可参考文章: Java8 IdentityhashMap 源码分析
IdentityhashMap 与 ThreadLocalMap 一样都是采用线性探测法解决哈希冲突,有兴趣的可以先了解下 IdentityhashMap 。
一、ThreadLocal 简介
在学习源码之前,有一个概念我们需要先明白:ThreadLocal 可以使多线程间数据读写隔离,因此 ThreadLocal 解决的是线程局部变量安全性问题,并不是多线程间共享变量安全性问题。
ThreadLocal 在使用时必须先初始化 value,否则会报空指针异常,你可以通过 set 方法与重写 initialValue 方法两种方式初始化 value。
下面是 ThreadLocal 原理图,读源码的时候可以参考。
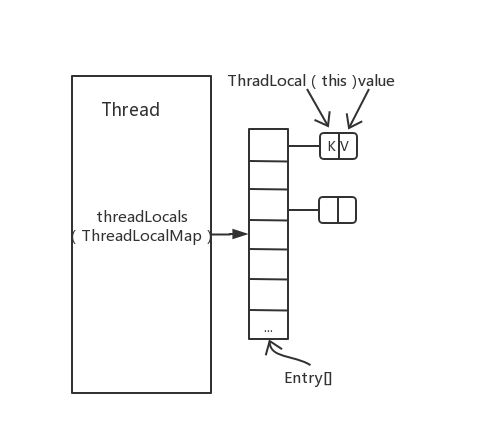
二、ThreadLocal 源码
我们先来了解一下 ThreadLocal,然后再逐渐了解 ThreadLocalMap。
2.1 内部相关属性
/*
* ThreadLocal 的哈希值通过一个原子类计算
*/
private final int threadLocalHashCode = nextHashCode();
/**
* 用于计算 ThreadLocal 哈希值的原子类
*/
private static AtomicInteger nextHashCode = new AtomicInteger();
/**
* 计算 ThreadLocal 哈希值的魔数
* 该值生成出来的值可以较为均匀地分布在 2 的幂大小的数组中
* 据说与斐波那契散列有关...
*/
private static final int HASH_INCREMENT = 0x61c88647;
ThreadLocalMap 的结构是通过纯数组实现的,因此 ThreadLocal 计算哈希值的方式也比较特殊,通过 nextHashCode() 方法生成哈希值,下面是具体实现。
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
生成哈希值时每次加上 0x61c88647,据了解通过 0x61c88647 计算出来的哈希值能够均匀的分布在 2 的幂大小的数组中,有兴趣的可以网上查一下进行详细的了解。
2.2 set 方法
public void set(T value) {
Thread t = Thread.currentThread();
// 根据当前线程获取对应的 map
ThreadLocalMap map = getMap(t);
if (map != null)
// key 是当前 ThreadLocal 对象的引用
map.set(this, value);
else
createMap(t, value);
}
在设置 value 时会先调用 getMap 方法根据当前线程获取对应的 map,如果 map 存在就设置值,不存在则创建 map,下面跟别来看下对应的方法(map.set 方法会在下面分析)。
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
getMap 方法很简单,就是返回当前线程的 threadLocals,这个 threadLocals 就是 ThreadLocalMap 对象。由此可以知道每个 Thread 内部都有一个 ThreadLocalMap 变量。
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
createMap 方法也比较简单,创建一个 ThreadLocalMap 并赋值给当前线程的 threadLocals 变量。
2.3 get 方法
public T get() {
Thread t = Thread.currentThread();
// 根据当前线程获取对应的 map
ThreadLocalMap map = getMap(t);
if (map != null) {
// 根据当前对象获取到对应的 Entry
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
// 返回 Entry 中对应的 value
return result;
}
}
// map 为空时创建
return setInitialValue();
}
如果 map 存在的话会先获取到当前线程对应的 map,然后根据当前 ThreadLocal 的弱引用获取 Entry,最终返回 Entry 中的 value 即可。如果 map 不存在则调用 setInitialValue 方法创建,下面是具体实现细节。
private T setInitialValue() {
// 获取 initialValue() 方法中对应的 value,
// 如果没有重写 initialValue 方法会抛空指针异常
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
// 如果对应的 map 不为空,则重置对应的 value
if (map != null)
map.set(this, value);
// map 为空,初始化 map
else
createMap(t, value);
return value;
}
2.4 remove 方法
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
remove 方法调用了 ThreadLocalMap 中的 remove 方法删除当前线程的,这个方法到下面介绍 ThreadLocalMap 时再详细分析。
三、ThreadLocalMap 源码分析
ThreadLocal 源码中最有意思的就属 ThreadLocalMap 了,它到底有哪些巧妙的设计呢?下面就来一探究竟吧。
3.1 内部相关属性
/**
* 哈比表数组默认初始化大小
*/
private static final int INITIAL_CAPACITY = 16;
/**
* 底层哈希表数组
*/
private Entry[] table;
/**
* 哈希表键值对个数
*/
private int size = 0;
/**
* 扩容阈值
*/
private int threshold; // Default to 0
/**
* 设置扩容阈值为容量的 2/3
*/
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
/**
