1、求累积分布函数 sum + over
cookie create_time pv
cookie1, 2015-04-10, 1
cookie1, 2015-04-11, 5
cookie1, 2015-04-12, 7
cookie1, 2015-04-13, 3
cookie1, 2015-04-14, 2
cookie1, 2015-04-15, 4
cookie1, 2015-04-16, 4
select
cookieid,
createtime,
pv,
# 按create_time排序从第一行到当前行
sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1,
# 按create_time排序从第一行到当前行
sum(pv) over (partition by cookieid order by createtime) as pv2,
# 按create_time全部行
sum(pv) over (partition by cookieid) as pv3,
# 按create_time排序从当前行的前三行到当前行
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4,
# 按create_time排序从当前行的前三行到当前行的后一行
sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5,
# 按create_time排序从当前行到最后一行
sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6
from cookie1;
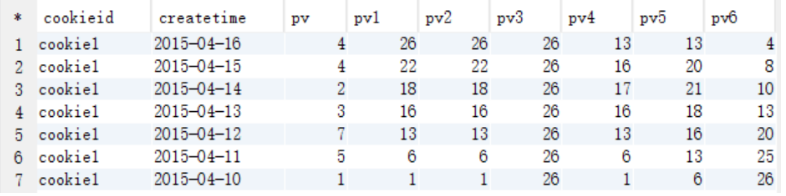
注意:
如果不指定ROWS BETWEEN,默认为从起点到当前行;
如果不指定ORDER BY,则将分组内所有值累加;
关键是理解ROWS BETWEEN含义,也叫做WINDOW子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING:表示到后面的终点
min、max、avg使用类似。
2、查找相邻位置的行的某些列,lag/lead + over
lag:向前查找
lag(列名,偏移量,默认值)
lead:向后查找
lead(列名,偏移量,默认值)
# 原始数据
ID NAME
-------------
1 1name
2 2name
3 3name
4 4name
5 5name
2.1 按照id顺序,找到同name相邻的前一个name
select
ID
,NAME
,lag(NAME,1,0) over(order by ID) as n1
from table_B
ID NAME n1
---------------------
1 1name 0
2 2name 1name
3 3name 2name
4 4name 3name
5 5name 4name
2.2 按照id顺序,找到同name相邻的后一个name
select
ID
,NAME
,lead(NAME,1,0) over(order by ID) as n2
from table_B
ID NAME n2
---------------------
1 1name 2name
2 2name 3name
3 3name 4name
4 4name 5name
5 5name 0
2.3 按照id顺序,找到同name相邻的后2个name,如果没有填充默认值 none
select
ID
,NAME
,lead(NAME,2,'none') over(order by ID) as n2
from table_B
ID NAME n2
---------------------
1 1name 3name
2 2name 4name
3 3name 5name
4 4name 'none'
5 5name 'none'
3、FIRST_VALUE , LAST_VALUE
cookieid | create_time | url
------------------------------------
cookie1 2015-04-10 10:00:02 url2
cookie1 2015-04-10 10:00:00 url1
cookie1 2015-04-10 10:03:04 url3
cookie1 2015-04-10 10:50:05 url6
cookie1 2015-04-10 11:00:00 url7
cookie1 2015-04-10 10:10:00 url4
cookie1 2015-04-10 10:50:01 url5
cookie2 2015-04-10 10:00:02 url22
cookie2 2015-04-10 10:00:00 url11
cookie2 2015-04-10 10:03:04 url33
cookie2 2015-04-10 10:50:05 url66
cookie2 2015-04-10 11:00:00 url77
cookie2 2015-04-10 10:10:00 url44
cookie2 2015-04-10 10:50:01 url55
3.1 FIRST_VALUE: 取分组内排序后,截止到当前行,第一个值
SELECT
cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM table_C;
# 查询结果
cookieid createtime url rn first1
---------------------------------------------------------
cookie1 2015-04-10 10:00:00 url1 1 url1
cookie1 2015-04-10 10:00:02 url2 2 url1
cookie1 2015-04-10 10:03:04 url3 3 url1
cookie1 2015-04-10 10:10:00 url4 4 url1
cookie1 2015-04-10 10:50:01 url5 5 url1
cookie1 2015-04-10 10:50:05 url6 6 url1
cookie1 2015-04-10 11:00:00 url7 7 url1
cookie2 2015-04-10 10:00:00 url11 1 url11
cookie2 2015-04-10 10:00:02 url22 2 url11
cookie2 2015-04-10 10:03:04 url33 3 url11
cookie2 2015-04-10 10:10:00 url44 4 url11
cookie2 2015-04-10 10:50:01 url55 5 url11
cookie2 2015-04-10 10:50:05 url66 6 url11
cookie2 2015-04-10 11:00:00 url77 7 url11
3.2 LAST_VALUE: 取分组内排序后,截止到当前行,最后一个值
SELECT
cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM table_C
cookieid createtime url rn last1
-----------------------------------------------------------------
cookie1 2015-04-10 10:00:00 url1 1 url1
cookie1 2015-04-10 10:00:02 url2 2 url2
cookie1 2015-04-10 10:03:04 url3 3 url3
cookie1 2015-04-10 10:10:00 url4 4 url4
cookie1 2015-04-10 10:50:01 url5 5 url5
cookie1 2015-04-10 10:50:05 url6 6 url6
