1、网络爬虫,推荐一个解析HTML的Python库–Requests-HTML
这个库的用法,可以参考如下网址:
https://blog.csdn.net/anonymous_qsh/article/details/79372524
2、写这个文章的目的,只是为了记录自己学习python爬虫项目所用。如果要看小说,请支持正版
本人学习的地址来源于:
https://www.w3cschool.cn/python3/python3-enbl2pw9.html
3、本项目需要安装的python包 requests_html
import logging
import time
from requests_html import HTMLSession as hs
4、日志模块(可有可无的模块,只是将日志设置一些级别,用于分析)
LocalDay = time.strftime("%Y-%m-%d")
logFile = r'D:\SpyderNovels\{0}.log'.format(LocalDay)
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename=logFile,
filemode='a+')
console = logging.StreamHandler()
console.setLevel(logging.INFO)
formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
console.setFormatter(formatter)
logging.getLogger('').addHandler(console)
5、下载一个章节的示例:
(1)headers模拟手机或者浏览器,以’https://www.biqukan.com/1_1094/5403177.html’为例。因为控件元素不同,所以需要获取的就得跟着改变
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.99'
}
webaddr='https://www.biqukan.com/1_1094/5403177.html'
def novelDown(webaddr):
session = hs()
request_novel=session.get(webaddr,headers=headers)
request_novel.html.encoding='GBK'
title = list(request_novel.html.find('h1'))[0].text # 获取小说标题
FileName = open('D://test.txt', 'a', encoding='gb18030', errors='ignore')
content = list(request_novel.html.find('div#content.showtxt'))[0].text # 获取小说内容
FileName.write(title)
FileName.write('\n\n')
FileName.write(content)
FileName.write('\n\n')
FileName.close()
如何获取控件元素,也就是request_novel.html.find(‘h1’),request_novel.html.find(‘div#content.showtxt’)这里面的关键词是如何找到的呢?请看下面的截图
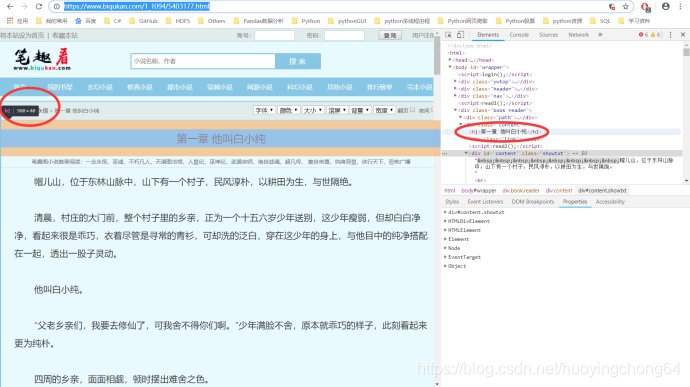
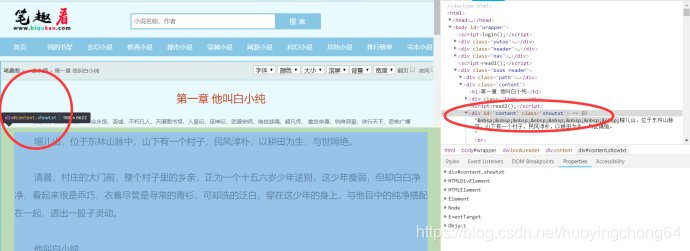
可以看到的是,在进入了F12的模式后,在右侧是F12后的html源码,当你指定到相对的控件元素上时,左侧对应的位置上,就是相对的控件查找内容了。因为需要的是小说内容,所以需要的是text属性。
6、获取小说所有章节:
这里需要介绍下request-html获取元素的方法:
支持CSS选择器和XPATH两种语法来选取HTML元素。
1、CSS选择器语法,它需要使用HTML的find函数,该函数有5个参数,作用如下:
selector,要用的CSS选择器;
clean,布尔值,如果为真会忽略HTML中style和script标签造成的影响(原文是sanitize,大概这么理解);
containing,如果设置该属性,会返回包含该属性文本的标签;
first,布尔值,如果为真会返回第一个元素,否则会返回满足条件的元素列表;
_encoding,编码格式。
from requests_html import HTMLSession as hs
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.99'
}
target = 'http://book.zongheng.com/showchapter/672340.html'
session = hs()
r = session.get(target, headers=headers)
print(r.html.find('div.volume')[0].absolute_links)#首页获取
2、XPATH语法,这需要另一个函数xpath的支持,它有4个参数如下:
selector,要用的XPATH选择器;
clean,布尔值,如果为真会忽略HTML中style和script标签造成的影响(原文是sanitize,大概这么理解);
