
因特网是最大的计算机网络,它自诞生以来也一直存在着集中式与分布式两种不同的工作方式。客户/服务器模式(client/Server mode,简称C/S)是因特网最传统、最成熟的集中式工作模式,许多重要的因特网应用协议(如HTTP、FTP、SMTP等)采用了这一模式。在这种集中式的模式下,服务器将一直运行,被动地等待客户的主动接人,客户将请求发给服务器,服务器返回给客户所要的信息。客户/服务器模式在因特网的最初阶段工作得非常好,然而,随着因特网在规模上不断膨胀、在功能上不断扩展,服务器的负担越来越重,客户/服务器模式的低效率与难以扩展的缺陷暴露出来,它不再能适应需要极高效率与巨大规模的现代因特网。
1. P2P 网络基本概念
当传统的客户/服务器模式不再能适应现代因特网需求的时候,人们将目光重新放回到被长久忽视的分布式系统上,对等模式(Peer-to-Peer mode,简称P2P)正是在这种情况下受到重视并很快成为研究热点。“ Peer”一词在英文中的意思是“同等、对等的人”,故而 “Peer-to-Peer”译为“对等(计算)”;国内很多人将 P2P 称作“点对点”,这是不恰当的,因为“点对点”是“ Point-to-Point”,和 P2P 不是一回事。对等模式的本质思想在于打破传统的客户/服务器模式,让一切网络成员享有自由、平等、互联的功能,不再有客户、服务器之分,任何两个网络节点之间都能共享文件、传递消息。图2-9反映出从C/S到 P2P的转变,Peers之间的逻辑连接构建在物理连接的基础上。

对等网络是分布式系统与计算机网络相结合的产物,是采用对等模式工作的计算机网络。图 2-10 描绘了随着分布式系统规模的扩展,分布式计算的模式发生相应的改变。在对等网络中,每个网络节点在行为上是自由的,在功能上是平等的,在连接上是互联的,所有节点分布式地自组织成一个整体网络,因此,它能够极大程度地提高网络效率,充分利用网络带宽,开发每个网络节点的潜力。
2. P2P 网络的特性
P2P 网络区别于其他系统的本质特点如下。
(1)网络拓扑结构严格
P2P 网络在网络应用层构建了一个有(严格)拓扑结构的覆盖网,覆盖网拓扑结构对于一个 P2P 网络具有基础性的意义,系统的其他许多机制如分布式散列表、路由、负载均衡、容错与自适应、自组织都以它为基础。


(2)节点和数据对象位置确定
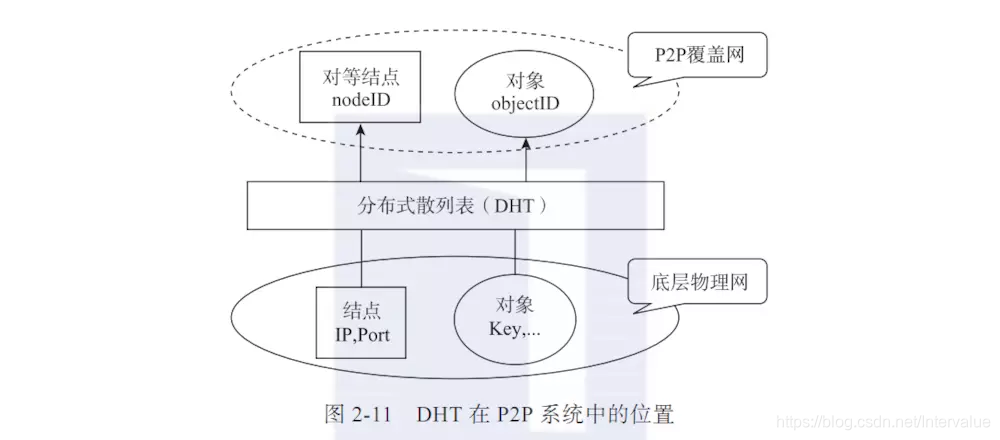
分布式散列表(DHT)是P2P网络的核心设施。如图2-11所示,它通常基于一致性散列函数,提供对于任何一个节点、数据对象在覆盖网中的位置映射。这一点在结构化P2P网络中尤其重要,因为它保证了能够准确地定位到某个节点或者数据对象。具体地说,如果分布式散列表采用一致性散列函数H(),对于某个网络节点(IP,Port,…),该节点在覆盖网上将有唯一对应的“节点标识”nodeID=H(IF,Fort,…),IP为节点IP地址,Port为端口号,“…”表示其他属性;对于某个数据对象(Key,…),它在覆盖网上也有唯一的“对象标识”objectID=H(Key,…),Key 为对象关键码,“…”表示其他属性。对于节点而言,nodelD确定了它的覆盖网位置,对于数据对象而言,objectID确定了它的索引信息在覆盖网上的存放位置。
