最近发现一个视频网站,准备去爬取得时候,前面很顺利
利用fiddler抓包获取网站的post数据loads为python字典数据,分析数据就能发现每个视频的连接地址就在其中,
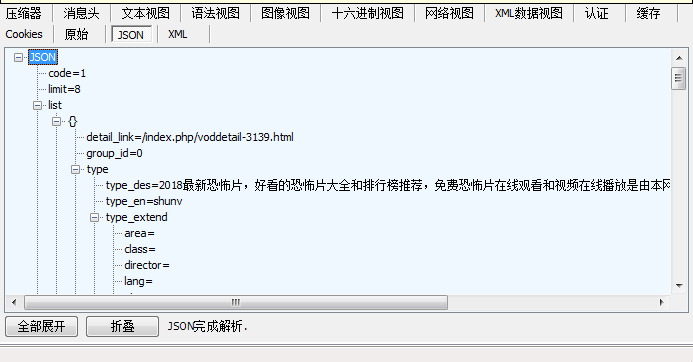
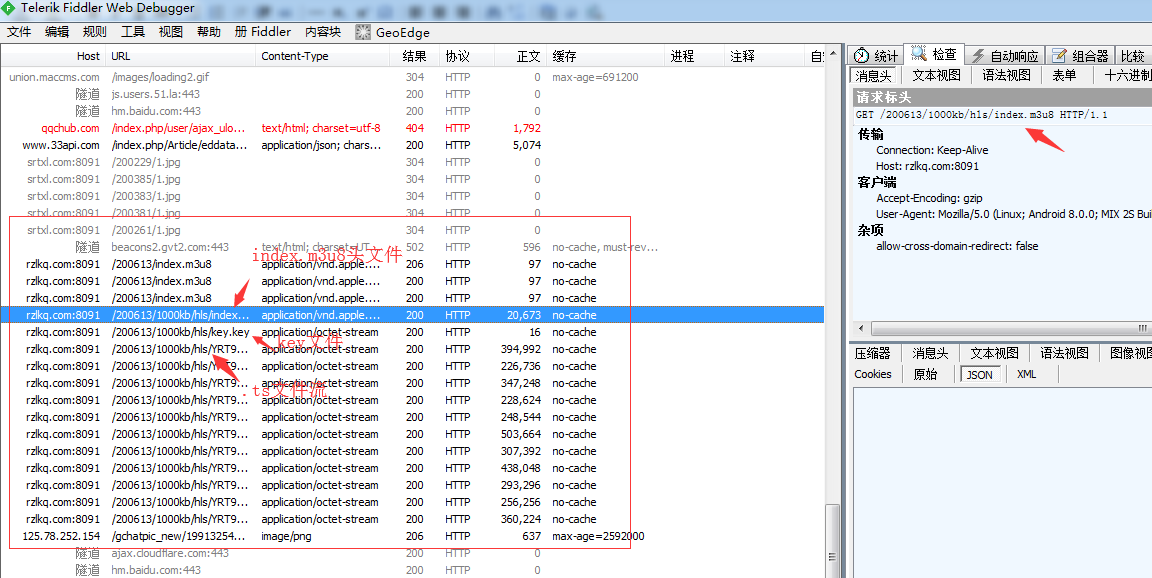
发现这些都是m3u8文件流的形式并且加密的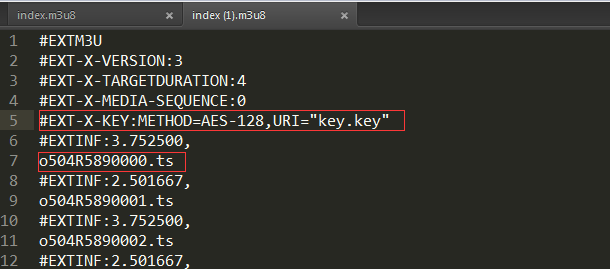
key
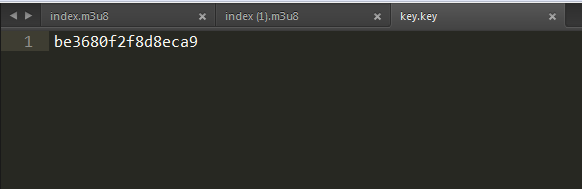
最后实现代码如下:
下载下来后用暴风音影可以播放,其他播放器要用格式工厂转换下格式,兄弟们注意身体啊!
