## 对于入门学习Hadoop来说,布置单节点Hadoop即可,无需布置Hadoop集群,避免因配置问题而产生不必要的麻烦
## 我用的是Win10系统并用xshell远程连接CentOS7,用户名是hadoop,虚拟机是VMware14 pro,Hadoop选择CDH(cloudera)的发行版而非Apache Hadoop,如果用Apache Hadoop可能会和Hive产生冲突,所以下面文章都是以上述配置为例,各个Linux,Hadoop发行版都大同小异,所以这些配置方法其它选用发行版的读者也能参考这篇文章。
一. 远程连接虚拟机中的Linux
-
打开服务器/Linxu终端查看IP地址
本机需要ssh连接远程的Linux服务器进行远程操作时,首先要在Linux中查出虚拟机所分配的IP地址,命令:ifconfig
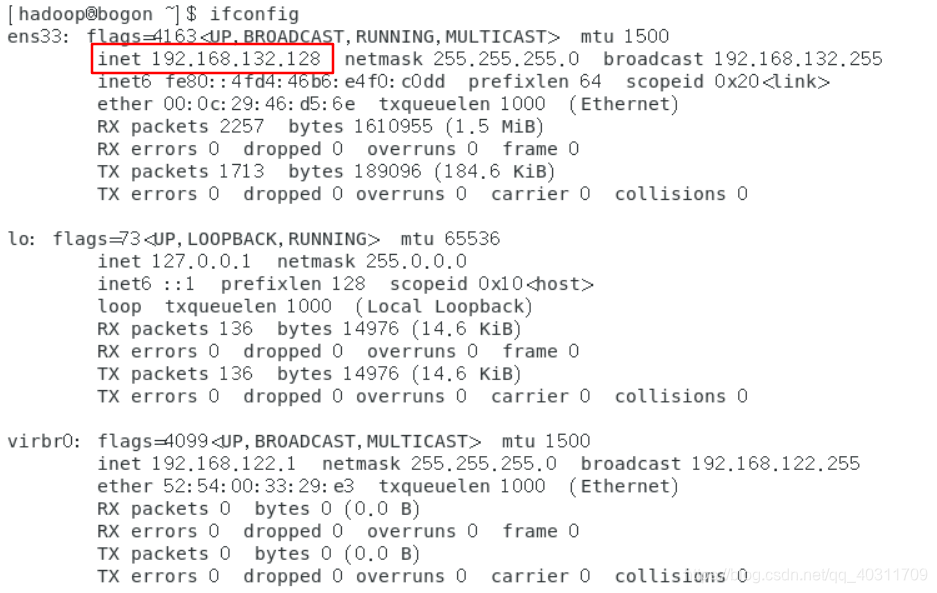
-
选择合适的shell软件,用于连接Linux服务器
Windows:xshell,secureCRT,PuTTY
Mac:可以用Mac自带的shell,Mac的操作系统是基于Unix的,所以跟Linux命令也比较相像,可在Mac电脑的Launchpad的其他中找到,也可按下command + 空格打开聚焦搜索后输入终端。
-
打开xshell后,输入命令
ssh [用户名称]@[ip地址]

