转载请注明出处: translated by zhoutao
同步周期回收在计数统计系统中的应用
抽象的说,自动存储回收通过使用引用计数拥有重要优势,但是同样存在的一个主要问题就是无法重复循环使用数据的结构。
我们描述一个新奇的循环回收算法,它一方面是同步的--尽管同时发生变化,它仍可以回收垃圾;另一方面是本地化--它从不需要去执行一个内部数据空间的全局搜索。
我们详细的描述了我们的算法而且证明了它的正确性。
我们已经在java的虚拟机中应用了我们的算,作为其中一部分的回收算法。一个同步
多重处理引用计数垃圾回收,达到最大的突变的停顿时间--仅仅6毫秒。我们提出了 循环回收算法,通过设置8 个标准检查程序,而且论证了同步回收算法在寻找垃圾循环中的影响,处理同步的变化,而且同时消除全局的追踪。
1 介绍
四十年前,有两种自动存储垃圾回收机制被我们所了解:引用计数【7】和追踪【23】,在此之前,追踪回收和他们变异版本(
mark-and-sweep, semispace copying, mark-and-compact
)已经非常的广泛应用。
存储器和处理能力的相对成本的变化
,而且在主流编程中采用垃圾回收语言(尤其氏java)已经改变这种状况。我们相信到了该去重新审视引用计数的时候了,尤其由于处理时钟速度的增长,同时
RAM
变得丰富起来,而且没有明显的变快。在这种大环境下引用计数的局部性质(
the locality properties of)
很吸引人,同时跟额外的处理能力变的不非常相关了。
同时,java的垃圾回收的合并已经使这个问题进入到主流当中,而且巨大,关键任务系统
已经在java中被建立起来,强调潜在的垃圾回收实施的灵活性和可扩展性。导致的结果,追踪收集器的设想的优势--简单和低消耗--已经被削减,由于她们曾经被设置的更加复杂去记录现实世界中巨大而且不同的程序的需求。
引用计数有三个主要的问题:
1.存储开销与保持每个对象的计数
2.引用计数运行时开销 的增长和减少,时一个被复制的点
3.无法去检测周期,随之而来的需要引用另一个垃圾回收技术去处理循环的垃圾
无法回收循环被视为引用计数回收器最大的缺点。同时给程序员增加了很大的负担去明确的打破循环,或者需要特殊程序语法,或者需要一个追踪回收器去回收循环。
在这里,我们首先展示同步,接下来是在引用计数系统中回收垃圾的结构算法。新的同步算法是同步算法和额外的对主要安全性能的测试的结合体。
像算法基于追踪一样,我们的算法是在图标追踪中是线性的。但是我们的算法可以在本地处理追踪而不是在全局中执行,而且经常追中一个比较小的子图。
这些算法已经使用在新的引用回收计数器中,这个回收器是java vm的一部分,在
IBM T.J. Watson Research Center 被执行,Jalapen ̃o 自己将此算法写入到了java中。
在同步出版的书籍中,我们吧回收器描述成了一个整体,同时提供了测量数据显示在我们同步引用计数系统中,达到只有6毫秒的停顿时间测得的最大突变。端到端的执行时间,通常可以比作为并行(但是没有同步)
mark-and-sweep 回收器,尽管偶尔有显著的变化(在两个方面)。
在这里我们将重点放在详细的描述循环回收算法。它可以被其他的所执行。同时给出证明正确性的论据,这些论据将会进一步深入的介绍同步回收算法是怎样和为什么这样工作的。我们同时提供循环回收算法的所展现的测量数据量来作为一个整体,(每8个java的基准为一个整套)。
