参考博客
https://www.cnblogs.com/xiao987334176/p/9025072.html#autoid-1-1-0
进程同步(multiprocess.Lock、Semaphore、Event)
锁 —— multiprocess.Lock
通过刚刚的学习,我们千方百计实现了程序的异步,让多个任务可以同时在几个进程中并发处理,他们之间的运行没有顺序,一旦开启也不受我们控制。尽管并发编程让我们能更加充分的利用IO资源,但是也给我们带来了新的问题。
当多个进程使用同一份数据资源的时候,就会引发数据安全或顺序混乱问题。
多进程抢占输出资源
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import
os
import
time
import
random
from
multiprocessing
import
Process
def
work(n):
print
(
'%s: %s is running'
%
(n,os.getpid()))
time.sleep(random.random())
print
(
'%s:%s is done'
%
(n,os.getpid()))
if
__name__
=
=
'__main__'
:
for
i
in
range
(
3
):
p
=
Process(target
=
work,args
=
(i,))
p.start()
|
执行输出:
1: 16548 is running
0: 1448 is running
2: 1096 is running
2:1096 is done
0:1448 is done
1:16548 is done
看输出结果,都是乱的。
如果想有序的执行,先run,再done,怎么办?
需要用到锁
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import
os
import
time
import
random
from
multiprocessing
import
Lock
from
multiprocessing
import
Process
def
work(n,lock):
lock.acquire()
#取得锁
print
(
'%s: %s is running'
%
(n,os.getpid()))
time.sleep(random.random())
print
(
'%s:%s is done'
%
(n,os.getpid()))
lock.release()
#释放锁
if
__name__
=
=
'__main__'
:
lock
=
Lock()
#创建锁
for
i
in
range
(
5
):
p
=
Process(target
=
work,args
=
(i,lock))
p.start()
|
执行输出:
0: 17468 is running
0:17468 is done
2: 16688 is running
2:16688 is done
1: 15984 is running
1:15984 is done
3: 15828 is running
3:15828 is done
4: 18156 is running
4:18156 is done
从结果上来看,结果就比较整齐了。先run,再done。结果是无序的


#创建锁 mutex = threading.Lock() #锁定 mutex.acquire([timeout])#timeout是超时时间 #释放 mutex.release() 其中,锁定方法acquire可以有一个超时时间的可选参数timeout。如果设定了timeout,则在超时后通过返回值可以判断是否得到了锁,从而可以进行一些其他的处理。
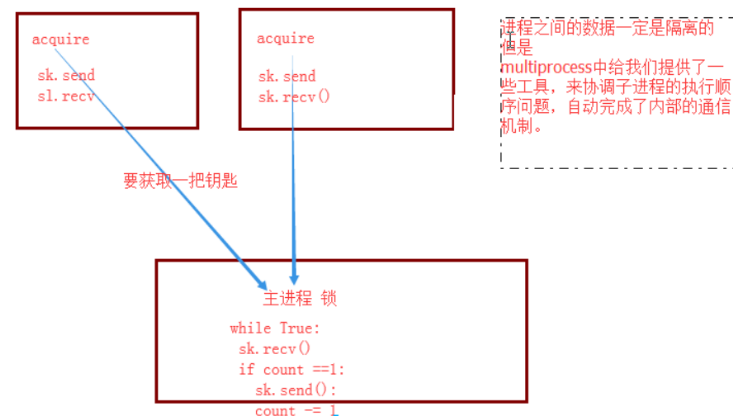
锁的理论
acquire 表示拿锁
最先拿到钥匙的,它会做几件事情:
1.用钥匙开门
2.把钥匙带进门里
3.把门反锁
看下图

理论上来讲,进程一般是异步的
但是加了锁之后,就变成同步了
那么谁先拿到钥匙呢?满足以下2个条件:
1.操作系统先响应的进程
2.当时没有时间片轮询,刚好就是它
lock.acquire()和lock.release()之间的代码,表示被锁住了。
看join效果
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import
os
import
time
import
random
from
multiprocessing
import
Process
def
work(n):
print
(
'%s: %s is running'
%
(n,os.getpid()))
time.sleep(random.random())
print
(
'%s:%s is done'
%
(n,os.getpid()))
if
__name__
=
=
'__main__'
:
for
i
in
range
(
5
):
p
=
Process(target
=
work,args
=
(i,))
p.start()
p.join()
|
执行输出:
0: 17348 is running
0:17348 is done
1: 18164 is running
1:18164 is done
2: 18160 is running
2:18160 is done
3: 17652 is running
3:17652 is done
4: 8340 is running
4:8340 is done
如果锁加在进程的开始和结束,参考work函数,它是同步的
join也是同步的,但是,他们之间的区别在于
锁执行时是无序的,join是有序的
由并发变成了串行,牺牲了运行效率,但避免了竞争。
上面这种情况虽然使用加锁的形式实现了顺序的执行,但是程序又重新变成串行了,这样确实会浪费了时间,却保证了数据的安全。
总结:
同步控制:
只要用到了锁 锁之间的代码就会变成同步的
锁 :控制一段代码 同一时间 只能被一个进程执行
抢票的例子:
比如12306,大家都经历过
模拟数据库,创建一个文件ticket,内容如下:
|
1
|
{
"count"
:
1
}
|
注意一定要用双引号,不然json无法识别
主程序代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
|
import
json
from
multiprocessing
import
Process
def
check_ticket(i):
with
open
(
'ticket'
) as f:
ticket_count
=
json.load(f)
print
(
'person%s'
%
i,ticket_count[
'count'
])
if
__name__
=
=
'__main__'
:
for
i
in
range
(
5
):
Process(target
=
check_ticket,args
=
(i,)).start()
|
执行输出:
person1 1
person0 1
person3 1
person2 1
person4 1
开始买票,买票的时候,可能有网络延时
收到请求之后,从数据库中读取数据
当你发票还有余票时,把票减少这件事情记录下来
中间会经历网络延时
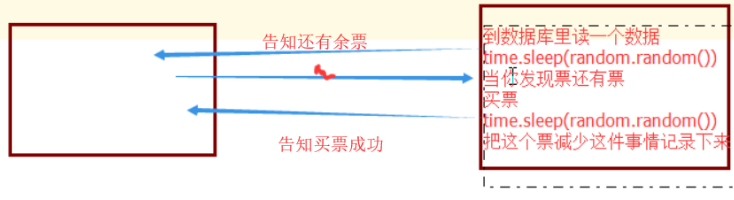
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import
json
import
time
import
random
from
multiprocessing
import
Process
def
buy_ticket(i):
# 购票
with
open
(
'ticket'
) as f:
# 读取文件
tick_count
=
json.load(f)
# 反序列化
time.sleep(random.random())
# 读取延时
if
tick_count[
'count'
] >
0
:
# 当余票小于0时
print
(
'person%s购票成功'
%
i)
tick_count[
'count'
]
-
=
1
# 票数减1
else
:
print
(
'余票不足,person%s购票失败'
%
i)
time.sleep(random.random())
# 写入延时
with
open
(
'ticket'
,
'w'
) as f:
json.dump(tick_count,f)
# 写入文件
if
__name__
=
=
'__main__'
:
for
i
in
range
(
5
):
Process(target
=
buy_ticket,args
=
(i,)).start()
|
模拟这2次延时
是因为服务器和数据库不在一台机器上面,它们之间交互数据,必然有延时
上面的代码只模拟了读取延时和写入延时,没有模拟请求延时

执行输出:
person3购票成功
person0购票成功
person4购票成功
person1购票成功
person2购票成功
从输出结果上来看,库存只有1张票,但是5个人都购票成功了。这显然是不合理的!