cookie1 2015-04-10 11:00:00 url7 7 url7
cookie2 2015-04-10 10:00:00 url11 1 url11
cookie2 2015-04-10 10:00:02 url22 2 url22
cookie2 2015-04-10 10:03:04 url33 3 url33
cookie2 2015-04-10 10:10:00 url44 4 url44
cookie2 2015-04-10 10:50:01 url55 5 url55
cookie2 2015-04-10 10:50:05 url66 6 url66
cookie2 2015-04-10 11:00:00 url77 7 url77
4、NTILE(),RANK(),ROW_NUMBER(),DENSE_RANK()、CUME_DIST()、PERCENT_RANK()
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值
NTILE不支持ROWS BETWEEN;如果切片不均匀,默认增加第一个切片的分布
SELECT
cookieid,
createtime,
pv,
--分组内将数据分成2片
NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn1,
--分组内将数据分成3片
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2,
--将所有数据分成4片
NTILE(4) OVER(ORDER BY createtime) AS rn3
FROM lxw1234
ORDER BY cookieid,createtime;
cookieid day pv rn1 rn2 rn3
-------------------------------------------------
cookie1 2015-04-10 1 1 1 1
cookie1 2015-04-11 5 1 1 1
cookie1 2015-04-12 7 1 1 2
cookie1 2015-04-13 3 1 2 2
cookie1 2015-04-14 2 2 2 3
cookie1 2015-04-15 4 2 3 3
cookie1 2015-04-16 4 2 3 4
cookie2 2015-04-10 2 1 1 1
cookie2 2015-04-11 3 1 1 1
cookie2 2015-04-12 5 1 1 2
cookie2 2015-04-13 6 1 2 2
cookie2 2015-04-14 3 2 2 3
cookie2 2015-04-15 9 2 3 4
cookie2 2015-04-16 7 2 3 4
RANK(),ROW_NUMBER(),DENSE_RANK() 都是用于排序,不过排序结果有差异,细节如下
select
user_id,user_type,sales,
# sales相同的值rank一样,也就是说会出现并列的情况,并列之后rank会跳跃
RANK() over (partition by user_type order by sales desc) as r,
# 不会出现并列,记录数和rank值对应,依次递增
ROW_NUMBER() over (partition by user_type order by sales desc) as rn,
# sales相同的值rank一样,也就是说会出现并列的情况,并列之后rank不会跳跃增加
DENSE_RANK() over (partition by user_type order by sales desc) as dr
from
order_detail;
+----------+------------+--------+----+-----+-----+
| user_id | user_type | sales | r | rn | dr |
+----------+------------+--------+----+-----+-----+
| wutong | new | 6 | 1 | 1 | 1 |
| qishili | new | 5 | 2 | 2 | 2 |
| lilisi | new | 5 | 2 | 3 | 2 |
| wanger | new | 3 | 4 | 4 | 3 |
| zhangsa | new | 2 | 5 | 5 | 4 |
| qibaqiu | new | 1 | 6 | 6 | 5 |
| liiu | new | 1 | 6 | 7 | 5 |
| liwei | old | 3 | 1 | 1 | 1 |
| wangshi | old | 2 | 2 | 2 | 2 |
| lisi | old | 1 | 3 | 3 | 3 |
+----------+------------+--------+----+-----+-----+
CUME_DIST:用户统计占比,小于等于当前值的行数/分组内总行数
–比如,统计小于等于当前薪水的人数,所占总人数的比例
SELECT
dept,
userid,
sal,
# 不分部门,全部总共5个人
CUME_DIST() OVER(ORDER BY sal) AS rn1,
# 按部门分组
CUME_DIST() OVER(PARTITION BY dept ORDER BY sal) AS rn2
FROM lxw1234;
dept userid sal rn1 rn2
-------------------------------------------
d1 user1 1000 0.2 0.3333333333333333
d1 user2 2000 0.4 0.6666666666666666
d1 user3 3000 0.6 1.0
d2 user4 4000 0.8 0.5
d2 user5 5000 1.0 1.0
# rn1: 没有partition,所有数据均为1组,总行数为5,
# 第一行:小于等于1000的行数为1,因此,1/5=0.2
# 第三行:小于等于3000的行数为3,因此,3/5=0.6
# rn2: 按照部门分组,dpet=d1的行数为3,
# 第二行:小于等于2000的行数为2,因此,2/3=0.66666
PERCENT_RANK:分组内当前行的RANK值-1/分组内总行数-1
SELECT
dept,
userid,
sal,
PERCENT_RANK() OVER(ORDER BY sal) AS rn1, --分组内
RANK() OVER(ORDER BY sal) AS rn11, --分组内RANK值
SUM(1) OVER(PARTITION BY NULL) AS rn12, --分组内总行数
PERCENT_RANK() OVER(PARTITION BY dept ORDER BY sal) AS rn2
FROM lxw1234;
dept userid sal rn1 rn11 rn12 rn2
---------------------------------------------------
d1 user1 1000 0.0 1 5 0.0
d1 user2 2000 0.25 2 5 0.5
d1 user3 3000 0.5 3 5 1.0
d2 user4 4000 0.75 4 5 0.0
d2 user5 5000 1.0 5 5 1.0
rn1: rn1 = (rn11-1) / (rn12-1)
第一行,(1-1)/(5-1)=0/4=0
第二行,(2-1)/(5-1)=1/4=0.25
第四行,(4-1)/(5-1)=3/4=0.75
rn2: 按照dept分组,
dept=d1的总行数为3
第一行,(1-1)/(3-1)=0
第三行,(3-1)/(3-1)=1
5、GROUPING SETS、CUBE、ROLLUP
原始数据
month day cookie
2015-03 2015-03-10 cookie1
2015-03 2015-03-10 cookie5