剩余的章节将会讲述一下内容:
第二章 介绍以前的实现方法
第三章 介绍我们同步回收垃圾算法的实现
describes our synchronous algorithm for col- lection of cyclic garbage
第四章 提供我们同步回收垃圾算法
第五章 证明同步循环回收算法的正确性
第六章 展示同步回收算法的效果
第七章 介绍同步垃圾回收相关的资料
最后得出我们的结论。
3.1章节和4.4章节包括详细的算法的伪代码,可以在第一次阅读时掠过这些内容。
2 循环回收的前期准备工作
解决循环回收在引用计数回收问题的前期准备工作已经整理为一下三个分类:
-特殊的编程语法,像
Bobrow 的组,或者是某些的方法编程方式
-使用一个很少调用的追踪回收的方法去回收循环的垃圾【8】;
-通过移除内部的引用计数器来搜索垃圾循环
这项技术做的很好的整理和算法在本书的第三章。第一个循环回收算法是Christopher设计的。我们的同步循环回收算法是以Mart ́ınez的研究为基础的,并且被Lins扩展,这部分已经刚刚被非常清晰的在本书的介绍过。
针对这些算法主要有两个基本的观点。第一个观点是垃圾循环只能在当引用计数减少至非0的值时才能被创建。如果引用计数增加,那么不会有垃圾被创建,如果其值减少到0,这部分垃圾就已经被发现。此外,如果引用计数器的值为1时,倾向于主导地位,减少到0 should be common。
第二个观点是在垃圾循环中,所有的引用计数都是内部的;因此,如果这些内部的计数,能被减少,垃圾循环就会被发现。
因此,当一个引用计数值减少,但是不为0时,它会被考虑成为一个垃圾循环的候选人,此时将执行一个本地搜索。这是一个深度优先的搜索,它由于内部指针剪去了计数值(?)。如果一个引用计数值为0,接下来一个垃圾循环会被发现而且会被回收;如果没有的话,另一个深度优先搜索会被执行,而且引用计数会被恢复。
Lins [20]扩展了最初的算法,现在通过缓冲的懒惰搜索代替了立即检测去执行。这有两个优势。第一个是经过一段时间,由于边缘缺失,引用计数的候选人会变成0。在这种情况下,这个节点会被非常简单的回收,或者由于边缘缺失,引用计数会重新增加,在这种情况下它会被忽略为一个候选人。其次,它会通畅禁止再次便利这些节点。
不幸的是,在最坏的情况下Lins 的算法is quadratic in the size of the graph,在循环中作为一个例子展示在图1中。他的算法考虑到在一个时间 root 1执行引用计数减法,并且在那个root采取行动之前恢复通行。
因此,Lins 的算法将会在候选人中执行一个全部扫描,直到它到达最后根,在这个点的时候,整个符合的循环会被收集起来。
3 同步循环回收
在这一章介绍我们的同步循环回收算法,同步循环回收算法应用的原理和Mart ́ınez 、Lins 一样,但是仅仅需要O(N+E) ,对于回收最差的情况时(N 是节点数 ,E是对象图形的边缘数),追踪垃圾回收因此更具有竞争力。
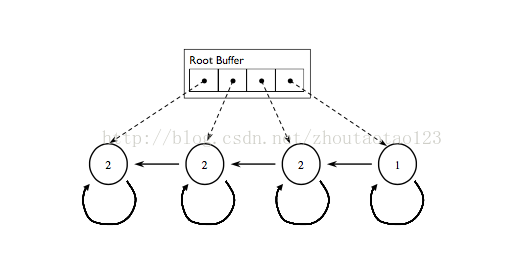
图1.符合循环的例子,引起
Lins的算法
,来展示二次复杂性
我们同时通过允许重新设置回收对象的大小来改进算法的实用性,通过重大的持续的更新可以实现排除固定的非循环的数据结构。?
