什么是链表?
链表是一种物理存储上非连续、非顺序的存储结构。数据元素的逻辑顺序是通过链表中的指针链接次序实现的。就好比是班里的同学的学号、每个同学上课所坐的位置坑都不是固定的,但是通过他们之间学号的连续性,通过1号可以找到2号同学,链表就是这样,不仅存储了数值,还存储着下一个元素的地址
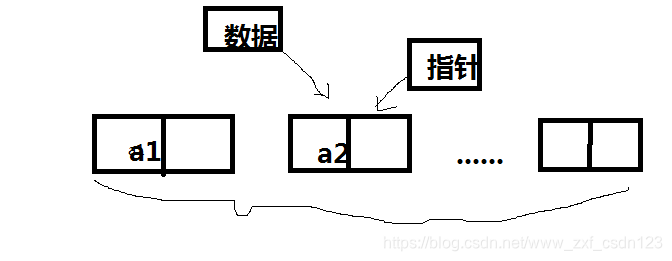
链表的基本操作有:初始化、销毁、增、删、改、查
首先给出链表结构体:
typedef struct Node{
int value;
struct Node* next;
}Node;
1、链表初始化`
void SListInit(Node** ppFirst)
{
*ppFirst = NULL;
}
链表初始化就是将整个链表置空
2、链表销毁
void SListDestroy(Node* first)
{
Node* next;
for (Node* cur = first; cur != NULL; cur = next)
{
next = cur->next;
free(cur);
}
}
链表销毁就是将链表中每个元素所占用的空间都释放掉,这里用到遍历。
3、链表头插(插入的操作都要先申请空间)
void SListPushFront(Node** ppFirst,int v)
{
Node* node = (Node*)malloc(sizeof(Node));
node->value = v;
node->next = *ppFirst;
*ppFirst = node;
}
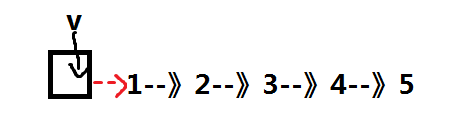
链表头插就是首先申请一个盒子(空间),把需要插入的数据,这里是v放入到盒子里,然后把这个盒子插入到链表中的第一个位置,需要变化的地方有*ppFirst,第一个元素的值,新插入的盒子的next此时指向了(*ppFirst)。
时间复杂度为O(1),这个我就不说明原因啦,有不懂得小伙伴们可以留言哦
4、链表头删
void SListPopFront(Node** ppFirst)
{
assert(*ppFirst != NULL);
Node* next = (*ppFirst)->next;
free(*ppFirst);
*ppFirst = next;
}
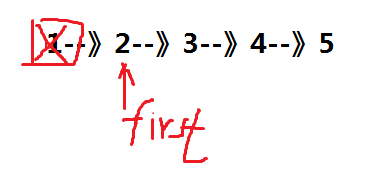
看代码,为什么首先要将第二个结点保存起来,原因是如果不事先将其保存下来的话,释放到第一个结点的空间后,就找不到第二个结点了。时间复杂度也是O(1)
5、链表的尾插
void SListPushBack(Node** ppFirst, int v)
{
Node* node = (Node*)malloc(sizeof(Node));
node->value = v;
if (*ppFirst == NULL)
{
node->next = *ppFirst;
*ppFirst = node;
return;
}
Node* cur = *ppFirst;
while (cur->next != NULL)
{
cur = cur->next;
}
cur->next = node;
node->next = NULL;
}
链表尾插需要考虑链表中一个结点都没有的情况,其实链表中没有结点的头插就相当于尾插。尾插需要遍历整个链表,因为要找到最后一个结点,然后用最后一个结点的next指向新插入的结点,前提当然是先申请这个盒子用于存储需要尾插的那个数。走出while循环的cur就是最后一个结点。最后让新插入结点的next等于NULL。
6、链表尾删
void SListPopBack(Node** ppFirst)
{
assert(*ppFirst != NULL);
if ((*ppFirst)->next == NULL)
{
free(*ppFirst);
*ppFirst = NULL;
return;
}
Node* cur = *ppFirst;
while (cur->next->next != NULL)
{
cur = cur->next;
}
free(cur->next);
cur->next = NULL;
}
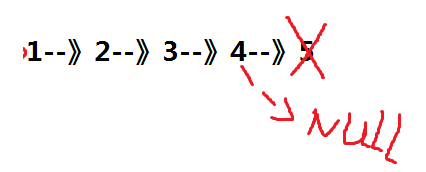
链表尾删也需要考虑链表中只有一个结点的情况,如果链表中只有一个结点就相当于头删,这里也需要遍历,找到倒数第二个结点,cur->next->next就表示倒数第二个结点,走出循环时就说明cur此时就是倒数第二个结点。让cur->next指向NULL。