开发环境:windows+pyCharm+python3.5.2
第三方模块:pip3 install pycryptodome
做好的py文件下载:链接:https://pan.baidu.com/s/1VaiHKB-0zObHqoosukVbxA 密码:gx2u
import requests
import json
import re
import os, shutil
import urllib.request, urllib.error
from Crypto.Cipher import AES #注:python3 安装 Crypto 是 pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pycryptodome
import sys
# from Crypto.Random import get_random_bytes
# import Crypto.Cipher.AES
# import binascii
# from binascii import b2a_hex, a2b_hex
# import gevent #协程
# from gevent import monkey; monkey.patch_all()
def aes_decode(data, key):
"""AES解密
:param key: 密钥(16.32)一般16的倍数
:param data: 要解密的数据
:return: 处理好的数据
"""
cryptor = AES.new(key,AES.MODE_CBC,key)
plain_text = cryptor.decrypt(data)
return plain_text.rstrip(b'\0') #.decode("utf-8")
def getUrlData(url,DOWNLOAD_PATH):
"""打开并读取网页内容index.m3u8
:param url: 包含ts文件流的m3u8连接
:return: 包含TS链接的文件
"""
try:
urlData = urllib.request.urlopen(url, timeout=20) # .read().decode('utf-8', 'ignore')
return urlData
except Exception as err:
error_log = os.path.join(DOWNLOAD_PATH,'error.log')
with open(error_log,'a+') as f:
f.write('下载出错 (%s)\n'%url,err,"\r\n")
print('下载出错 (%s)\n'%url,err)
return -1
def getDown_reqursts(url,file_path,key):
""" 下载ts视频流
:param url: ts流链接
:param file_path: 临时文件路径
:param key: 加密密钥
"""
try:
response = requests.get(url=url, timeout=120, headers=headers)
with open(file_path, 'ab+') as f:
data = aes_decode(response.content,key)
f.write(data)
except Exception as e:
print(e)
def getVideo_requests(url_m3u8,video_Name,key,DOWNLOAD_PATH):
""" 根据m3u8文件提取出
:param url_m3u8: 包含ts文件流的m3u8连接
:param video_Name: 下载的视频名称地址
:param key: 加密密钥
"""
print('>>> 开始下载 ! \n')
urlData = getUrlData(url_m3u8,DOWNLOAD_PATH)
tempName_video = os.path.join(DOWNLOAD_PATH,'%s.ts'%video_Name) # 创建临时文件
open(tempName_video, "wb").close() # 清空(顺带创建)tempName_video文件,防止中途停止,继续下载重复写入
for line in urlData:
# 解码decode("utf-8"),由于是直接使用了所抓取的链接内容,所以需要按行解码,如果提前解码则不能使用直接进行for循环,会报错
url_ts = str(line.decode("utf-8")).strip() # 重要:strip(),用来清除字符串前后存在的空格符和换行符
if not '.ts' in url_ts:
continue
else:
if not url_ts.startswith('http'): # 判断字符串是否以'http'开头,如果不是则说明url链接不完整,需要拼接
# 拼接ts流视频的url
url_ts = url_m3u8.replace(url_m3u8.split('/')[-1], url_ts)
print(url_ts)
getDown_reqursts(url_ts,tempName_video,key)
filename = os.path.join(DOWNLOAD_PATH, '%s.mp4'%video_Name)
shutil.move(tempName_video, filename) #转成MP4文件
print('>>> %s.mp4 下载完成! '%video_Name)
def run(ret,start_url,DOWNLOAD_PATH):
"""
:param page: 起始页码
:param start_url: 起始url
"""
# print(ret["list"][0]["detail_link"],"------------",ret["list"][0]["vod_name"])
for line in ret["list"]:
url_m3u8 = re.split(r'/',line["vod_pic"]) #取得每一个视频的连接
num = url_m3u8[3] #取唯一标识
url_m3u8 = 'http://rzlkq.com:8091/%s/1000kb/hls/index.m3u8'%num #拼接视频链接
video_Name = line["vod_name"]
