目录
SSD算法原理、框架流程、流程图
SSD算法主要的贡献之处:
作者认为自己的算法之所以在速度上有明显的提升,得益于去掉了bounding box proposal以及后续的pixel或feature的resampling步骤。
在检测速度上:比YOLOv1快;在检测精度上:能与Faster R-CNN相当。
算法核心:在特征图上采用卷积神经网络进行预测一系列的default bounding boxes的类别以及偏移量
在不同尺度下进行预测,得到具有不同aspect ratio的结果
实现端到端的训练,在分辨率较低的图像上也能获得较好的结果
SSD网络结构
| SSD的输入 |
image和ground truth boxes |
| SSD的输出 |
类别和目标框 |
| SSD网络主结构 |
VGG-16+增加的卷积层 |
| 算法的结果 |
对于300*300的输入,SSD可以在VOC2007 test上有74.3%的mAP,速度是59 FPS(Nvidia Titan X),对于512*512的输入, SSD可以有76.9%的mAP。 |
SSD网络框架如下图所示:SSD利用astrous 算法将VGG-16最后原有的两个全连接层(fc6、fc7) 改成了卷积层并且增加了3个卷积层和一个 average pool层。
在检测过程中:SSD算法使用conv4_3,conv7(原有的fc7),conv8_2,conv9_2,conv10_2以及pool11层提取的图像特征来进行预测,得到两个输出一个是输出分类用的confidence,每个default box生成k+1个confidence;另一个输出是对目标框位置回归的值。

SSD算法流程:将一幅图片输入至预训练好的分类网络中提取不同尺度大小的特征信息,选取conv4_3,conv7(原有的fc7),conv8_2,conv9_2,conv10_2以及pool11层的feature map,然后在这些feature map上生成不同尺度大小的default box,分别进行检测和分类生成多个候选框,最后将不同尺度下feature map对应生成的候选框结合起来,通过非极大值抑制算法筛选得出最后的bounding box的集合,即检测结果。
解释SSD里的atrous
在SSD算法里作者将FC6和FC7改为卷积层,并且将Pool5从2x2-S2变换到3x3-S1。pool5这样改变这之后,后面层的感受野将改变,因此也不能用原来网络的参数进行finetune,现在既想利用已经训练好的模型进行fine-tuning,又想改变网络结构得到更加dense的score map,就必须做出相应的操作。在这种情况下就加入了Atrous,因为使用Atrous不仅能减少参数,由于一般相邻像素包含的信息相似,也能减少对冗余信息的处理。
Atrous Convolution其实就是带洞卷积,卷积核是稀疏的。下图分别展示出了三种3种不同的卷积方式

上图对应的卷积过程如下,可以看到a)和c)的感受野是相同的。

解释default bounding box生成的流程

Default box指的是在feature map的每个cell上一系列的固定大小的box。
如上图所示,假设有两种尺度的feature map,如(b)和(a)所示,分别有64个和16个feature map cell,对于每一个cell上都会有一系列固定大小的box,称为default box,上图示例中是每个cell有4个box。
在SSD中还有一个概念--prior box:实际中选择的default box。也就是说default box是一个概念,在SSD中实际操作时对应生成的候选框实际上是用prior box来表示的,而在理论学习中是用default box来表示feature map cell中生成的box。
生成prior box的计算过程:
首先在一系列feature map cell上确定中心点,在每个特征图上生成尺度不同的default box,每个特征图上的尺度计算公式如下:
![]()
其中,![]() ,
,![]() ,m
,m![]() 为需要计算的feature map的数目
为需要计算的feature map的数目
对于prior box的aspect ratio(横纵比):![]() ,对于
,对于![]() 时,额外增加一个default box,其相对应的尺度
时,额外增加一个default box,其相对应的尺度![]() 为:
为:![]() 。
。
计算每一个default Box的参数,宽度和高度:
![]()
![]()
通过上面的公式计算可以看出每个feature map cell会生成6种尺度的default box。每一个default box的中心为:![]() ,
,![]() 为第
为第![]() 个feature map的大小,且
个feature map的大小,且![]() 。
。
正负样本生成:
在获得prior box后下一步就是将其与ground truth box进行IOU匹配,保证每一个ground truth都有相对应的prior box,匹配的规则如下:

![]()
只要两者之间的 jaccard overlap 大于一个阈值,就表明prior box与ground truth匹配,这样就意味着每一个ground truth有多个prior box匹配。这些与groundtruth匹配的prior box就作为训练的正样本,其他的归为负样本。
在训练过程中为保证负样本的数量过多导致样本不均衡,训练很难收敛。SSD算法中会将所有负样本的confidence loss进行排序,然后按照比例选取置信度最高的几个负样本,保证正负样本的比例为1:3。
损失函数的表达式
SSD算法的损失函数与Faster R-CNN的损失函数相似,都是由分类和回归两个部分组成的多任务损失函数。
![]()
式中,![]() ;
;![]() 代表匹配至ground truth上的prior box的数目;α
代表匹配至ground truth上的prior box的数目;α![]() 则是用来调整两种损失之间的比例参数,一般地α=1;
则是用来调整两种损失之间的比例参数,一般地α=1;
![]() 为分类损失,是典型的softmax loss,定义如下:
为分类损失,是典型的softmax loss,定义如下:
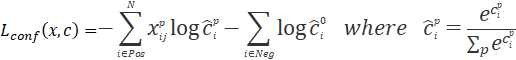
![]() :在类别为
:在类别为![]() 时,第
时,第![]() 个预测框与第
个预测框与第![]() 个真实框匹配,则
个真实框匹配,则![]() 的概率预测的越高,loss越小;
的概率预测的越高,loss越小;
![]() :预测框里没有任何目标,则预测为背景时的概率越高,loss越小
:预测框里没有任何目标,则预测为背景时的概率越高,loss越小
![]() :概率值由softmax产生。
:概率值由softmax产生。
式中,log是以e为底的,i表示default box的序号,j表示ground truth的序号,![]() 表示的是第i个预测框与第j个真实框是否匹配,
表示的是第i个预测框与第j个真实框是否匹配,![]() 表示第
表示第![]() 个预测框对应类别
个预测框对应类别![]() 的预测概率。
的预测概率。
![]() 为候选框坐标损失,定义如下:
为候选框坐标损失,定义如下:


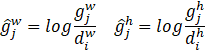
式中,![]() 为补偿后的d
为补偿后的d![]() 的中心,
的中心,![]() 为默认框的宽和高,
为默认框的宽和高,![]() 表示的是在类别为
表示的是在类别为![]() 时,第i个预测框与第j个真实框是否匹配,就是说当不匹配时不需要计算。
时,第i个预测框与第j个真实框是否匹配,就是说当不匹配时不需要计算。
![]() 的定义如下:
的定义如下:
![]()
解释多尺度特征图的预测
SSD算法中使用的是多个尺度下的feature map,选取的卷积层分别为:conv4_3,conv7(原有的fc7),conv8_2,conv9_2,conv10_2以及pool11层,对应的feature map的尺度为:38x38x512、19x19x1024、10x10x512、5x5x256、3x3x256、1x1x256,对应的default box的数目为:4、6、6、6、4、4。据此可知每个feature map对应的box总数目为:5776、2166、600、150、36、4,即我们总共可以获得8732个box
| 卷积层 |
conv4_3 |
conv7 |
conv8_2 |
conv9_2 |
conv10_2 |
pool11 |
| feature map |
38x38x512 |
19x19x1024 |
10x10x512 |
5x5x256 |
3x3x256 |
1x1x256 |
| default box |
4 |
6 |
6 |
6 |
4 |
4 |
| box |
5776 |
2166 |
600 |
150 |
36 |
4 |
与YOLO的对比
基于SSD的改进算法
| 算法 |
解决问题 |
主要改进 |
结果 |
| DSSD
|
小目标问题 |
[Deconvolutional Single Shot Detector] DSSD是2017 年北卡大学教堂山分校的 Cheng-Yang Fu[47]等针对SSD算法对小目标检测不够鲁棒的问题提出的改进算法,主要有两点改进: 1)把SSD算法中的VGG网络替换成了Resent-101网络,这样能够增强检测器的特征提取能力; 2)利用Deconvolution,参考 FPN 算法思路利用去卷积结构将图像深层特征从高维空间传递出来,与浅层信息融合,增加了上下文信息,这样能够提高浅层的表征能力,从而提高检测器对小目标的检测能力。 DSSD的网络结构包含:属于resnet101中的卷积层,SSD算法中额外增加的5层卷积层,Prediction 模块以及Deconvolution 模块。DSSD算法是将resnet101中的两个卷积层特征中浅层特征与额外的5个卷积层特征的六层特征图输入到Deconvolution 模块中,输出修正的特征图金字塔,形成一个特征图组成的沙漏结构。最后经Prediction 模块输入给回归任务和分类任务做预测。虽然DSSD算法提高了对小目标的检测能力,但是由于引入的Resnet-101太深,检测速度相比SSD慢了很多。 |
|
| R-SSD
|
小目标问题 物体框重复问题 |
[Enhancement of SSD by concatenating feature maps for object detection] 解决了SSD算法中不同层feature map都是独立作为分类网络的输入,容易出现相同物体被不同大小的框同时检测出来的情况,还有对小尺寸物体的检测效果比较差的情况。 R-SSD算法从两方面来改进SSD: 1)利用分类网络增加不同层之间的feature map联系,减少重复框的出现; 2)增加feature pyramid中feature map的个数,使其可以检测更多的小尺寸物体。 特征融合方式采用同时利用pooling和deconvolution进行特征融合,这种特征融合方式使得融合后每一层的feature map个数都相同,因此可以共用部分参数,具体来讲就是default boxes的参数共享。 |
|
| MDSSD |
小目标问题 |
[Multi-scale Deconvolutional Single Shot Detector for small objects] 针对小目标: 卷积神经网络目标检测中,浅层主要负责小物体检测,因为它们具有精细的细节。然而,由于浅特征上的语义信息的不足,检测小对象实例的性能仍然不太令人满意 通过解卷积Fusion Block将具有丰富语义信息的高级特征添加到低级特征中,值得注意的是,框架中同时对多个具有不同比例的高级特征进行了上采样,然后跳过连接以形成小对象的更具描述性的特征映射,并对这些新的融合特征进行预测。 文中提供了三个fusion modules,其中一个示例如下:
|
VOC2007: 78.6%mAP MS COCO test-dev2015:26.8%mAP,38.5 FPS,仅300×300输入。 结果优于基准SSD分别为1.1和1.7分,特别是在一些小对象类别上改善了2至5分。 |
| Feature-Fused SSD
|
小目标问题 |
