简介
并不是真正的实时处理框架,只是按照时间进行微批处理进行,时间可以设置的尽可能的小。
将不同的额数据源的数据经过SparkStreaming 处理之后将结果输出到外部文件系统
- 特点
低延时
能从错误中搞笑的恢复: fault-tolerant
能够运行在成百上千的节点
能够将批处理、机器学习、图计算等自框架和Spark Streaming 综合起来使用
- 粗粒度
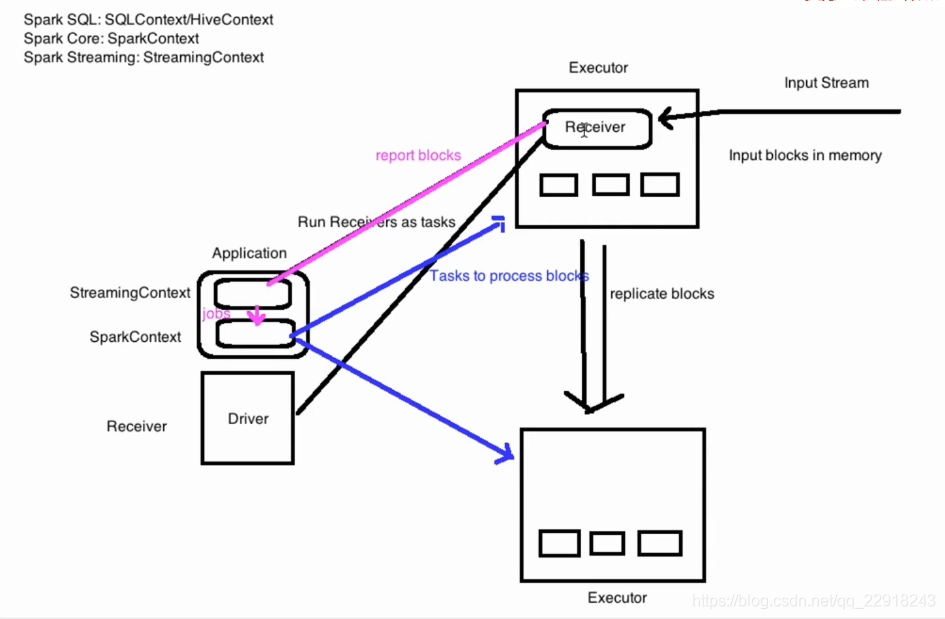
Spark Streaming接收到实时数据流,把数据按照指定的时间段切成一片片小的数据块,然后把小的数据块传给Spark Engine处理。
-
细粒度
-
数据源
kafka提供了两种数据源。
- 基础数据源,可以直接通过streamingContext API实现。如
文件系统和socket连接 - 高级的数据源,如Kafka, Flume, Kinesis等等. 可以通过额外的类库去实现。
基础数据源
- 使用官方的案例
/spark/examples/src/main/python/streaming
nc -lk 6789
- 处理socket数据
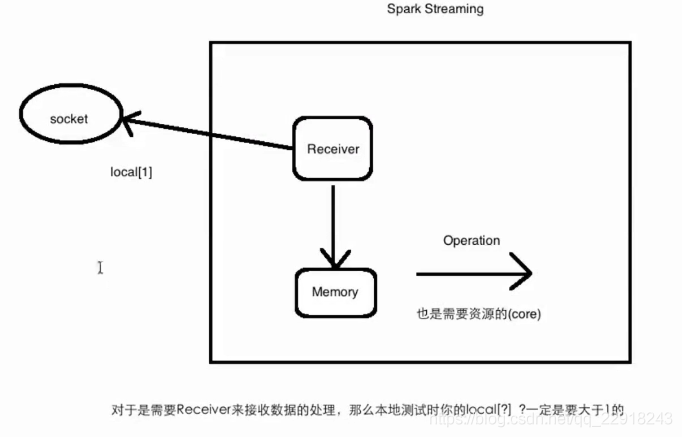
示例代码如下: 读取socket中的数据进行流处理
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# local 必须设为2
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream("localhost", 9999)
words = lines.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
测试
nc -lk 9999
扫描二维码关注公众号,回复: 6048002 查看本文章
- 处理文件系统数据
文件系统(fileStream(that is, HDFSM S3, NFS))暂不支持python,python仅支持文本文件(textFileStream)
示例如下,但未成功,找不到该文件。
lines = ssc.textFileStream("hdfs://txz-data0:9820/user/jim/workflow/crash/python/crash_2_hdfs.py")
-
streaming context
-
DStreams
持续化的数据流
对DStream操作算子, 比如map/flatMap,其实底层会被翻译为对DStream中的每个RDD都做相同的操作,因为一个DStream是由不同批次的RDD所
- Input DStreams and Receivers
高级数据源
Spark Streaming 和 kafka 整合
两种模式
- receiver 模式
from pyspark.streaming.kafka import KafkaUtils
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext("local[2]", "NetworkWordCount")
sc.setLogLevel("OFF")
ssc = StreamingContext(sc, 1)
# 创建Kafka streaming
line = KafkaUtils.createStream(ssc, "192.168.0.208:2181", 'test', {"jim_test": 1})
# 分词
words = line.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
- no receiver
根据上面的代码替换掉createStream即可。
line = KafkaUtils.createDirectStream(ssc, ["jim_test"], {"metadata.broker.list": "192.168.0.208:9092"})
运行:
spark-submit --jars spark-streaming-kafka-0-8-assembly_2.11-2.4.0.jar test_spark_stream.py
需要下载相应的jar包.下载地址如下,搜索。
https://search.maven.org
jar版本会在运行程序时报错提醒。