first,布尔值,如果为真会返回第一个元素,否则会返回满足条件的元素列表;
_encoding,编码格式。
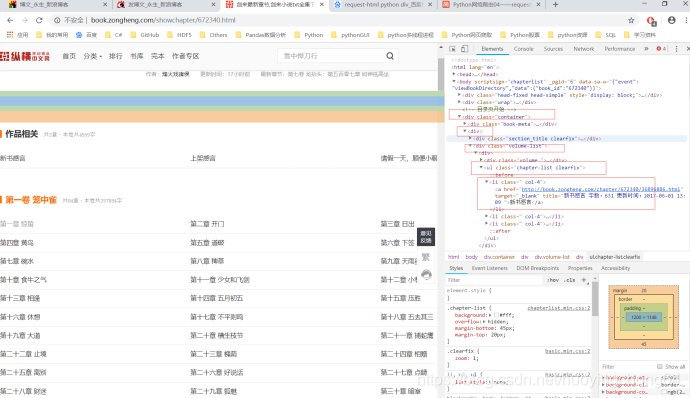
for i in r.html.xpath("//div[@class='container']/div/div[@class='volume-list']/div/ul[@class='chapter-list clearfix']/li/a"):
print(i.text)
print(i.absolute_links)
打印结果:
新书感言
{'http://book.zongheng.com/chapter/672340/36896886.html'}
上架感言
{'http://book.zongheng.com/chapter/672340/38705697.html'}
请假一天,顺便小聊几句。
{'http://book.zongheng.com/chapter/672340/44658570.html'}
...
程序示例:
from requests_html import HTMLSession as hs
def get_story(url):
global f
session=hs()
r=session.get(url,headers=headers)
r.html.encoding='GBK'
title=list(r.html.find('title'))[0].text#获取小说标题
nr=list(r.html.find('.nr_nr'))[0].text#获取小说内容
nextpage=list(r.html.find('#pb_next'))[0].absolute_links#获取下一章节绝对链接
nextpage=list(nextpage)[0]
if(nr[0:10]=="_Middle();"):
nr=nr[11:]
if(nr[-14:]=='本章未完,点击下一页继续阅读'):
nr=nr[:-15]
print(title,r.url)
f.write(title)
f.write('\n\n')
f.write(nr)
f.write('\n\n')
return nextpage
def search_story():
global BOOKURL
global BOOKNAME
haveno=[]
booklist=[]
bookname=input("请输入要查找的小说名:\n")
session=hs()
payload={'searchtype':'articlename','searchkey':bookname.encode('GBK'),'t_btnsearch':''}
r=session.get(url,headers=headers,params=payload)
haveno=list(r.html.find('.havno'))#haveno有值,则查找结果如果为空
booklist=list(r.html.find('.list-item'))#booklist有值,则有多本查找结果
while(True):
if(haveno!=[] and booklist==[]):
print('Sorry~!暂时没有搜索到您需要的内容!请重新输入')
search_story()
break
elif(haveno==[] and booklist!=[]):
print("查找到{}本小说".format(len(booklist)))
for book in booklist:
print(book.text,book.absolute_links)
search_story()
break
else:
print("查找到结果,小说链接:",r.url)
BOOKURL=r.url
BOOKNAME=bookname
break
global BOOKURL
global BOOKNAME
url='http://m.50zw.net/modules/article/waps.php'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.99'
}
def main(BOOKURL,BOOKNAME):
if BOOKURL == '' and BOOKNAME == '':
search_story()
else:
chapterurl=BOOKURL.replace("book","chapters")
session=hs()
r=session.get(chapterurl,headers=headers)
ch1url=list(r.html.find('.even'))[0].absolute_links#获取第一章节绝对链接
ch1url=list(ch1url)[0]
global f
f=open("D://novels//"+BOOKNAME+'.txt', 'a',encoding='gb18030',errors='ignore')
print("开始下载\n")
nextpage=get_story(ch1url)
while(nextpage!=BOOKURL):
nextpage=get_story(nextpage)
f.close
if __name__ == "__main__":
BOOKURL = 'https://m.50zw.net/book_33097/'
BOOKNAME = '独闯天涯'
main(BOOKURL,BOOKNAME)