* Increment i modulo len.当到数组尾时会从头开始
*/
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
/**
* Decrement i modulo len.当到数组头部时会从尾部开始
*/
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}
ThreadLocalMap 与 HashMap 最大的不同是当发生哈希冲突时不通过链表形式来解决冲突,而是使用线性探测法解决哈希冲突。ThreadLocalMap 的扩容阈值是 2/3,与 IdentityHashMap 一致,有兴趣的可以看下 IdentityHashMap,它们两个的结构是很相似的。
3.2 构造函数
我们来看其中一个构造函数。
/**
* 第一次添加的时候会调用该构造函数进行初始化,并设置第一个线程对应的 key 与 value
*/
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
// 初始化哈希表数组
table = new Entry[INITIAL_CAPACITY];
// 计算桶位置,这个哈希值的计算在上面我们解释过
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
// 设置到对应的桶位置上(已经有了一个 key 与 value)
table[i] = new Entry(firstKey, firstValue);
// 初始化 size 为 1
size = 1;
// 设置扩容阈值为初始容量的 2/3
setThreshold(INITIAL_CAPACITY);
}
当设置扩容阈值时调用了 setThreshold 方法,这个方法很简单,就是把阈值设置为数组长度的 2/3。
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
3.3 Entry 结构
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
// key 为弱引用
super(k);
value = v;
}
}
ThreadLocalMap 中存储键值对的结构是 Entry,Entry 实现了 WeakReference 类使 key 成为一个弱引用。Java 语言的弱引用对象意味着只要被垃圾收集器线程扫描到,那么不管当前内存是否足够都会被回收。关于强引用、软引用、弱引用与虚引用的差别可以查阅资料进行详细了解。
3.4 set 方法
ThreadLocalMap 添加键值对的方法不是 put 而是 set,如下:
private void set(ThreadLocal<?> key, Object value) {
// 获取哈希表数组
Entry[] tab = table;
int len = tab.length;
// 计算 key 对应的桶位置
int i = key.threadLocalHashCode & (len-1);
// e != null 意味着哈希冲突或是 key 重复
// e = tab[i = nextIndex(i, len)] 线性探测法解决哈希冲突
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
// 获取 key 的引用
ThreadLocal<?> k = e.get();
// key 重复,value 覆盖
if (k == key) {
e.value = value;
return;
}
// entry 不为 null,key 为 null,是因为 key 是弱引用,可能已经被 GC 回收了
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 找到插入的位置,存储 key 与 value
tab[i] = new Entry(key, value);
int sz = ++size;
// cleanSomeSlots 用于删除可能已经被 GC 回收的 key
// 如果没有 key 被 GC 回收,并且哈希表数组中的键值对数量大于 2/3,执行扩容操作
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
当插入键值对的时候,先根据哈希值计算出在哈希表数组中的位置,如果当前桶位置上的 entry 不为空,意味着出现哈希冲突或者是 key 重复。key 重复时直接将原来的 value 覆盖即可,上面我们已经提到了如果发生哈希冲突,ThreadLocalMap 通过线性探测法方式解决,因此需要继续从数组当前位置向后查找可插入位置(nextIndex)。当插入键值对过后会判断是否需要对哈希表数组扩容,整体的流程还是很清晰的。下面是 nextIndex 的具体实现:
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
当查找到数组尾部时,如果还没有找到要插入的位置,会从头继续查找,因此可以把哈希表数组理解为一个环状的结构。
ThreadLocalMap 的 key 因为是弱引用,因此当发生哈希冲突时,冲突的 entry 可能不为 null,而 key 为 null(弱引用被 GC 回收),如果 key 为 null 则调用 replaceStaleEntry 方法,下面就来看一下这个方法:
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
// 获取哈希表数组
Entry[] tab = table;
int len = tab.length;
Entry e;
// 记录 key 被擦除的桶位置(为 staleSlot 位置前的第一个连续的 key 被擦除的索引
// 或 staleSlot 位置后第一个连续的 key 被擦除或 key 重复的索引)
int slotToExpunge = staleSlot;
// 寻找 staleSlot 索引前连续不为 null 的 key 被擦除的桶位置
// 注意循环结束的条件是 e == null 与 IdentityHashMap 相同,也是线性探测法解决哈希冲突的截止条件,有兴趣的可以看下 IdentityHasHMap
for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// 向后查找
for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// key 重复
