间隙)估计的噪声能量谱;然后用判决引导法估计先验信噪比;
4、用最优的MMSE-LSA估计器的公式估计增强信号幅度;
5、重建增强信号谱,然后计算增强信号谱的IFFT,得到对应输入语音帧的增强的时域信号x(n)。
function logmmse(filename,outfile)
% Implements the logMMSE algorithm [1].
% Usage: logmmse(noisyFile, outputFile)
% infile - noisy speech file in .wav format
% outputFile - enhanced output file in .wav format
% Example call: logmmse('sp04_babble_sn10.wav','out_log.wav');
if nargin<2
fprintf('Usage: logmmse(noisyfile.wav,outFile.wav) \n\n');
return;
end
[x, Srate, bits]= wavread( filename); %nsdata is a column vector
% =============== Initialize variables ===============
len=floor(20*Srate/1000); % Frame size in samples
if rem(len,2)==1, len=len+1; end;
PERC=50; % window overlap in percent of frame size
len1=floor(len*PERC/100);
len2=len-len1;
win=hamming(len); % 定义汉明窗
% 噪声幅度计算,假定前6帧为环境噪声
nFFT=2*len;
noise_mean=zeros(nFFT,1);
j=1;
for m=1:6
noise_mean=noise_mean+abs(fft(win.*x(j:j+len-1),nFFT));
j=j+len;
end
noise_mu=noise_mean/6;
noise_mu2=noise_mu.^2;
%--- allocate memory and initialize various variables
x_old=zeros(len1,1);
Nframes=floor(length(x)/len2)-floor(len/len2);
xfinal=zeros(Nframes*len2,1);
%====================== Start Processing ==================
k=1;
aa=0.98;
mu=0.98;
eta=0.15;
ksi_min=10^(-25/10); %最小先验SNR
for n=1:Nframes
insign=win.*x(k:k+len-1);%分帧,取帧
spec=fft(insign,nFFT);
sig=abs(spec); % 计算信号幅度
sig2=sig.^2; %幅值平方
gammak=min(sig2./noise_mu2,40); % limit post SNR ,限制SNR以避免溢出
if n==1 %如果是第一帧
ksi=aa+(1-aa)*max(gammak-1,0);
else
ksi=aa*Xk_prev./noise_mu2 + (1-aa)*max(gammak-1,0); % 计算先验SNR
ksi=max(ksi_min,ksi); % limit ksi to -25 dB
end
log_sigma_k= gammak.* ksi./ (1+ ksi)- log(1+ ksi); %gammak是后验信噪比
vad_decision= sum(log_sigma_k)/ len;
if (vad_decision< eta)
% noise only frame found
noise_mu2= mu* noise_mu2+ (1- mu)* sig2;
end
% ===end of vad===
A=ksi./(1+ksi); % Log-MMSE estimator
vk=A.*gammak; %比例*后验SNR
ei_vk=0.5*expint(vk);
hw=A.*exp(ei_vk);
sig=sig.*hw; %对信号进行增强
Xk_prev=sig.^2;
xi_w= ifft( hw .* spec,nFFT);
xi_w= real( xi_w);
xfinal(k:k+ len2-1)= x_old+ xi_w(1:len1);
x_old= xi_w(len1+ 1: len);
k=k+len2;
end
ksi=aa*Xk_prev./noise_mu2 + (1-aa)*max(gammak-1,0); % 计算先验SNR,aa是平滑系数,一般取0.98,公式:

具体可参考:基于对数MMSE的语音增强算法
在这里推荐一个MATLAB语音处理的工具箱:VOICEBOX
voicebox是一个MATLAB中的语音处理工具箱,支持MATLAB6.5以上的版本。其中包含了对语音的分帧处理,滤波,加窗,参数提取等等函数,是语音识别几乎不可缺少的一个工具箱。网站:http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html
这个网站包括了voicebox的介绍和下载包 。
说明文档:http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html#enhance
还有基于RNN网络的去噪处理,我就不多介绍了,毕竟我的领域是图像,而不是音频。。。