(3)高效路由
基于P2P覆盖网与分布式散列表,P2P网络通常有适合自己的路由算法,以保证高效路由。任意两个节点间定位所需的覆盖网路由跳数典型地为 TTL( 无结构网络 ) 或 log N(结构化网络),TTL(time to live) 为跳数限制,N 为网络节点总数。因为覆盖网与物理网的不一致性,实际 IP 路由跳数会高于覆盖网路由跳数,但仍可以控制在 log N 的常数倍范围之内。
(4)负载均衡
P2P 网络使用分布式散列表将节点、数据对象分布到覆盖网上,由于它通常使用一致性散列函数,所以这种分布是均衡的。所有节点大致均匀地分布在整个覆盖网中,所有数据对象的索引大致均匀地分布在所有节点中,即使有新节点加入、旧节点离开、新对象发布、旧对象删除,一致性散列函数都能保证高效的动态调整和调整后网络仍然保持很好的负载均衡。负载均衡是分布式系统努力追求的系统属性,它对于 P2P 系统的高效率、可扩展性、动态自适应具有重要意义。
(5)容错与动态自适应
P2P网络是动态变化的,不断地有新节点加人、旧节点离开、新对象发布、旧对象删除,当这些发生以后,P2P网络必须有很好的自适应性,做高效的调整,以保持网络的拓扑结构、位置映射、负载均衡和路由信息的更新。如上节所述,自适应最重要的是更新节点状态,自适应的方法有周期性探测、按需检测、捎带确认等。
(6)行为的自由性与匿名性
P2P网络是一个自由、平等的网络,两个对等节点之间做什么事情、采取什么样的行为、交换哪些信息,完全由双方自由决定。另一方面,P2P 网络中的用户是匿名的,因为分布式散列表采用安全散列函数将用户信息、数据对象信息映射到了一个表面上看起来没有任何意义的数值标识 ID,这个 ID 唯一地代表用户和数据对象。由于安全散列函数的单向性与抗冲突性,不可能从此 ID 破解出它所代表的信息。
3. P2P网络拓扑构建与维护技术
P2P网络的最大特点和难点,在于它极大的动态性:不断有新节点加入、旧节点离开、节点失效等情况发生。面对这样一个动态环境,P2P网络需要一套健全、可行的方法来处理这些情况:在新节点加人时通知其他节点新成员的到来,在旧节点离开时通知其他节点老成员的离去,而最难的是需要高效、合理地检测到节点失效并及时修复P2P网络。下面介绍基于 Gossip的P2P网络拓扑构建和维护技术。
Gossip算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节点可以通过网络连通,最终它们的状态就都是一致的,当然这也是疫情传播的特点。
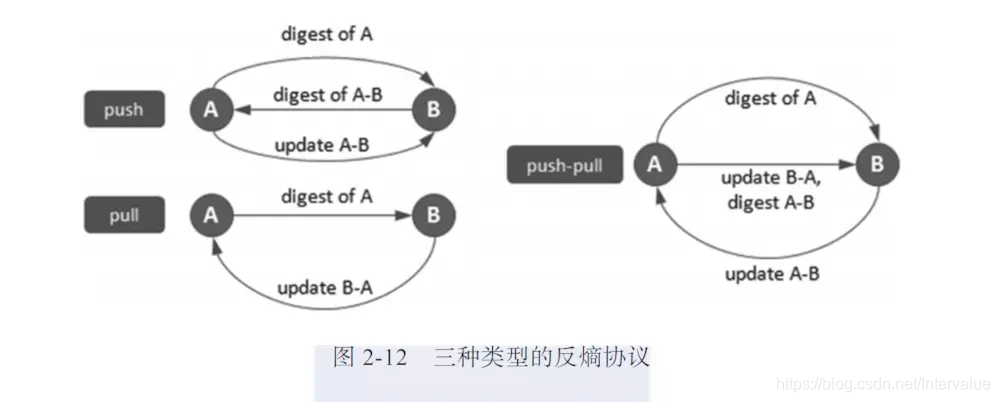