我们的同步算法和
Lins
的算法很相似:当引用计数减少的时候,我们将循环垃圾的潜在的根放入到所谓的缓冲区中。我们处理这个缓冲然后通过减去内部的引用计数来寻找循环。
有两个主要改变来实现算法线性时间:首先,我们给每个对象增加了一个缓冲标志,来防止每个循环回收相同的对象被重复添加到根的缓冲中。这反过来线性的约束缓冲区的大小
。
第二点,我们分析根的内部传递闭包
,作为一个单独的图表,而且作为一套图表。这意味着,算法的复杂性受制于传递闭包的大小,反过来受制于
(根是通过使用缓存标志来区分的),当然,在实践中,我们希望传递闭包能够有明显的减小。
在实践中,我们发现第一个改变(使用缓存标志)使算法在运行的时候几乎不会有所改变;第二个改变(立即分析内部的图表)在算法运行的时候发生了巨大的变化。当我们应用lins的算法的时候,并且没有重新定义这个巨大的程序,垃圾回收延迟了不到一分钟的时间。
3.1 解释伪代码
我们现在来看下伪代码并且解释同步循环回收算法的每个执行过程。
此外,缓存标志,每个对象豆包括一个颜色和一个引用计数。例如,对象T表示buffered(T), color(T), and RC(T)。在使用的过程汇总,这些特性共同构成了每个对象内的一个单独的文字。
颜色的表示含义:
黑色: 正在使用或者没有被使用
灰色:可能得周期成员
白色:垃圾周期的成员
紫色: 可能的周期的根
绿色: 非循环的
红色: 候选周期
橙色: 候选周期等待被分界
表1.对象颜色的周期回收。 橙色和红色仅仅在同步周期回收中使用,在第四章中将会讲解这部分。
所有的对象开始变黑。在表1中显示了颜色在回收器中的使用。接下来我们来讨论一下绿色的使用(非循环的)。
算法显示在图2中,接下来详细的解释一下他的执行过程。外部的调用增加和减少作为一个指针来增加,移除或者是重写。当根的缓存移除,存储空间被耗用,或者当回收器因为一些其他的原因去释放周期垃圾的时候,回收周期会被调用。剩余的进程是用于内部的周期回收。特别提示,MarkGray, Scan, and ScanBlack 这三个进程是和Lins的算法一样的。

Increment(S) 当创建一个节点
S的引用的时候,引用计数器
T会自增并且颜色会标记为黑色,因此仍和对象的引用计数器只要增加了,就不能被垃圾回收。
Decrement(S) 当创建一个节点
S的引用的时候,引用计数器
T会减少,如果引用计数器等于0,这个释放进程将会被调用去释放垃圾节点。如果引用计数器不等于0,这个节点会被作为一个肯能的周期的根。
Release(S) 当季诶单的引用计数器等于0,这个内部的指针会被删除,这个对象会被标记为黑色,除非它已经被缓存,它已经被释放。如果它已经被缓存,他在根的缓存稍后将会被释放。(在进程中是
MarkRoots)
PossibleRoot(S) 当节点
S的引用计数减少,但是不等于0,它会被作为一个可能的垃圾周期的根。如果他的颜色已经是紫色,它就已经是一个候选的根了;如果不是紫色,它的颜色会被设置为紫色。接下来缓存标志会检查,我们已经执行了一个周期回收之后它是否已经编程了紫色。如果它没有被缓存,它将会被添加到可能的根的缓存当中。
CollectCycles() 当根的缓存区已经满了,或者当其他的情况,例如当出现低内存的时候,世纪的周期回收程序将会被调用。这个程序有三个阶段:
MarkRoots--移除内部的引用计数;
ScanRoots --当不等于0的时候,会重新存储引用计数;最后,
CollectRoots -- 回收周期垃圾。
MarkRoots() 标记阶段在节点
S的所有节点中,节点
S的指针已经在上次周期回收后在根内存中被存储。如果节点的颜色是紫色的(代表了一个可能的垃圾周期的根)而且引用计数并没有变成0,接下来调用
MarkGray(S) 区执行一个深度的首次搜索,被检索到的节点的颜色变成灰色而且内部计数会减少。否则这个节点会从内存的根中被移除,被缓存的标志被清理掉,如果引用计数等于0的时候,这个对象会被释放。