这就造成了数据不安全
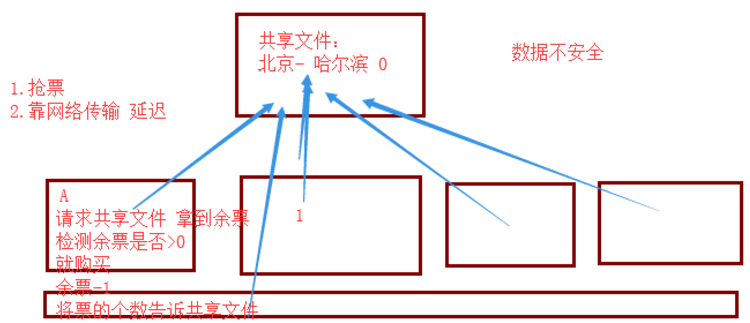
怎么解决呢?加锁
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import
json
import
time
import
random
from
multiprocessing
import
Process,Lock
def
buy_ticket(i,lock):
# 购票
lock.acquire()
#取得锁
with
open
(
'ticket'
) as f:
# 读取文件
tick_count
=
json.load(f)
# 反序列化
time.sleep(random.random())
# 读取延时
if
tick_count[
'count'
] >
0
:
# 当余票小于0时
print
(
'person%s购票成功'
%
i)
tick_count[
'count'
]
-
=
1
# 票数减1
else
:
print
(
'余票不足,person%s购票失败'
%
i)
time.sleep(random.random())
# 写入延时
with
open
(
'ticket'
,
'w'
) as f:
json.dump(tick_count,f)
# 写入文件
lock.release()
#释放锁
if
__name__
=
=
'__main__'
:
lock
=
Lock()
#创建锁
for
i
in
range
(
5
):
# 模拟5个用户抢票
Process(target
=
buy_ticket,args
=
(i,lock)).start()
|
将文件ticket的count数字改为1
|
1
|
{
"count"
:
1
}
|
执行程序输出:
person0购票成功
余票不足,person1购票失败
余票不足,person2购票失败
余票不足,person3购票失败
从结果上来看,是正确的。保证了数据的安全性。
查数据,不涉及数据安全,因为没有修改。
总结:

#加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。 虽然可以用文件共享数据实现进程间通信,但问题是: 1.效率低(共享数据基于文件,而文件是硬盘上的数据) 2.需要自己加锁处理 #因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。 队列和管道都是将数据存放于内存中 队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
信号量 —— multiprocess.Semaphore(了解)
互斥锁同时只允许一个线程更改数据,而信号量Semaphore是同时允许一定数量的线程更改数据 。
假设商场里有4个迷你唱吧,所以同时可以进去4个人,如果来了第五个人就要在外面等待,等到有人出来才能再进去玩。
实现:
信号量同步基于内部计数器,每调用一次acquire(),计数器减1;每调用一次release(),计数器加1.当计数器为0时,acquire()调用被阻塞。这是迪科斯彻(Dijkstra)信号量概念P()和V()的Python实现。信号量同步机制适用于访问像服务器这样的有限资源。
信号量与进程池的概念很像,但是要区分开,信号量涉及到加锁的概念
上面讲的锁一个,现在锁变成一串了,数量由你来控制
下面有一个小KTV,只能容纳4个人,第5个人,就没有钥匙了
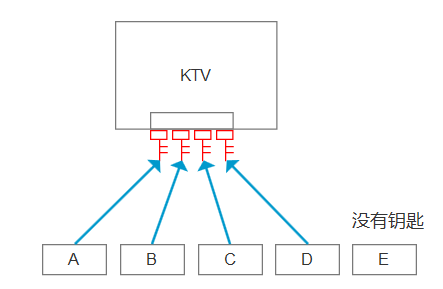
先不用信号量
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#KTV 4个人
import
time
import
random
from
multiprocessing
import
Process,Semaphore
def
ktv(i):
print
(
'person %s 进来唱歌了'
%
i)
time.sleep(random.randint(
1
,
5
))
print
(
'person %s 从ktv出去了'
%
i)
if
__name__
=
=
'__main__'
:
for
i
in
range
(
6
):
# 模拟6个人
Process(target
=
ktv,args
=
(i,)).start()
|
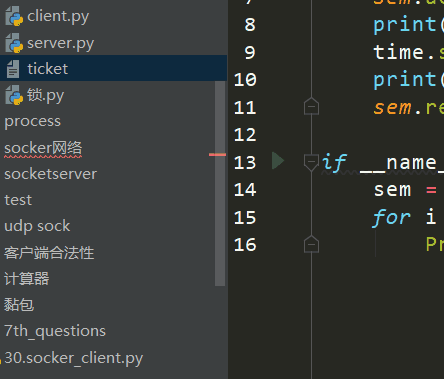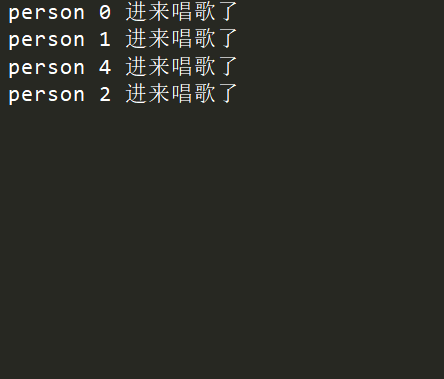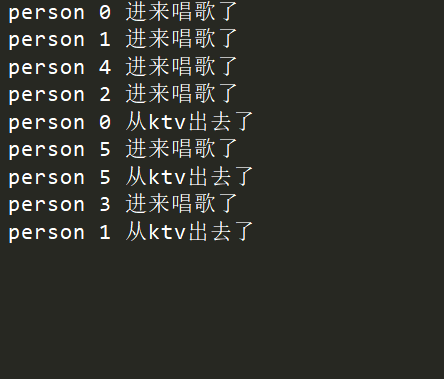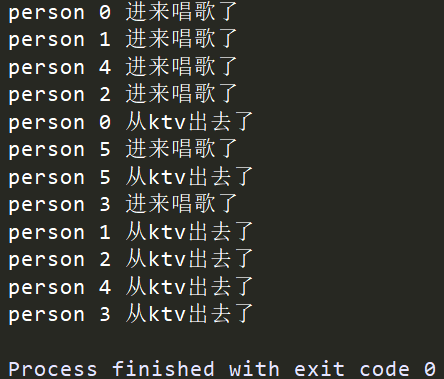
执行输出:
person 0 进来唱歌了
person 1 进来唱歌了
person 2 进来唱歌了
person 3 进来唱歌了
person 4 进来唱歌了
person 5 进来唱歌了
person 3 从ktv出去了
person 4 从ktv出去了
person 2 从ktv出去了
person 1 从ktv出去了
person 0 从ktv出去了
person 5 从ktv出去了
结果是有问题的,6个人,都可以进去
使用信号量来实现
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#KTV 4个人
import
time
import
random
from
multiprocessing
import
Process,Semaphore
def
ktv(i,sem):
sem.acquire()
#取得锁
print
(
'person %s 进来唱歌了'
%
i)
time.sleep(random.randint(
1
,
5
))
print
(