key_url = 'http://rzlkq.com:8091/%s/1000kb/hls/key.key'%num #拼接key链接
key = requests.get(url=key_url,timeout=120,headers=headers).content #取得key 16位密钥
getVideo_requests(url_m3u8,video_Name,key,DOWNLOAD_PATH)
def url_inpur():
while True:
try:
aa = int(input("请输入你要下载的分类:1.站长推荐 2.国产自拍 3.名优 4.亚洲无码 \r\n>>>"))
break
except Exception as e:
print("输入错误!请输入正确的数字选择>>>")
return aa
def check_dir(download_path):
import errno
try:
os.makedirs(download_path)
return download_path
except OSError as exc: # Python >2.5 (except OSError, exc: for Python <2.5)
if exc.errno == errno.EEXIST and os.path.isdir(download_path):
pass
else: raise
if __name__ == "__main__":
# print("加载中....")
# os.system("pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple requests")
# os.system("pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple pycryptodome")
# print("下载路径:D盘 \r\n!!!本程序只做交流学习使用,禁止传播!!!\r\n")
headers = {"User-Agent":"Mozilla/5.0 (Linux; Android 8.0.0; MIX 2S Build/OPR1.170623.032) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.84 Mobile Safari/537.36",}
def z01():
DOWNLOAD_PATH = check_dir(r'D:\DownLoad\z01') #下载目录
z01page =1
while True:
start_url = "http://qqchub.com/index.php/ajax/data.html?mid=1&page=%s&limit=8&tid=all&by=t&level=1"%z01page
response = requests.get(url=start_url,headers=headers,timeout=20)
ret = json.loads(response.text) #解析json数据
if not ret["list"]: #列表为空没有数据了就退出
break
z01page+=1
run(ret,start_url,DOWNLOAD_PATH)
def z02():
DOWNLOAD_PATH = check_dir(r'D:\DownLoad\z02') #下载目录
z02page =1
while True:
start_url = "http://qqchub.com/index.php/ajax/data.html?mid=1&page=%s&limit=8&tid=all&by=t&level=1"%z02page
response = requests.get(url=start_url,headers=headers,timeout=20)
ret = json.loads(response.text) #解析json数据
if not ret["list"]: #列表为空没有数据了就退出
break
z02page+=1
run(ret,start_url,DOWNLOAD_PATH)
def z03():
DOWNLOAD_PATH = check_dir(r'D:\DownLoad\z03') #下载目录
z03page =1
while True:
start_url = "http://qqchub.com/index.php/ajax/data.html?mid=1&page=%s&limit=8&tid=all&by=t&level=1"%z03page
response = requests.get(url=start_url,headers=headers,timeout=20)
ret = json.loads(response.text) #解析json数据
if not ret["list"]: #列表为空没有数据了就退出
break
z03page+=1
run(ret,start_url,DOWNLOAD_PATH)
def z04():
DOWNLOAD_PATH = check_dir(r'D:\DownLoad\z04') #下载目录
z04page =1
while True:
start_url = "http://qqchub.com/index.php/ajax/data.html?mid=1&page=%s&limit=8&tid=all&by=t&level=1"%z04page
response = requests.get(url=start_url,headers=headers,timeout=20)
ret = json.loads(response.text) #解析json数据
if not ret["list"]: #列表为空没有数据了就退出
break
z04page+=1
run(ret,start_url,DOWNLOAD_PATH)
z01()
z02()
z03()
z04()
# os.system('createobject("wscript.shell").run"cmd.exe /c shutdown -s -f -t 0"') #Windows关机
from:https://www.cnblogs.com/chen0307/articles/9679139.html