ScanRoots() 对于每个被
MarkGray(S) 所处理的节点
S,这个进程会出发Scan(S)将垃圾子图的颜色变成为白色或者重新将使用的子图变成黑色。
CollectRoots() 在ScanRoots阶段之后的CollectCycles进程,任何保持白色的节点会被循环垃圾处理而且可以从根的内存中获取到。这个进程触发CollectWhite处理根节点的缓存来回收垃圾;所有的根缓存已经被移除而且她们的缓存标志也已经被清理。
MarkGray(S) 这个进程在S的开始执行一个简单的深度首次遍历图表,将已经被访问过的节点变成灰色而且移除内部的引用计数,因为它已经没有了。
Scan(S) 如果这个进程找到一个灰色的对象,这个对象的引用计数远比0要大,接下来这个对象和从这个对象中可以获得的任何数据都处于存活状态;因此它将会调用ScanBlack(S) 来将可获取到的子图重新定义颜色,而且存储被MarkGray处理之后减少的引用计数器。然而,如果一个对象的颜色是灰色而且它的引用计数器等于0,接下来它会被染成白色,接下来调用Scan去处理的子集。注意,一个对象可以被染成白色,接下来如果从随后被发现的存活的节点中可以获得到,那么会被重新染成黑色。
ScanBlack(S) 这个进程执行MarkGray 的一个逆操作,获取节点,改变对象的颜色为黑色,然后重新存储它们的引用计数。
CollectWhite(S) 这个进程递归的释放所有的白色的对象,将它们重新染色成黑色,因为它们将会消失。如果一个白色的对象被缓存了,它不会被释放;当它在根的缓存中被找到的时候才会被释放。
3.2 非循环数据类型
通过观察一些对象是固定的非循环的,可以使循环回收获得一个显著且不变因子的改善(constant-factor)。我们推测,它们会包含许多对象在诸多的应该当中。因此,如果我们可以避免循环回收固定的非循环的对象,我们会显著的减少循环回收的开销。
在java当中动态的class加载复杂的固定的非循环的数据结构的结果。我们使用了一个非常简单的方案作为加载累的一部分。
非循环的class需要包括:
--标量
--引用那些非循环而且是最终的类
--以上两者任意一个的数组
我们通过使用特殊的绿色来标记哪些类是非循环的。绿色的对象是北循环回收算法所忽略掉的,除非当一个死循环指向了绿色的对象,只要又死循环它们就会被回收。为了最简单的来演示,我们并没有在本文中的算法中引用绿色对象的详细介绍;这些修改是非常直接了当的。
非循环的计算是非常简单的,而且是非常有效的,通常减少对象作为循环的根的一个量级,将会在第6章中给大家介绍。在一个静态的编译器中,一个非常复杂的程序分析会被应用降低绿色对象的百分比。
4 同步循环回收
现在我们以之前章节的同步算法的原理为基础,来介绍同步循环回收算法。
为了理解循环回收算法,接下来多处理引用计数系统会被非常抽象的展示出来:修改器创造和销毁了对象的引用(在堆或者栈中),对应的增长和降低的操作会在本地的内存中排列成一个队列,被称作为内存修改器。内存修改器会将修改器的内存定期的传送给回收器,它应用引用计数更新、释放那些计数为0的对象,而且回定期的执行循环回收。
时间被分割成多个时间周期,而且每个处理器必须准确的在每个时间周期内将执行内存传送给回收器。先把这个要求放到一边,在正常的运行当中,是需要在处理器和回收器之间没有同步发生的。
当所有在一个时间周期的变化的内存已经被转移到回收器,在这个时间周期中刚刚完成的增长会被应用;然而,一直刀下一个时间周期的边界,降低才会被应用。这是为了防止释放活跃的数据,否则可能会发生修改器之间的竞争发生。这个方法的优势是,从来不需要去同时终止所有的修改器。
在执行的过程中,回收紧紧跟踪更新堆的指针,而且在追踪的过程中快照指针是在每个时间周期的边界。我们的算法和Deutsch- Bobrow 是相似的--推迟引用计数。我们的同步引用计数的实施是和DeTreville的引用计数回收非常相似的。这个回收算法已经被Bacon等人详细的介绍过了。