[Fast Detection for Small Objects] 将contextual information 引入到 SSD 中 帮助SSD检测小目标。 shallower layers 具有 contextual information ,但是没有 sematic information;deeper layers 具有 sematic information 本文尝试了两种方式将这两种信息结合起来:concatenation module和element-sum module,即特征拼接时用concat还是sum操作。 |
在VOC2007上获得的mAP分别比基线SSD高1.6和1.7分,特别是在一些小物体类别上提高2-3个点。 它们的测试速度分别为43和40 FPS,优于现有技术的去卷积单发探测器(DSSD)29.4和26.4 FPS。 |
| FSSD
|
保证精度,提升速度 |
[Feature Fusion Single Shot Multibox Detector] SSD算法是从不同卷积层中抽取不同尺度的特征直接做预测,所以没有充分融合不同尺度的特征。后续有提出DSSD,RSSD等改进方法,但是因为模型的复杂导致速度变慢很多。 Li等人提出了FSSD算法借鉴了FPN的思想,但是又与FPN不一样,如下图可以看出,FSSD是把不同尺度的特征调整为同一个尺度再contact得到一个像素层,以这个像素层为基础层重构一个新的pyramid feature map,从而提高检测器的性能。FSSD的精度比SSD要高,但是比DSSD要低一点;FSSD的速度稍慢于SSD,但比DSSD要快不少。
|
|
| ESSD
|
保证精度,提升速度 |
[Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network] 不降低精度的情况下提高速度。与FSSD相似,ESSD也是解决上述问题。 反卷积虽然有很好的作用,但添加过多的反卷层将不可避免地导致计算耗时的显着增加,而提供太少的语义信息肯定会失去一些检测性能。基于此作者使用了三个extension modules在ESSD结构中,使得能既扩展了适量的语义信息,获得足够好的结果又不会丢失太多的检测速度。 extension modules具体结构: 1)使用反卷积使得卷积层第n层和第n+1层大小相同,然后每个卷积层后面会跟着一个BN层以及一个ReLU层来细化细化学习的特征。 2)如上所述的两个Conv-bn-relu模块位于第n层之后,用以获得与第 n+1层相同的学习能力。 3)使用一个extended operation来获得extension features,这个操作可以是串联,相加或相乘。
与DSSD不同的是,DSSD为每个预测层添加了残差块,ESSD只为每个预测层添加一个额外的1x1x512卷积层,以免使模型过于复杂。 |
检测模型的结果可以达到79.4%mAP,比DSSD和SSD高0.8和1.9并且在Titan X GPU下测试速度为25 FPS,是原DSSD的两倍多。 |
| DSOD |
训练方式 |
目标检测算法基本都是先在ImageNet数据集上进行预训练,然后再微调。虽然这种方法能让目标检测算法取得很好的性能,但是微调在目标检测算法上也存在着一些问题:与训练的模型大,参数也多,结构也是固定的直接用于目标检测时很难改变网络的结构,计算量也很大;预训练是分类训练,分类的目标一般与检测的目标不一样,这样会导致预训练的模型在检测上并不是最优解,只是局部最优;预训练一般是在ImageNet数据集上,所以如果遇到一些少见的检测目标,是不一定能迁移到检测模型上的。 2017年复旦大学Shen [50]等人基于SSD算法提出了DSOD算法。DSOD算法不是在mAP上和其他检测算法做比较,看谁的算法更有效或者速度更快,而是从另一个角度切入说明fine-tune和直接训练检测模型的差异其实是可以减小的。 DSOD算法可以看作是SSD算法与DenseNet的结合,即在SSD的特征融合方法中引入了DenseNet思想,改造了一些层的输入。通过结合DenseNet,也使得DSOD的参数数量大大减少。具体操作是根据DenseNet的设计原理,将相邻的检测结果一半一半的结合起来。 DSOD中采用Dense Block结构,能避免梯度消失的情况。同时利用Dense Prediction结构,也能大大减少模型的参数量,特征包含更多信息。设计stem结构能减少输入图片信息的丢失,stem结构由3×3卷积和2×2的max pool层组成,其还可以提高算法检测的mAP。 |
|
| Tiny SSD
|
精简模型 |
[A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection] 降低模型的大小,将SSD模型优化到2.3M Tiny SSD的优化思想是基于squeezeNet的设计思想: 1)尽量减少3×3卷积的通道 2)尽量减少3×3卷积的输入通道 3)尽量将下采样往后推迟 Tiny SSD将前面的基础网络改成由10个fire model构成的网络 |
Tiny SSD的型号尺寸为2.3MB(比Tiny YOLO小约26倍),而VOC 2007的mAP仍为61.3%(比Tiny YOLO高约4.2%)。 |





SSD的Caffe训练和测试过程