'person %s 从ktv出去了'
%
i)
sem.release()
#释放锁
if
__name__
=
=
'__main__'
:
sem
=
Semaphore(
4
)
#初始化信号量,数量为4
for
i
in
range
(
6
):
# 模拟6个人
Process(target
=
ktv,args
=
(i,sem)).start()
|
执行输出:
在同一时间,最多有4个人进去
acquire()是一个阻塞行为
信号量和锁有点类似
那么它们之间的区别在于:
信号量,相当于计数器
它是锁+计数器
调用acquire() 计数器-1
当计数器到 0 时,再调用 acquire() 就会阻塞,直到其他线程来调用release()
调用release() 计数器+1
事件 —— multiprocess.Event(了解)
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
clear:将“Flag”设置为False
set:将“Flag”设置为True
著名的计算机模型:红绿灯
车 比方是一个进程,wait() 等红灯
根据状态变化,wait遇到true信号,就非阻塞
遇到False,就阻塞
交通灯 也是有一个进程 红灯->False 绿灯->True
这里没有黄灯
事件有几个方法:
wait的方法 根据一个状态来决定自己是否要阻塞
状态相关的方法
set 将状态改为True
clear 将状态改为False
is_set 判断当前的状态是否为True
先来看几行代码
|
1
2
3
4
|
from
multiprocessing
import
Event
e
=
Event()
#创建一个事件的对象
print
(e.is_set())
# 在事件的创世之初,状态为False
|
执行输出: False
在看一个列子
|
1
2
3
4
5
6
|
from
multiprocessing
import
Event
e
=
Event()
#创建一个事件的对象
print
(e.is_set())
# 在事件的创世之初,状态为False
e.wait()
print
(
'1'
)
|
执行输出: False,然后程序一致卡着
为啥呢?因为状态值为 False,那么当程序执行 event.wait 方法时就会阻塞
再来
|
1
2
3
4
5
6
7
8
|
from
multiprocessing
import
Event
e
=
Event()
#创建一个事件的对象
print
(e.is_set())
# 在事件的创世之初,状态为False
e.
set
()
# 将状态设置为True
e.wait()
print
(e.is_set())
# 查看状态
print
(
'1'
)
|
执行输出:
False
True
1
很快就输出了,说明没有阻塞
wait是否阻塞,取决于当前的状态
模拟红绿灯
|
1
2
3
4
5
6
7
8
9
10
11
|
import
time
def
traffic_light():
while
True
:
print
(
'红灯亮'
)
time.sleep(
2
)
print
(
'绿灯亮'
)
time.sleep(
2
)
break
traffic_light()
|
执行输出:
红灯亮
绿灯亮
为了好看一点,加点颜色
|
1
2
3
4
5
6
7
8
9
10
11
|
import
time
def
traffic_light():
while
True
:
print
(
'\033[1;31m红灯亮\033[0m'
)
time.sleep(
2
)
print
(
'\033[1;32m绿灯亮\033[0m'
)
time.sleep(
2
)
break
traffic_light()
|
执行输出:

输出挺专业的哈
下面来创建车
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import
time
from
multiprocessing
import
Process,Event
def
traffic_light():
while
True
:
print
(
'\033[1;31m红灯亮\033[0m'
)
time.sleep(
2
)
print
(
'\033[1;32m绿灯亮\033[0m'
)
time.sleep(
2
)
break
def
car(i):
print
(
'car%s通过路口'
%
i)
if
__name__
=
=
'__main__'
:
for
i
in
range
(
1
,
6
):
# 创建5辆车
Process(target
=
car,args
=
(i,)).start()
|
执行输出:
car1通过路口
car2通过路口
car3通过路口
car5通过路口
car4通过路口
现在还没有红绿灯,加一个红绿灯进程
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import
time
from
multiprocessing
import
Process,Event
def
traffic_light():
while
True
:
print
(
'\033[1;31m红灯亮\033[0m'
)
time.sleep(
2
)
print
(
'\033[1;32m绿灯亮\033[0m'
)
time.sleep(
2
)
break
def
car(i):
print
(
'car%s通过路口'
%
i)
if
__name__
=
=
'__main__'
:
Process(target
=
traffic_light).start()
for
i
in
range
(
1
,
6
):
Process(target
=
car,args
=
(i,)).start()
|
执行输出:

发现5辆车都闯红灯了...