-
为了今后方便查找安装相关文件,创建所需要的目录(可选择自己喜欢的方式存放)
$ mkdir software #存放软件安装包 $ mkdir app #存放安装目录 $ mkdir data #存放数据 $ mkdir lib #存放开发过的作业jar存放的目录 $ mkdir shell #存放相关的脚本 $ mkdir maven_resp #maven依赖包存放的目录
二. Hadoop环境搭建
-
下载Hadoop
使用的Hadoop相关版本:CDH
CDH相关软件包下载地址:http://archive.cloudera.com/cdh5/cdh/5/
Hadoop使用版本:hadoop-2.6.0-cdh5.15.1
Hadoop下载到Linux服务器:wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.15.1.tar.gz
Hive使用版本:hive-1.1.0-cdh5.15.1
可以下载到Windows本地再通过本地上传到服务器也可以直接在Linux上通过wget命令下载若是下载到Windows本地,则需要在CentOS中安装Irzsz。
相关教程可以参考: https://blog.csdn.net/weixin_40910753/article/details/79282557
三. 安装Java环境
因为Hadoop的源码是Java编写的,所以运行Hadoop之前必须配置好Java环境
jdk1.8.0_192.tar.gz下载:https://www.oracle.com/technetwork/java/javase/downloads/java-archive-javase8-2177648.html
- 记得本博客软件都将下载到~/software/目录下,并解压至 ~/app/目录下
sudo tar -zxvf jdk-8u192-linux-x64.tar.gz -C ~/app/
- 把jdk配置系统环境变量中:
sudo vi ~/.bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_192
export PATH=$JAVA_HOME/bin:$PATH
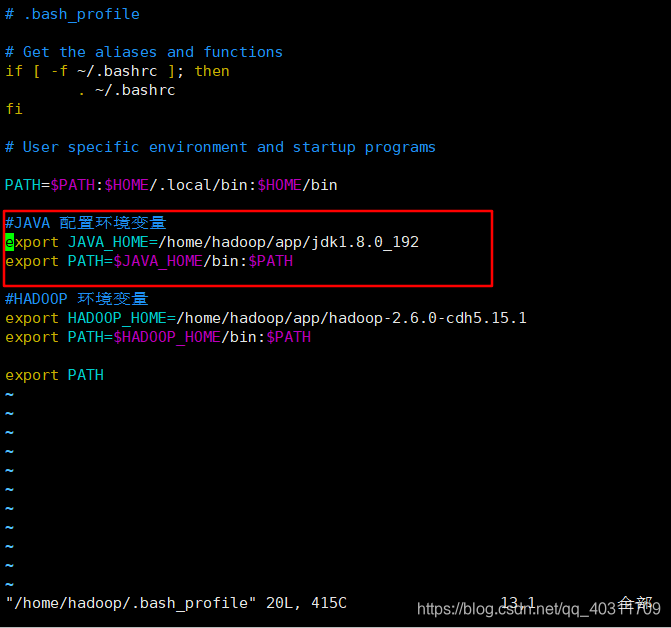
快速保存并退出:ESC -> shift + ZZ
bash_profile 如果不存在直接导入配置变量即可
- 使得配置修改生效:
source .bash_profile - 验证:
java -version
javac -version
echo $JAVA_HOME

四. 避免ssh连接时多次输入密码,需要将ssh设置为无密码登陆
ssh-keygen -t rsa 输入均为空,只按回车就行
将公钥放入其它连接本地时访问的文件authorized_keys
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
五. Hadoop(HDFS)安装
除了下载,解压外,还需要把HADOOP_HOME环境变量导入bash_profile文件中(见上图)
hadoop单节点搭建需要配置的文件有:
| 配置文件 | 配置内容 |
|---|---|
| hadoop-env.sh | export JAVA_HOME=/home/hadoop/app/jdk1.8.0_192 |
| core-site.xml | <property><name>fs.defaultFS</name><value>hdfs://hadoop000:8020</value></property>端口是8020 |
| hdfs-site.xml | <property><name>dfs.replication</name><value>1</value></property>默认副本调为1 |
hadoop配置文件基本都在 ${HADOOP_HOME}/etc/中
启动HDFS
- 第一次启动时一定要格式化文件系统,且不要重复执行:
hdfs namenode -format
格式化文件系统会删除默认的临时文件夹中的数据,我们把他放在其它目录下,例如:~/app/中创建一个tmp文件,并且还得把hdfs-site.xml文件再次配置:
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/tmp</value>
</property>
- 启动集群:
$HADOOP_HOME/sbin/start-dfs.sh
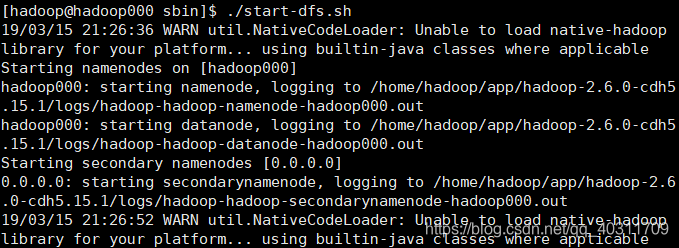
图中的警告可以暂时不管,当启动成功后不会报错
如果启动失败,需要到${HADOOP_HOME}/logs/中查找日志找问题,但是需要注意的是日志并不在图中的.out文件,而是.log文件
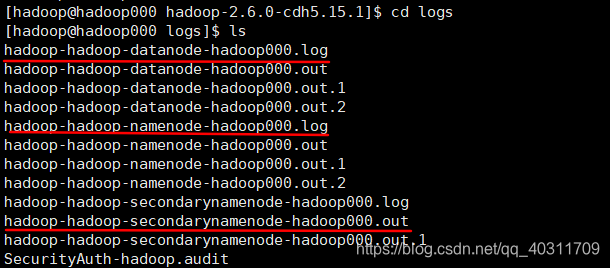
启动成功后至少有3项:
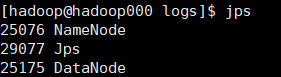
SecondaryNameNode 在Hadoop2.x中好像可以不用启动
我们可以验证一下:打开游览器,输入http://192.168.132.128:50070,回车…