if (k == key) {
e.value = value;
// i 位置与 staleSlot 位置的 entry 互换,因为 staleSlot 位置上的 key 已经被回收,没有意义了
// TODO 那为什么不把 key 被 GC 回收的 entry 置为 null 而是位置互换呢?不要急,下面 expungeStaleEntry 方法会做
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// Start expunge at preceding stale entry if it exists
// slotToExpunge == staleSlot 意味着向前没有查找到连续的键值对 key 被擦除的情况
if (slotToExpunge == staleSlot)
slotToExpunge = i;
// 将 slotToExpunge 位置上的 entry 清除
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// 如果 i 位置上的 key 也已经被擦除将 slotToExpunge 置为 i
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// If key not found, put new entry in stale slot
// 把新的键值对直接存储在 staleSlot 位置
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// If there are any other stale entries in run, expunge them
// 如果向前或向后找到了 key 被擦除的 entry,则清除 slotToExpunge 位置上的键值对
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
replaceStaleEntry 方法相对来说比较难以理解,这里总结下我的思路过程,如果大家觉得哪里不对,可以在下面留言。首先我们先确定下 replaceStaleEntry 方法中的 staleSlot 字段,它表示新增键值对时 key 重复且 key 被 GC 回收情况下在哈希表数组中的位置。
replaceStaleEntry 方法先从 staleSlot 位置向前查找 entry 不为 null,key 为 null 的 键值对,记录在哈希表数组中的位置,注意这里循环结束的条件是 (e = tab[i]) != null,只要 entry 为 null 就停止循环,这个是线形探测法解决哈希冲突的重要判断条件,在 IdentityHashMap 中也有体现。
向前查找过后开始向后查找,结束的条件与之前一致,只不过向后查找可能会出现 key 相同的情况,如果 key 重复则重置其 value,然后把 staleSlot 位置与 i 位置的键值对位置互换,为什么要互换呢?原因是 staleSlot 位置上的 entry 的 key 已经被 GC 回收了,为了保证哈希冲突的所有键值对连续,因此需要把后面冲突的键值对前移。
接下来看这一段代码:
if (slotToExpunge == staleSlot)
slotToExpunge = i;
// 将 slotToExpunge 位置上的 entry 清除
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
slotToExpunge == staleSlot 表示向前没有查找到连续的键值对 key 被擦除的情况,把 slotToExpunge 的值置为了 i,然后执行了 cleanSomeSlots(expungeStaleEntry(slotToExpunge), len),这个 slotToExpunge 在这里表示键值对交换过之后 key 被 GC 回收的那个 entry 所在哈希表数组中索引的位置。因为它的 key 已经被 GC 回收了,就意味着这个键值对没有存在的必要了,需要对其清除,于是就执行了 expungeStaleEntry 方法:
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// value 置 null,对应桶位置上的 Entry 也置 null
tab[staleSlot].value = null;
tab[staleSlot] = null;
// 键值对数量减 1
size--;
Entry e;
int i;
// 删除一个 key 被擦除的键值对,可能因为之前哈希冲突,导致后面桶位置上的键值对位置不准确,因此要向前调整后面桶位置上的键值对
// 从 staleSlot 位置向后遍历,要求必须连续,与 IdentityHashMap 一致
for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// 如果后面桶位置上键值对被擦除,则直接清除,因此 expungeStaleEntry 方法并不是只清除 staleSlot 位置上的键值对
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
// 并不是向前移动,而是重新 rehash,计算对应的桶位置
// TODO 重点理解,重新 rehash 解决之前可能存在哈希冲突的情况
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
// 返回 staleSlot 之后第一个键值对为 null 的桶位置
return i;
}
expungeStaleEntry 中上来就对 staleSlot 位置上的键值对置 null,然后键值对的数量减一,但是并不说删除一个键值对这里就结束了。我们说过 ThreadLocalMap 是通过线性探测法来解决哈希冲突的,当删除一个键值对之后需要从当前删除的位置向后循环,判断后面是否存在因为哈希冲突被移动到后面去的键值对,如果有就重新计算其哈希值,然后存储到对应的位置上,当然重新计算哈希值也要考虑哈希冲突。顺便在这里提一下,这里与 IdentityhashMap 的处理方式是不同的,IdentitiHashMap 并不会重新计算后面冲突的 key 的哈希值而是采取向前移动的方式来解决。
到这里还不算完,expungeStaleEntry 方法中返回了一个 i,这个 i 表示 staleSlot 位置后第一个 key 被 GC 回收的数组索引位置。执行完 expungeStaleEntry 方法后根据其返回值又执行了 cleanSomeSlotsc 方法,这个方法又是干嘛的呢?下面来简单的分析一下:
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
// 获取对应桶位置上的 Entry
Entry e = tab[i];
// Entry 不为 null,key 为 null 是因为 key 是弱引用可能会被 GC 回收,因此需要在哈希表中删除
if (e != null && e.get() == null) {
n = len;
// 如果有键值对被擦出就返回 true
removed = true;
// 删除 i 位置上的键值对
i = expungeStaleEntry(i);
}
} /* 对数扫描,并不会扫描整个哈希表数组 */while ( (n >>>= 1) != 0);
return removed;
}
根据 cleanSomeSlots 的方法名我们应该可以知道这个方法大概做了什么,清除一些哈希槽位置上的键值对。这个方法会循环向后判断当前桶位置上的 key 是否被 GC 回收了,如果被回收了就调用 expungeStaleEntry 方法清除其键值对。注意这里不是一直向后循环,而是采取对数的方式,这就说明,整个循环下来并不会清除所有 key 被 GC 回收的键值对,会存在一些漏网之鱼。
关于 set 方法就简单的分析到这里,其中还有一些细节大家有兴趣可以自己查看,如果哪里有错误的地方大家可以在下面留言交流。
3.5 set 方法之 rehash
我们上面一直在分析哈希冲突的情况,还有一个比较重要的 rehash 过程,添加过键值对后判断是否需要 rehash 的是下面这段代码:
// !cleanSomeSlots(i, sz) 表示没有键值对因为 key 被回收而清除
// sz >= threshold 表示哈希表数组中的键值对数量已经大于了扩容阈值
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
当判断条件通过后会调用 rehash 方法。
private void rehash() {
// 清除所有 key 被擦出的键值对
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
// 再次判断
// TODO Q:这个判断有什么作用?不可能是 false 的啊
// A:因为上面调用了 expungeStaleEntries 方法,可能有的键值对被移除导致哈希表数组的键值对非常少,此时就没有扩容的必要了
if (size >= threshold - threshold / 4)
resize();
}
rehash() 方法先调用了 expungeStaleEntries() 方法,这个方法里会循环整个哈希表数组,然后清除所有的 key 被 GC 回收的键值对。
private void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
expungeStaleEntry(j);
}
}
为什么上面已经执行过了 cleanSomeSlots 方法来清除键值对,为什么这里又要判断一次呢?原因就是 cleanSomeSlots 方法并不会循环整个哈希表,会存在一些漏网之鱼,而 expungeStaleEntries() 方法会连那些漏网之鱼一起处理掉。
调用了 expungeStaleEntries() 方法之后,需要重新判断键值对数量,只有当条件满足时才会调用 resize() 方法。下面是 resize() 方法的是实现:
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
// 新哈希表的大小为原哈希表大小的 2 倍
int newLen = oldLen * 2;
// 初始化新哈希表
Entry[] newTab = new Entry[newLen];
// 记录新哈希表中键值对的个数
int count = 0;
// 遍历老哈希表数组,进行 rehash
for (int j = 0; j < oldLen; ++j) {
// 获取老哈希表桶位置上的 Entry
Entry e = oldTab[j];
if (e != null) {
ThreadLocal<?> k = e.get();
// 如果 key 被回收,则把 value 也置 null
// 无时不刻判断着 key 被擦除的情况
if (k == null) {
e.value = null; // Help the GC
} else {
// 计算老哈希表中的键值对在新哈希表中的桶位置
int h = k.threadLocalHashCode & (newLen - 1);
// 这里也可能会产生哈希冲突
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
// 设置新的扩容阈值,2/3
setThreshold(newLen);
size = count;
// 新的哈希表替代老的哈希表
table = newTab;
}
rehash 的过程其实是比较简单的,生成新的哈希表,然后遍历旧的哈希表数组,将键值对重新 rehash 存储到新的哈希表数组中即可。
3.6 remove 方法
上面我们看了添加方法,下面来看一下删除操作:
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
// 计算出对应的桶位置,当然对应桶位置上的键值对并不一定是当前 key 对应的键值对,因为可能存在哈希冲突
int i = key.threadLocalHashCode & (len-1);
// 从 i 位置向后遍历,遍历结束的位置是后续桶位置上为 null
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
// key 清空
e.clear();
// 调用 expungeStaleEntry 方法
expungeStaleEntry(i);
return;
}
}
}
根据 key 就算哈希值,在哈希表数组中找到对应的位置开始循环判断,如果 key 相同则调用 expungeStaleEntry 方法直接清除键值对。PS:注意循环结束条件 e != null。
关于 ThreadLocal 的源码就分析到这里,一千个人眼里有一千个哈姆雷特,只有自己去看了才能有更深刻的了解。
关于 jdk1.8 更多的源码分析,请点击这里前往:jdk1.8 源码阅读