加一个事件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import
time
import
random
from
multiprocessing
import
Process,Event
def
traffic_light(e,count):
# 交通灯
while
True
:
while
True
:
# 事件在创建的时候,e的状态是False,相当于程序中的红灯
print
(
'\033[1;31m红灯亮\033[0m'
)
time.sleep(
2
)
# 红灯亮2秒
# 这里e.is_set()是False,所以not e.is_set()就是True
if
not
e.is_set():e.
set
()
# 判断为True时,变绿灯
print
(
'\033[1;32m绿灯亮\033[0m'
)
time.sleep(
2
)
# 绿灯亮2秒
# 这里e.is_set()是True
if
e.is_set():e.clear()
# 判断为True时,将状态设置为False
count
+
=
1
# 自增1
if
count
=
=
5
:
# 判断为5时,跳出内层循环
break
break
#跳出内层循环
def
car(i,e):
# 汽车,感知状态的变化
if
not
e.is_set():
# 当前这个事件状态是False
print
(
'car%s正在等待'
%
i)
# 这辆车正在等待通过路口
e.wait()
# 阻塞,直到有一个e.set行为。正在等红灯
print
(
'car%s通过路口'
%
i)
# 等待状态为True,才能通过
if
__name__
=
=
'__main__'
:
e
=
Event()
# 创建事件,默认状态为False
Process(target
=
traffic_light,args
=
(e,
0
)).start()
# 启动红灯进程
for
i
in
range
(
1
,
6
):
# 模拟5个人
time.sleep(random.randrange(
0
,
5
,
2
))
# 大于等于0且小于5之间的奇数
Process(target
=
car,args
=
(i,e)).start()
# 启动交通灯进程
|
执行输出:

从结果上来看,挺完美的。
每辆车独立占用一个进程,交通灯也是一个进程,之前学的进程是隔离的,那么car进程为什么能感知到?
是因为进程之间用了socket网络通信
内部有一套通讯机制
注意:e.is_set() 状态不是固定的,每隔2秒,会变化一次。
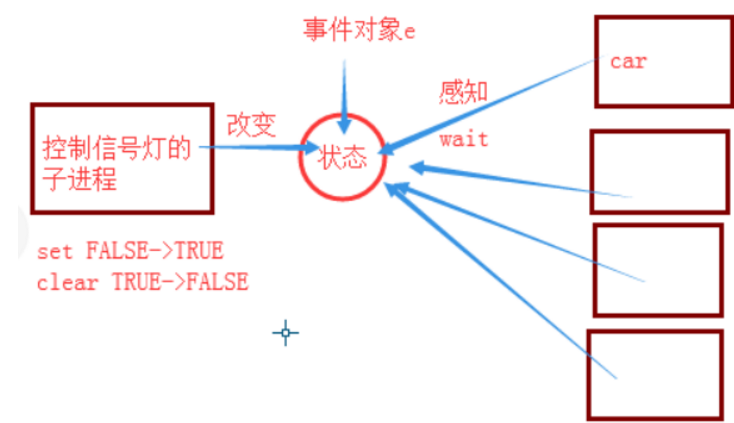
控制信号灯的子进程、事件对象e、car子进程,都依赖于状态
wait只判断True和False
也就是红灯停,绿灯行
等待2秒之后,就切换一个状态
相当于执行了下面的代码:
|
1
2
3
4
5
6
7
|
flag
=
False
while
True
:
if
flag
is
True
:
flag
=
False
else
:
flag
=
True
time.sleep(
2
)
|
进程间通信——队列和管道(multiprocess.Queue、multiprocess.Pipe)
进程间通信
IPC(Inter-Process Communication)
IPC说的就是进程之间的通信,它只是缩写而已
队列
概念介绍
之前学的queue和现在要提到的queue之间的区别
import queue
它能维护一个先进先出的秩序,它不能进行IPC
from multiprocessing import Queue,Process
能维护一个先进先出的秩序,也能进行IPC
创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
遵循先进先出原则
Queue([maxsize])
创建共享的进程队列。
参数 :maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。
底层队列使用管道和锁定实现。
Queue([maxsize])
创建共享的进程队列。maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。底层队列使用管道和锁定实现。另外,还需要运行支持线程以便队列中的数据传输到底层管道中。
Queue的实例q具有以下方法:
q.get( [ block [ ,timeout ] ] )
返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True. 如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。如果在制定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
q.get_nowait( )
同q.get(False)方法。
q.put(item [, block [,timeout ] ] )
将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
q.qsize()
返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
q.empty()
如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
q.full()
如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的(参考q.empty()方法)。。
q.close()
关闭队列,防止队列中加入更多数据。调用此方法时,后台线程将继续写入那些已入队列但尚未写入的数据,但将在此方法完成时马上关闭。如果q被垃圾收集,将自动调用此方法。关闭队列不会在队列使用者中生成任何类型的数据结束信号或异常。例如,如果某个使用者正被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
q.cancel_join_thread()
不会再进程退出时自动连接后台线程。这可以防止join_thread()方法阻塞。
q.join_thread()
连接队列的后台线程。此方法用于在调用q.close()方法后,等待所有队列项被消耗。默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread()方法可以禁止这种行为。
简单用法:
|
1
2
3
4
5
6
|
from
multiprocessing
import
Process,Queue
q
=
Queue()
#创建共享的进程队列
q.put(
1
)
# 将一个值放入队列
q.put(
2
)
q.put(
'aaa'
)
print
(q.get())
# 返回q中的一个项目
|
执行输出:1
因为1先进去,所以它先出来。
|
1
2
3
4
5
6
7
8
9
|
from
multiprocessing
import
Process,Queue
def
wahaha(q):
print
(q.get())
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
Process(target
=
wahaha,args
=
(q,)).start()
q.put(
1
)
|
执行输出:1
因为主程序先执行
双向通信
既能取值,也能增加值
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import
time
from
multiprocessing
import
Process,Queue
def
wahaha(q):
print
(q.get())
# 取值
q.put(
'aaa'
)