如果是无法访问,那么最有可能的原因时hadoop的防火墙没有关,那么我们不妨来查看一下:
sudo firewall-cmd --state

**running !**防火墙开着那我们把他关掉(暂时的,重启后还会打开)
sudo systemctl stop firewalld.service

再次输入http://192.168.132.128:50070 出现节点信息说明成功启动

探索hdfs启动文件
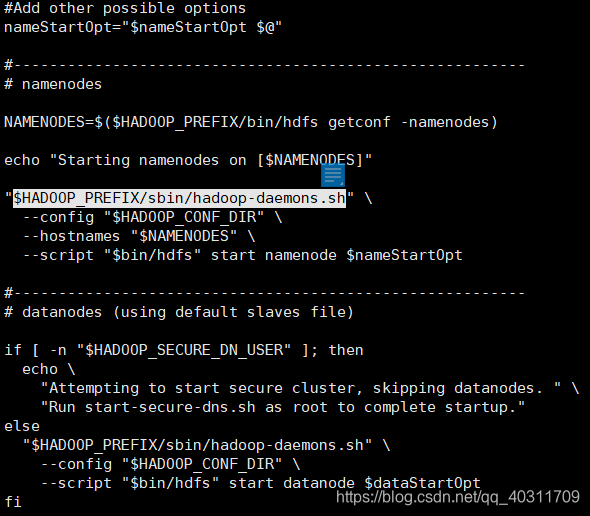
此时,当我打开查看启动文件start-dfs-sh文件时发现:每个启动项都有配置的变量,不变的时/sbin/hadoop-daemons.sh文件,所以不难想象如果是单独使用这个启动,是不是就只能启动单独的节点。

运行后确实如此:
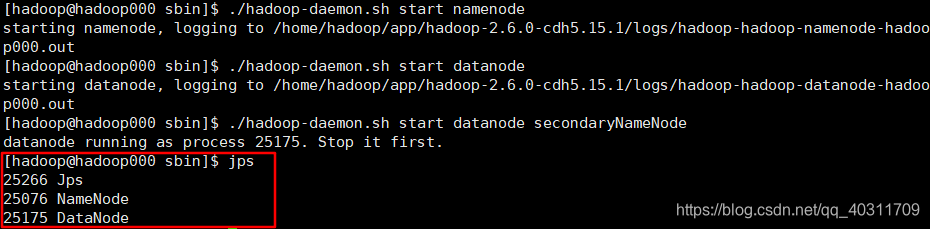
可以说:start-dfs.sh =
hadoop-daemons.sh start namenode + hadoop-daemons.sh start datanode + hadoop-daemons.sh start secondarynamenode
关闭hdfs也是相同的
-
hadoop软件包常见目录说明
| 目录 | 说明 |
|---|---|
| bin | hadoop客户端名单 |
| etc/hadoop | hadoop相关的配置文件存放目录 |
| sbin | 启动hadoop相关进程的脚本 |
| share | 常用例子 |
到这Hadoop(HDFS)的单节点为分布式搭建就完成了,后面会更新MapReduce,YARN等配置方法