1. 使用的工具
selenium+xpath+ 手动输入登录
2. 实现的功能:
1.手动登录后,按终端提示,就能下载所需要的内容
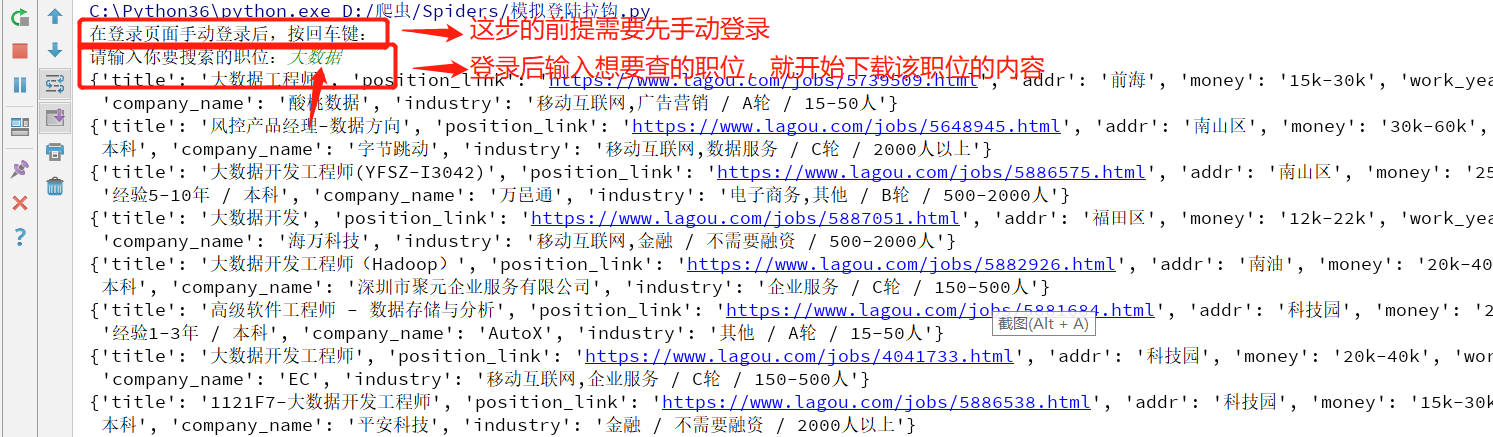


import requests import json import time import random from lxml import etree from concurrent.futures import ThreadPoolExecutor from selenium import webdriver import pymongo # 连接mongo 数据库 client = pymongo.MongoClient() db = client.lougou collention =db.lou # 进入拉钩首页 url ='https://www.lagou.com/' bro = webdriver.Chrome() bro.get(url) input('在登录页面手动登录后,按回车键:') # 进入了自己登录页面 # 找到收缩框 search_input = bro.find_element_by_id('search_input') # 找到搜索按钮 search_button = bro.find_element_by_id('search_button') # 输入你需要搜索的职位 search_msg = input('请输入你要搜索的职位:') # 在输入框自动填入搜索内容 search_input.send_keys(search_msg) # 自动点击搜索按钮 search_button.click() def get_data(): ''' 提取页面数据 将数据存入 mongo 数据库 ''' time.sleep(1) # 获取页面内容 page=bro.page_source time.sleep(2) tree = etree.HTML(page) li_list =tree.xpath("//ul[@class='item_con_list']/li") for li in li_list: item={} item['title'] =li.xpath('.//h3/text()')[0] # 职位标题 item['position_link'] = li.xpath(".//a[@class='position_link']/@href")[0] # 职位详情链接 item['addr'] = li.xpath(".//span[@class='add']/em/text()")[0].strip() # 公司区域 item['money'] = li.xpath(".//div[@class='li_b_l']/span/text()")[0] # 岗位工资 item['work_year'] = li.xpath(".//div[@class='p_bot']/div[@class='li_b_l']//text()") # item['work_year'] = [i.strip() for i in item['work_year'] if i.strip()] item['work_year'] =item['work_year'][1] # 工作经历 item['company_name'] = li.xpath(".//div[@class='company_name']/a/text()")[0] # 公司名字 item['industry'] = li.xpath(".//div[@class='industry']/text()")[0].strip() # 公司所属行业 print(item) # 将数据存到MongoDB 中 collention.insert(item) get_data() # 翻页下载该搜索也的所有页的数据 while 1: try: # 下一页 next =bro.find_element_by_xpath('//span[@class="pager_next "]') next.click() get_data() except : print('没有下一页了。。。。。') break # 进入循环 ,实现 用户再次 输入 不同职位进行下载该类职位的信息 ,用户可以按 q 或 Q 退出下载 while 1: keyword_input = bro.find_element_by_id('keyword') # 搜索框 submit_btn = bro.find_element_by_id('submit') # 搜索按钮 # 清空输入搜索框的内容 keyword_input.clear() # 重新进行搜索 msg2 =input('请输入你要下载的职位信息:') # 退出循环条件,退出下载 if msg2.upper()=='Q': break keyword_input.send_keys(msg2) # 点击搜索 submit_btn.click() # 下载该页面的数据 get_data() while 1: try: # 下一页 next =bro.find_element_by_xpath('//span[@class="pager_next "]') next.click() # 进入下一页,进行下载该页的数据 get_data() except : print('没有下一页了。。。。。') break # 关闭数据库 client.close() # 关闭浏览器 bro.quit()
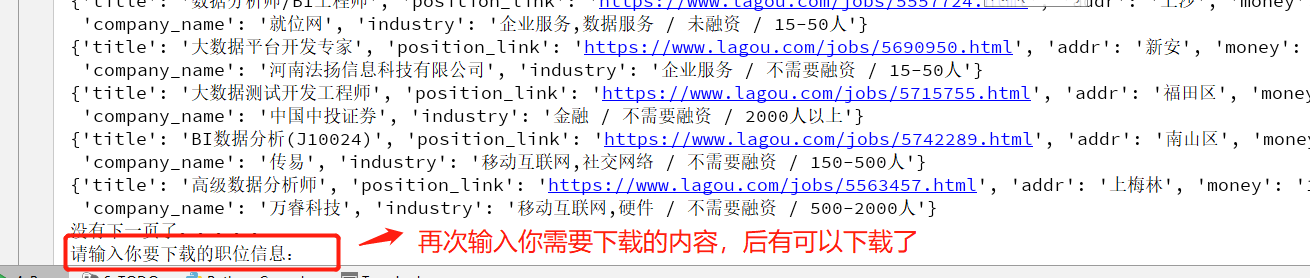
2. 你第一次输入的职位下载完会提醒你,你可以再次下载你所需要的其他职位的数据
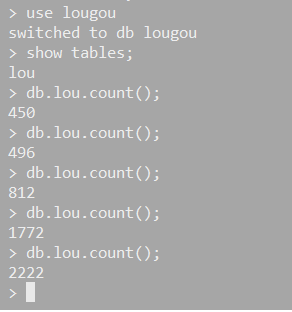
3. 数据保存在了 mongo中,此处没有做扩展,存文件或其他数据库