并发编程的模型
并发模型分为三种:
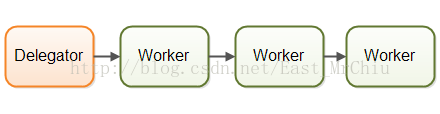
并行工作者模型

委派者(Delegator)将作业分配给不同的工作者(Worker)。每个工作者完成整个任务。工作者们并行运作在不同的线程上。
举个例子,果园收获苹果,每一棵树的采摘流程只由一个工人负责,即摘下,收装打包,上货等等,然后所有工人一起开始动手。这就是并行工作者模式。
优点:简单容易理解,只需要添加更多的线程来提高系统的并行度。
缺点:
共享数据问题
线程需要以某种方式存取共享数据,确保某个线程的修改能够对其它线程可见,即数据修改需要同步到主存中,不仅是将数据保存在执行这个线程的CPU的缓存中。线程需要避免竞态(竞争访问同一块数据的状态),死锁等并发问题。并且,线程之间的互相等待会丢失部分的并行性。所以高竞态会导致执行出现一定程度的串行性。
无状态的工作者
共享数据能够被其它线程修改,所以工作者在每次需要的时候必须重读状态,确保每次都能访问到最新的副本,无论共享状态是保存在内存中的还是外部数据库中。工作者无法在内部保存这个状态(每次需要重读)称为无状态的。然而,每次重读需要的数据,或导致速度变慢。
任务顺序的不确定性
非确定性并发,任何一个线程都有最先开始执行的可能。处理不当还可能造成线程饥饿。
流水线模式
与并行工作者中每个任务由一个Worker负责不同,流水线模式如同其名称,流水线,顾名思义,就是每个线程只负责任务的中的一部分,然后扭转下去给下一个去完成另外的其中一部分。
举个例子,还是果园收获果子,这个一部分工人只负责摘下,一部分工人只负责收装打包,一部分工人只负责上货等等,这样就属于按照采摘流程进行并发。
这种并发模式也被称为无共享并行模式。
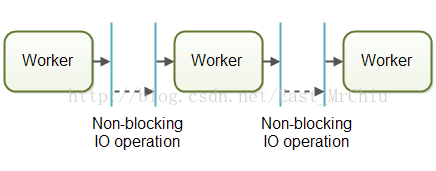
通常使用非阻塞的IO来设计使用流水线并发模型。非阻塞IO意味着,一旦某个工作者开始一个IO操作的时候(比如读取文件或从网络连接中读取数据),这个工作者不会一直等待IO操作的结束。IO操作速度很慢,所以等待IO操作结束很浪费CPU,此时CPU可以做一些其它事情。当IO操作完成的时候,IO操作的结果(比如读出的数据或数据写完的状态)被传递给下一个工作者。
有了非阻塞IO,就可以使用IO操作确定工作者之间的边界。工作者会尽可能运行知道遇到并启动一个IO操作,然后交出作业的控制权。当IO操作完成的时候,在流水线上的下一个工作者继续操作,直到它也遇到并启动一个IO操作。
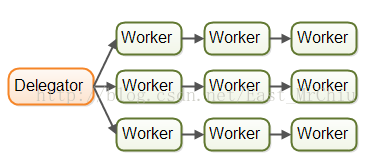
实际工作中也可以有多条流水线,形成方阵处理:
或者一个工作者扭转给多个下一个工作者:
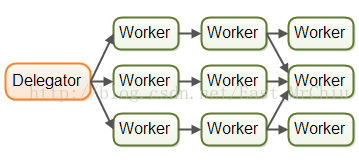
流水线并发模型也叫做事件驱动系统,即通过对出现的事件做出反应,这个事件可以是来自系统内部,也可以是来自系统外部,可以是传入的HTTP请求,也可以是文件加载进内存等等。有很多有趣的反应器/事件驱动平台可以使用,例如:Vert.x,AKKa,Node.JS(JavaScript)。
Actors和Channels
Actors和Channels是两种比较类似的流水线模型。
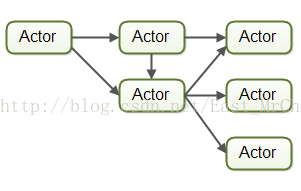
Actors中的每个工作者称为actor,actor之间可以直接异步发送和处理消息:
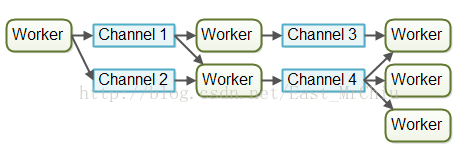
Channels(顾名思义,渠道,沟渠),所以它里面的工作者并不互相通信,而是通过特定不同的渠道,发布自己的消息,而其他工作者监听这个渠道的消息就行了,监听者不用管谁是消息发布者,消息发布者也不用管谁是监听者:
流水线并发模型的优点:
无需共享的状态:因为工作者之间是流水线模式,所以之间没有共享资源状态,这样就不用考虑并发带来的共享资源问题。流水线并发模型从另外一个角度看,也可以视作是单线程。
有状态的工作者:对比与并行者模型的无状态工作者,这里的有状态是指工作者知道自己使用的资源,不会被其他线程所改变,这样工作者可以将内容保存在内存中进行操作,只需要在最后一次将数据写回存储系统。相比无状态工作者里的时刻要将数据写回存储系统,性能要提高很多。
合理的作业顺序:基于流水线模型的并发是有可能保证作业的顺序性,而作业的顺序性可以更容易控制和判断系统运行到某一步时的状态,然后将相关信息写进日志中,万一系统再某一步挂掉了,可以通过日志记录的状态,重新建立系统当时的状态,建立有保障的作业。
缺点:作业的执行往往分布到多个工作者上,并因此分布到项目中的多个类上。这样导致在追踪某个作业到底被什么代码执行时变得困难。同样,加大了代码编写的难度。有时会将工作者的代码写成回调处理的形式。若在代码中嵌入过多的回调处理,往往会出现所谓的回调地狱(callback hell)现象。
(所谓回调地狱,就是意味着在追踪代码在回调过程中到底做了什么,以及确保每个回调只访问它需要的数据的时候,变得非常困难)
函数式并行
函数式并行的基本思想是采用函数调用实现程序。函数可以看作是”代理人(agents)“或者”actor“,函数之间可以像流水线模型那样互相发送消息。某个函数调用另一个函数,这个过程类似于消息发送。函数都是通过拷贝来传递参数的,所以除了接收函数外没有实体可以操作数据。这对于避免共享数据的竞态来说是很有必要的。同样也使得函数的执行类似于原子操作。每个函数调用的执行独立于任何其他函数的调用。
一旦每个函数调用都可以独立的执行,它们就可以分散在不同的CPU上执行了。这也就意味着能够在多处理器上并行的执行使用函数式实现的算法。
Java7中的java.util.concurrent包里包含的ForkAndJoinPool能够帮助我们实现类似于函数式并行的一些东西。而Java8中并行streams能够用来帮助我们并行的迭代大型集合。
函数式并行里面最难的是确定需要并行的那个函数调用。跨CPU协调函数调用需要一定的开销。某个函数完成的工作单元需要达到某个大小以弥补这个开销。如果函数调用作用非常小,将它并行化可能比单线程、单CPU执行还慢。
我个人认为(可能不太正确),你可以使用反应器或者事件驱动模型实现一个算法,像函数式并行那样的方法实现工作的分解。使用事件驱动模型可以更精确的控制如何实现并行化(我的观点)。
此外,将任务拆分给多个CPU时协调造成的开销,仅仅在该任务是程序当前执行的唯一任务时才有意义。但是,如果当前系统正在执行多个其他的任务时(比如web服务器,数据库服务器或者很多其他类似的系统),将单个任务进行并行化是没有意义的。不管怎样计算机中的其他CPU们都在忙于处理其他任务,没有理由用一个慢的、函数式并行的任务去扰乱它们。使用流水线(反应器)并发模型可能会更好一点,因为它开销更小(在单线程模式下顺序执行)同时能更好的与底层硬件整合。