# 增加一个aaa
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
Process(target
=
wahaha,args
=
(q,)).start()
q.put(
1
)
time.sleep(
0.5
)
# 等待0.5秒,让子程序执行完
print
(q.get())
# 取值
|
执行输出:
1
aaa
''' multiprocessing模块支持进程间通信的两种主要形式:管道和队列 都是基于消息传递实现的,但是队列接口 ''' from multiprocessing import Queue q=Queue(3) #put ,get ,put_nowait,get_nowait,full,empty q.put(3) q.put(3) q.put(3) # q.put(3) # 如果队列已经满了,程序就会停在这里,等待数据被别人取走,再将数据放入队列。 # 如果队列中的数据一直不被取走,程序就会永远停在这里。 try: q.put_nowait(3) # 可以使用put_nowait,如果队列满了不会阻塞,但是会因为队列满了而报错。 except: # 因此我们可以用一个try语句来处理这个错误。这样程序不会一直阻塞下去,但是会丢掉这个消息。 print('队列已经满了') # 因此,我们再放入数据之前,可以先看一下队列的状态,如果已经满了,就不继续put了。 print(q.full()) #满了 print(q.get()) print(q.get()) print(q.get()) # print(q.get()) # 同put方法一样,如果队列已经空了,那么继续取就会出现阻塞。 try: q.get_nowait(3) # 可以使用get_nowait,如果队列满了不会阻塞,但是会因为没取到值而报错。 except: # 因此我们可以用一个try语句来处理这个错误。这样程序不会一直阻塞下去。 print('队列已经空了') print(q.empty()) #空了
上面这个例子还没有加入进程通信,只是先来看看队列为我们提供的方法,以及这些方法的使用和现象。
import time from multiprocessing import Process, Queue def f(q): q.put([time.asctime(), 'from Eva', 'hello']) #调用主函数中p进程传递过来的进程参数 put函数为向队列中添加一条数据。 if __name__ == '__main__': q = Queue() #创建一个Queue对象 p = Process(target=f, args=(q,)) #创建一个进程 p.start() print(q.get()) p.join()
上面是一个queue的简单应用,使用队列q对象调用get函数来取得队列中最先进入的数据。 接下来看一个稍微复杂一些的例子:
import os import time import multiprocessing # 向queue中输入数据的函数 def inputQ(queue): info = str(os.getpid()) + '(put):' + str(time.asctime()) queue.put(info) # 向queue中输出数据的函数 def outputQ(queue): info = queue.get() print ('%s%s\033[32m%s\033[0m'%(str(os.getpid()), '(get):',info)) # Main if __name__ == '__main__': multiprocessing.freeze_support() record1 = [] # store input processes record2 = [] # store output processes queue = multiprocessing.Queue(3) # 输入进程 for i in range(10): process = multiprocessing.Process(target=inputQ,args=(queue,)) process.start() record1.append(process) # 输出进程 for i in range(10): process = multiprocessing.Process(target=outputQ,args=(queue,)) process.start() record2.append(process) for p in record1: p.join() for p in record2: p.join()
生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
生产者消费者模型
消费者 消费数据 吃包子
生产者 产生数据的人 做包子
假如生产了10个包子,但是来了15个人,供不应求了。
这就产生了供销矛盾,那怎么解决呢?
增加做包子的人
或者采用同步模式 :做一个包子 卖一包子
再举一个例子:
生产数据 在淘宝买东西 --- 产生消费者行为数据
消费数据 阿里巴巴 --- 即时性要求非常高 必须要快速把用户生产的数据消费完
看下图
笼屉,只能放100个包子
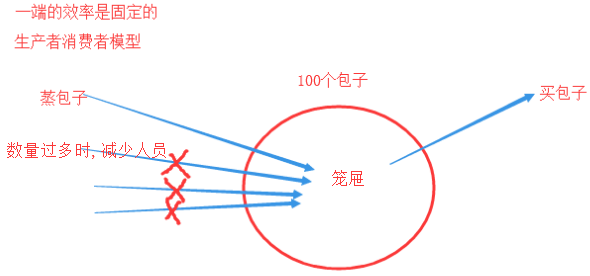
如果蒸包子的数量过多,没人买了,那么就需要减少蒸包子的人
如果蒸包子的根据买包子的人,来生产包子,就比较完美了
queue队列就是笼屉
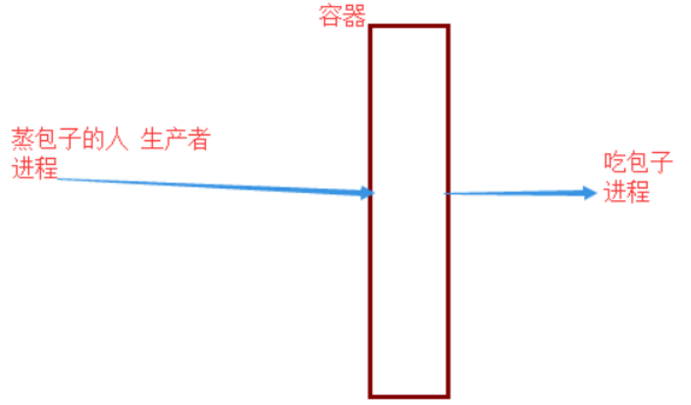
基于队列实现生产者消费者模型
举例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import
time
import
random
from
multiprocessing
import
Process,Queue
def
producer(q):
#生产者
for
i
in
range
(
5
):
# 生产5个包子
time.sleep(random.random())
# 模拟生产包子时间
q.put(
'包子%s'
%
i)
def
consumer(q):
# 消费者
for
i
in
range
(
5
):
# 5个消费者
print
(q.get())
# 买一个包子
time.sleep(random.random())
# 模拟吃包子时间
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
p1
=
Process(target
=
producer,args
=
(q,))
p2
=
Process(target
=
consumer, args
=
(q,))
p1.start()
# 启动进程
p2.start()
|
执行输出:
包子0
包子1
包子2
包子3
包子4
增加颜色,显示更明显
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import
time
import
random
from
multiprocessing
import
Process,Queue
def
producer(q):
#生产者
for
i
in
range
(
1
,
6
):
# 生产5个包子
time.sleep(random.random())
# 模拟生产包子时间
print
(
'\033[1;31m生产了包子%s\033[0m'
%
i)
def
consumer(q):
# 消费者
for
i
in
range
(
1
,
6
):
# 5个消费者
print
(
'\033[1;32m消费了包子%s\033[0m'
%
i)
time.sleep(random.uniform(
1
,
2
))
# 模拟吃包子时间
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
p1
=
Process(target
=