要注意到的一点是,即使有的节点因宕机而重启,有新节点加入,但经过一段时间后,这些节点的状态也会与其他节点达成一致,也就是说,Gossip 天然具有分布式容错的优点。Gossip是一个带冗余的容错算法,更进一步说,Gossip是一个最终一致性算法。虽然无法保证在某个时刻所有节点状态一致,但可以保证在”最终“所有节点一致,“最终”是一个现实中存在,但理论上无法证明的时间点。因为Gossip不要求节点知道所有其他节点,因此又具有去中心化的特点,节点之间完全对等,不需要任何的中心节点。实际上Gossip可以用于众多能接受“最终一致性”的领域:失败检测、路由同步、Pub/Sub、动态负载均衡。Gossip假定同步会按照一个固定进度表执行,每个节点定期随机或是按照某种规则选择另外一个节点交换数据,消除差异。有三种类型的反熵协议:推(push)、拉(pull)和推/拉(push/pull)混合(如图 2-12 所 示)。
■ push:A节点将数据(key,value,version)及对应的版本号推送给B节点,B节点更新A节点中比自己新的数据。
■ pull:A节点仅将数据(key,version)推送给B节点,B节点将本地比A节点新的数据(Key,value,version)推送给节点A节点,A节点更新本地。
■ push/pull:与pull类似,只是多了一步,A节点再将本地比B节点新的数据推送给B节点,B节点更新本地。
如果把两个节点数据同步一次定义为一个周期,则在一个周期内,push需通信1次,pull需2次,push/pull则需3次,从效果上来讲,push/pull最好,理论上一个周期内可以使两个节点完全一致,push/pull的收敛速度是最快的。假设每个节点通信周期都能选择(感染)一个新节点,则Gossip算法退化为一个二分查找过程,每个周期构成一个平衡二叉树,收敛速度为O (N2),对应的时间开销则为O (log N)。这也是Gossip理论上最优的收敛速度。但
在实际情况中最优收敛速度是很难达到的,假设某个节点在第i个周期被感染的概率为pi, 第i +1个周期被感染的概率为p i+1,则pull的方式:
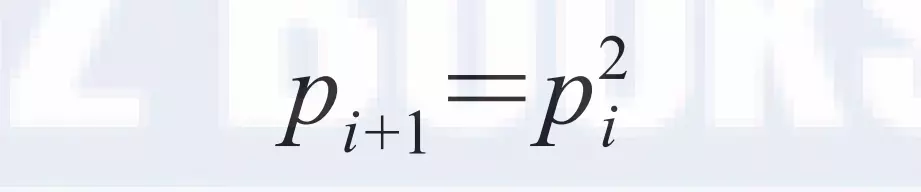
而 push 为:
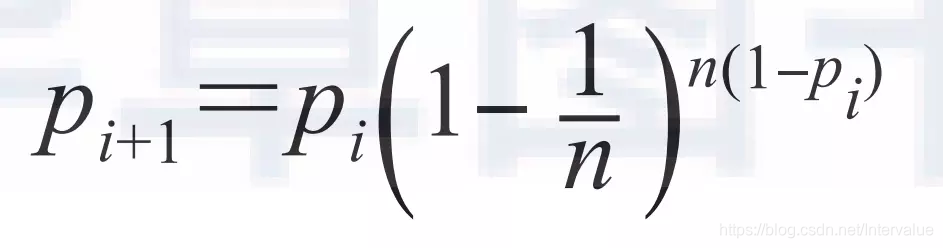
显然pull的收敛速度大于push,而每个节点在每个周期被感染的概率都是固定的p(0<p<1),因此Gossip算法是基于p的平方收敛,也称为概率收敛,这在众多的一致性算法中是非常独特的。
Gossip算法还需要考虑协调机制,即是讨论在每次2个节点通信时,如何交换数据能达到最快的一致性,也即消除两个节点的不一致性。上面所讲的push、pull等是通信方式,协调是在通信方式下的数据交换机制。协调所面临的最大问题是,因为受限于网络负载,不可能每次都把一个节点上的数据发送给另外一个节点,也即每个Gossip的消息大小都有上限。在有限的空间上有效率地交换所有的消息是协调要解决的主要问题。
总结来看,Gossip是一种去中心化、容错而又最终一致性的绝妙算法,其收敛性不但得到证明还具有指数级的收敛速度。使用Gossip的系统可以很容易地把Server扩展到更多的节点,满足弹性扩展轻而易举。唯一的缺点是收敛是最终一致性,不适用那些强一致性的场景。