2015-03 2015-03-12 cookie7
2015-04 2015-04-12 cookie3
2015-04 2015-04-13 cookie2
2015-04 2015-04-13 cookie4
2015-04 2015-04-16 cookie4
2015-03 2015-03-10 cookie2
2015-03 2015-03-10 cookie3
2015-04 2015-04-12 cookie5
2015-04 2015-04-13 cookie6
2015-04 2015-04-15 cookie3
2015-04 2015-04-15 cookie2
2015-04 2015-04-16 cookie1
GROUPING SETS:
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM table_A
GROUP BY month,day
GROUPING SETS (month,day)
ORDER BY GROUPING__ID;
month day uv GROUPING__ID
------------------------------------------------
2015-03 NULL 5 1
2015-04 NULL 6 1
NULL 2015-03-10 4 2
NULL 2015-03-12 1 2
NULL 2015-04-12 2 2
NULL 2015-04-13 3 2
NULL 2015-04-15 2 2
NULL 2015-04-16 2 2
等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID
FROM table_A GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID
FROM table_A GROUP BY day
再给一个例子
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM table_A
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
ORDER BY GROUPING__ID;
month day uv GROUPING__ID
------------------------------------------------
2015-03 NULL 5 1
2015-04 NULL 6 1
NULL 2015-03-10 4 2
NULL 2015-03-12 1 2
NULL 2015-04-12 2 2
NULL 2015-04-13 3 2
NULL 2015-04-15 2 2
NULL 2015-04-16 2 2
2015-03 2015-03-10 4 3
2015-03 2015-03-12 1 3
2015-04 2015-04-12 2 3
2015-04 2015-04-13 3 3
2015-04 2015-04-15 2 3
2015-04 2015-04-16 2 3
等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID
FROM table_A GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID
FROM table_A GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID
FROM table_A GROUP BY month,day
CUBE:
根据GROUP BY的维度的所有组合进行聚合,n个维度,所有的组合就有 种
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM table_A
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
month day uv GROUPING__ID
--------------------------------------------
NULL NULL 7 0
2015-03 NULL 5 1
2015-04 NULL 6 1
NULL 2015-04-12 2 2
NULL 2015-04-13 3 2
NULL 2015-04-15 2 2
NULL 2015-04-16 2 2
NULL 2015-03-10 4 2
NULL 2015-03-12 1 2
2015-03 2015-03-10 4 3
2015-03 2015-03-12 1 3
2015-04 2015-04-16 2 3
2015-04 2015-04-12 2 3
2015-04 2015-04-13 3 3
2015-04 2015-04-15 2 3
等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID
FROM table_A
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID
FROM table_A GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID
FROM table_A GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID
FROM table_A GROUP BY month,day
ROLLUP
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合,筛选出所有包含该维度的集合。
比如,以month维度进行层级聚合:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM table_A
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
month day uv GROUPING__ID
---------------------------------------------------
NULL NULL 7 0
2015-03 NULL 5 1
2015-04 NULL 6 1
2015-03 2015-03-10 4 3
2015-03 2015-03-12 1 3
2015-04 2015-04-12 2 3
2015-04 2015-04-13 3 3
2015-04 2015-04-15 2 3
2015-04 2015-04-16 2 3
可以实现这样的上钻过程:
月天的UV->月的UV->总UV
--把month和day调换顺序,则以day维度进行层级聚合:
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM table_A
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
day month uv GROUPING__ID
-------------------------------------------------------
NULL NULL 7 0
2015-04-13 NULL 3 1
2015-03-12 NULL 1 1
2015-04-15 NULL 2 1
2015-03-10 NULL 4 1
2015-04-16 NULL 2 1
2015-04-12 NULL 2 1
2015-04-12 2015-04 2 3
2015-03-10 2015-03 4 3
2015-03-12 2015-03 1 3
2015-04-13 2015-04 3 3
2015-04-15 2015-04 2 3
2015-04-16 2015-04 2 3
可以实现这样的上钻过程:
天月的UV->天的UV->总UV
(这里,根据天和月进行聚合,和根据天聚合结果一样,
因为有父子关系,如果是其他维度组合的话,就会不一样)