producer,args
=
(q,))
p2
=
Process(target
=
consumer, args
=
(q,))
p1.start()
# 启动进程
p2.start()
|
执行输出:

发现供需不平衡
需要改变供需平衡
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import
time
import
random
from
multiprocessing
import
Process,Queue
def
producer(q):
#生产者
for
i
in
range
(
1
,
11
):
# 生产5个包子
time.sleep(random.random())
# 模拟生产包子时间
q.put(
'包子%s'
%
i)
# 生产包子,将包子放入队列,比如包子1
print
(
'\033[1;31m生产了包子%s\033[0m'
%
i)
def
consumer(q):
# 消费者
for
i
in
range
(
1
,
6
):
# 5个消费者
food
=
q.get()
# 买一个包子
print
(
'\033[1;32m消费了包子%s\033[0m'
%
food)
time.sleep(random.uniform(
1
,
2
))
# 模拟吃包子时间
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
p1
=
Process(target
=
producer,args
=
(q,))
p2
=
Process(target
=
consumer, args
=
(q,))
p3
=
Process(target
=
consumer, args
=
[q])
# 增加一个消费者进程
p1.start()
# 启动进程
p2.start()
p3.start()
|
执行输出:
上面是通过消费者和包子数量对等,解决供需平衡问题的。
其他例子:
基于队列实现生产者消费者模型
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): for i in range(10): time.sleep(random.randint(1,3)) res='包子%s' %i q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) #开始 p1.start() c1.start() print('主')
此时的问题是主进程永远不会结束,原因是:生产者p在生产完后就结束了,但是消费者c在取空了q之后,则一直处于死循环中且卡在q.get()这一步。
解决方式无非是让生产者在生产完毕后,往队列中再发一个结束信号,这样消费者在接收到结束信号后就可以break出死循环。
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() if res is None:break #收到结束信号则结束 time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): for i in range(10): time.sleep(random.randint(1,3)) res='包子%s' %i q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) q.put(None) #发送结束信号 if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) #开始 p1.start() c1.start() print('主')
注意:结束信号None,不一定要由生产者发,主进程里同样可以发,但主进程需要等生产者结束后才应该发送该信号
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() if res is None:break #收到结束信号则结束 time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): for i in range(2): time.sleep(random.randint(1,3)) res='包子%s' %i q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) #开始 p1.start() c1.start() p1.join() q.put(None) #发送结束信号 print('主')
但上述解决方式,在有多个生产者和多个消费者时,我们则需要用一个很low的方式去解决
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() if res is None:break #收到结束信号则结束 time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(name,q): for i in range(2): time.sleep(random.randint(1,3)) res='%s%s' %(name,i) q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=('包子',q)) p2=Process(target=producer,args=('骨头',q)) p3=Process(target=producer,args=('泔水',q)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) c2=Process(target=consumer,args=(q,)) #开始 p1.start() p2.start() p3.start() c1.start() p1.join() #必须保证生产者全部生产完毕,才应该发送结束信号 p2.join() p3.join() q.put(None) #有几个消费者就应该发送几次结束信号None q.put(None) #发送结束信号 print('主')
参考博客
https://www.cnblogs.com/xiao987334176/p/9025072.html#autoid-1-1-0
进程同步(multiprocess.Lock、Semaphore、Event)
锁 —— multiprocess.Lock
通过刚刚的学习,我们千方百计实现了程序的异步,让多个任务可以同时在几个进程中并发处理,他们之间的运行没有顺序,一旦开启也不受我们控制。尽管并发编程让我们能更加充分的利用IO资源,但是也给我们带来了新的问题。
当多个进程使用同一份数据资源的时候,就会引发数据安全或顺序混乱问题。
多进程抢占输出资源
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import
os
import
time
import
random
from
multiprocessing
import
Process
def
work(n):
print
(
'%s: %s is running'
%
(n,os.getpid()))
time.sleep(random.random())
print
(
'%s:%s is done'
%
(n,os.getpid()))
if
__name__
=
=
'__main__'
:
for
i
in
range
(
3
):
p
=
Process(target
=
work,args
=
(i,))
p.start()
|
执行输出:
1: 16548 is running
0: 1448 is running
2: 1096 is running
2:1096 is done
0:1448 is done
1:16548 is done
看输出结果,都是乱的。
如果想有序的执行,先run,再done,怎么办?
需要用到锁
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import
os
import
time
import
random
from
multiprocessing
import
Lock
from
multiprocessing
import
Process
def
work(n,lock):
lock.acquire()
#取得锁
print
(
'%s: %s is running'
%
(n,os.getpid()))
time.sleep(random.random())
print
(
'%s:%s is done'
%
(n,os.getpid()))
lock.release()
#释放锁
if
__name__
=
=
'__main__'
:
lock
=
Lock()
#创建锁
for
i
in
range
(
5
):
p
=
Process(target
=
work,args
=
(i,lock))
p.start()
|
执行输出:
0: 17468 is running
0:17468 is done
2: 16688 is running
2:16688 is done
1: 15984 is running
1:15984 is done
3: 15828 is running
3:15828 is done
4: 18156 is running
4:18156 is done
从结果上来看,结果就比较整齐了。先run,再done。结果是无序的
#创建锁 mutex = threading.Lock() #锁定 mutex.acquire([timeout])#timeout是超时时间 #释放 mutex.release() 其中,锁定方法acquire可以有一个超时时间的可选参数timeout。如果设定了timeout,则在超时后通过返回值可以判断是否得到了锁,从而可以进行一些其他的处理。
锁的理论
acquire 表示拿锁
最先拿到钥匙的,它会做几件事情:
1.用钥匙开门
2.把钥匙带进门里
3.把门反锁
看下图
理论上来讲,进程一般是异步的
但是加了锁之后,就变成同步了
那么谁先拿到钥匙呢?满足以下2个条件:
1.操作系统先响应的进程
2.当时没有时间片轮询,刚好就是它
lock.acquire()和lock.release()之间的代码,表示被锁住了。
看join效果
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import
os
import
time
import
random
from
multiprocessing
import
Process
def
work(n):
print
(
'%s: %s is running'
%
(n,os.getpid()))
time.sleep(random.random())
print
(
'%s:%s is done'
%
(n,os.getpid()))
if
__name__
=
=
'__main__'
:
for
i
in
range
(
5
):
p
=
Process(target
=
work,args
=
(i,))
p.start()
p.join()
|
执行输出:
0: 17348 is running
0:17348 is done
1: 18164 is running
1:18164 is done
2: 18160 is running
2:18160 is done
3: 17652 is running
3:17652 is done
4: 8340 is running
4:8340 is done
如果锁加在进程的开始和结束,参考work函数,它是同步的
join也是同步的,但是,他们之间的区别在于
锁执行时是无序的,join是有序的
由并发变成了串行,牺牲了运行效率,但避免了竞争。
上面这种情况虽然使用加锁的形式实现了顺序的执行,但是程序又重新变成串行了,这样确实会浪费了时间,却保证了数据的安全。
总结:
同步控制:
只要用到了锁 锁之间的代码就会变成同步的
锁 :控制一段代码 同一时间 只能被一个进程执行
抢票的例子:
比如12306,大家都经历过
模拟数据库,创建一个文件ticket,内容如下:
|
1
|
{
"count"
:
1
}
|
注意一定要用双引号,不然json无法识别
主程序代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
|
import
json
from
multiprocessing
import
Process
def
check_ticket(i):
with
open
(
'ticket'
) as f:
ticket_count
=
json.load(f)
print
(
'person%s'
%
i,ticket_count[
'count'
])
if
__name__
=
=
'__main__'
:
for
i
in
range
(
5
):
Process(target
=
check_ticket,args
=
(i,)).start()
|
执行输出:
person1 1
person0 1
person3 1
person2 1
person4 1
开始买票,买票的时候,可能有网络延时
收到请求之后,从数据库中读取数据
当你发票还有余票时,把票减少这件事情记录下来
中间会经历网络延时
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import
json
import
time
import
random
from
multiprocessing
import
Process
def
buy_ticket(i):
# 购票
with
open
(
'ticket'
) as f:
# 读取文件
tick_count
=
json.load(f)
# 反序列化
time.sleep(random.random())
# 读取延时
if
tick_count[
'count'
] >
0
:
# 当余票小于0时
print
(
'person%s购票成功'
%
i)
tick_count[
'count'
]
-
=
1
# 票数减1
else
:
print
(
'余票不足,person%s购票失败'
%
i)
time.sleep(random.random())
# 写入延时
with
open
(
'ticket'
,
'w'
) as f:
json.dump(tick_count,f)
# 写入文件
if
__name__
=
=
'__main__'
:
for
i
in
range
(
5
):
Process(target
=
buy_ticket,args
=
(i,)).start()
|
模拟这2次延时
是因为服务器和数据库不在一台机器上面,它们之间交互数据,必然有延时
上面的代码只模拟了读取延时和写入延时,没有模拟请求延时
执行输出:
person3购票成功
person0购票成功
person4购票成功
person1购票成功
person2购票成功
从输出结果上来看,库存只有1张票,但是5个人都购票成功了。这显然是不合理的!
这就造成了数据不安全
怎么解决呢?加锁
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import
json
import
time
import
random
from
multiprocessing
import
Process,Lock
def
buy_ticket(i,lock):
# 购票
lock.acquire()
#取得锁
with
open
(
'ticket'
) as f:
# 读取文件
tick_count
=
json.load(f)
# 反序列化
time.sleep(random.random())
# 读取延时
if
tick_count[
'count'
] >
0
:
# 当余票小于0时
print
(
'person%s购票成功'
%
i)
tick_count[
'count'
]
-
=
1
# 票数减1
else
:
print
(
'余票不足,person%s购票失败'
%
i)
time.sleep(random.random())
# 写入延时
with
open
(
'ticket'
,
'w'
) as f:
json.dump(tick_count,f)
# 写入文件
lock.release()
#释放锁
if
__name__
=
=
'__main__'
:
lock
=
Lock()
#创建锁
for
i
in
range
(
5
):
# 模拟5个用户抢票
Process(target
=
buy_ticket,args
=
(i,lock)).start()
|
将文件ticket的count数字改为1
|
1
|
{
"count"
:
1
}
|
执行程序输出:
person0购票成功
余票不足,person1购票失败
余票不足,person2购票失败
余票不足,person3购票失败
从结果上来看,是正确的。保证了数据的安全性。
查数据,不涉及数据安全,因为没有修改。
总结:
#加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。 虽然可以用文件共享数据实现进程间通信,但问题是: 1.效率低(共享数据基于文件,而文件是硬盘上的数据) 2.需要自己加锁处理 #因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。 队列和管道都是将数据存放于内存中 队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
信号量 —— multiprocess.Semaphore(了解)
互斥锁同时只允许一个线程更改数据,而信号量Semaphore是同时允许一定数量的线程更改数据 。
假设商场里有4个迷你唱吧,所以同时可以进去4个人,如果来了第五个人就要在外面等待,等到有人出来才能再进去玩。
实现:
信号量同步基于内部计数器,每调用一次acquire(),计数器减1;每调用一次release(),计数器加1.当计数器为0时,acquire()调用被阻塞。这是迪科斯彻(Dijkstra)信号量概念P()和V()的Python实现。信号量同步机制适用于访问像服务器这样的有限资源。
信号量与进程池的概念很像,但是要区分开,信号量涉及到加锁的概念
上面讲的锁一个,现在锁变成一串了,数量由你来控制
下面有一个小KTV,只能容纳4个人,第5个人,就没有钥匙了
先不用信号量
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#KTV 4个人
import
time
import
random
from
multiprocessing
import
Process,Semaphore
def
ktv(i):
print
(
'person %s 进来唱歌了'
%
i)
time.sleep(random.randint(
1
,
5
))
print
(
'person %s 从ktv出去了'
%
i)
if
__name__
=
=
'__main__'
:
for
i
in
range
(
6
):
# 模拟6个人
Process(target
=
ktv,args
=
(i,)).start()
|
执行输出:
person 0 进来唱歌了
person 1 进来唱歌了
person 2 进来唱歌了
person 3 进来唱歌了
person 4 进来唱歌了
person 5 进来唱歌了
person 3 从ktv出去了
person 4 从ktv出去了
person 2 从ktv出去了
person 1 从ktv出去了
person 0 从ktv出去了
person 5 从ktv出去了
结果是有问题的,6个人,都可以进去
使用信号量来实现
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#KTV 4个人
import
time
import
random
from
multiprocessing
import
Process,Semaphore
def
ktv(i,sem):
sem.acquire()
#取得锁
print
(
'person %s 进来唱歌了'
%
i)
time.sleep(random.randint(
1
,
5
))
print
(
'person %s 从ktv出去了'
%
i)
sem.release()
#释放锁
if
__name__
=
=
'__main__'
:
sem
=
Semaphore(
4
)
#初始化信号量,数量为4
for
i
in
range
(
6
):
# 模拟6个人
Process(target
=
ktv,args
=
(i,sem)).start()
|
执行输出:
在同一时间,最多有4个人进去
acquire()是一个阻塞行为
信号量和锁有点类似
那么它们之间的区别在于:
信号量,相当于计数器
它是锁+计数器
调用acquire() 计数器-1
当计数器到 0 时,再调用 acquire() 就会阻塞,直到其他线程来调用release()
调用release() 计数器+1
事件 —— multiprocess.Event(了解)
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
clear:将“Flag”设置为False
set:将“Flag”设置为True
著名的计算机模型:红绿灯
车 比方是一个进程,wait() 等红灯
根据状态变化,wait遇到true信号,就非阻塞
遇到False,就阻塞
交通灯 也是有一个进程 红灯->False 绿灯->True
这里没有黄灯
事件有几个方法:
wait的方法 根据一个状态来决定自己是否要阻塞
状态相关的方法
set 将状态改为True
clear 将状态改为False
is_set 判断当前的状态是否为True
先来看几行代码
|
1
2
3
4
|
from
multiprocessing
import
Event
e
=
Event()
#创建一个事件的对象
print
(e.is_set())
# 在事件的创世之初,状态为False
|
执行输出: False
在看一个列子
|
1
2
3
4
5
6
|
from
multiprocessing
import
Event
e
=
Event()
#创建一个事件的对象
print
(e.is_set())
# 在事件的创世之初,状态为False
e.wait()
print
(
'1'
)
|
执行输出: False,然后程序一致卡着
为啥呢?因为状态值为 False,那么当程序执行 event.wait 方法时就会阻塞
再来
|
1
2
3
4
5
6
7
8
|
from
multiprocessing
import
Event
e
=
Event()
#创建一个事件的对象
print
(e.is_set())
# 在事件的创世之初,状态为False
e.
set
()
# 将状态设置为True
e.wait()
print
(e.is_set())
# 查看状态
print
(
'1'
)
|
执行输出:
False
True
1
很快就输出了,说明没有阻塞
wait是否阻塞,取决于当前的状态
模拟红绿灯
|
1
2
3
4
5
6
7
8
9
10
11
|
import
time
def
traffic_light():
while
True
:
print
(
'红灯亮'
)
time.sleep(
2
)
print
(
'绿灯亮'
)
time.sleep(
2
)
break
traffic_light()
|
执行输出:
红灯亮
绿灯亮
为了好看一点,加点颜色
|
1
2
3
4
5
6
7
8
9
10
11
|
import
time
def
traffic_light():
while
True
:
print
(
'\033[1;31m红灯亮\033[0m'
)
time.sleep(
2
)
print
(
'\033[1;32m绿灯亮\033[0m'
)
time.sleep(
2
)
break
traffic_light()
|
执行输出:
输出挺专业的哈
下面来创建车
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import
time
from
multiprocessing
import
Process,Event
def
traffic_light():
while
True
:
print
(
'\033[1;31m红灯亮\033[0m'
)
time.sleep(
2
)
print
(
'\033[1;32m绿灯亮\033[0m'
)
time.sleep(
2
)
break
def
car(i):
print
(
'car%s通过路口'
%
i)
if
__name__
=
=
'__main__'
:
for
i
in
range
(
1
,
6
):
# 创建5辆车
Process(target
=
car,args
=
(i,)).start()
|
执行输出:
car1通过路口
car2通过路口
car3通过路口
car5通过路口
car4通过路口
现在还没有红绿灯,加一个红绿灯进程
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import
time
from
multiprocessing
import
Process,Event
def
traffic_light():
while
True
:
print
(
'\033[1;31m红灯亮\033[0m'
)
time.sleep(
2
)
print
(
'\033[1;32m绿灯亮\033[0m'
)
time.sleep(
2
)
break
def
car(i):
print
(
'car%s通过路口'
%
i)
if
__name__
=
=
'__main__'
:
Process(target
=
traffic_light).start()
for
i
in
range
(
1
,
6
):
Process(target
=
car,args
=
(i,)).start()
|
执行输出:
发现5辆车都闯红灯了...
加一个事件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import
time
import
random
from
multiprocessing
import
Process,Event
def
traffic_light(e,count):
# 交通灯
while
True
:
while
True
:
# 事件在创建的时候,e的状态是False,相当于程序中的红灯
print
(
'\033[1;31m红灯亮\033[0m'
)
time.sleep(
2
)
# 红灯亮2秒
# 这里e.is_set()是False,所以not e.is_set()就是True
if
not
e.is_set():e.
set
()
# 判断为True时,变绿灯
print
(
'\033[1;32m绿灯亮\033[0m'
)
time.sleep(
2
)
# 绿灯亮2秒
# 这里e.is_set()是True
if
e.is_set():e.clear()
# 判断为True时,将状态设置为False
count
+
=
1
# 自增1
if
count
=
=
5
:
# 判断为5时,跳出内层循环
break
break
#跳出内层循环
def
car(i,e):
# 汽车,感知状态的变化
if
not
e.is_set():
# 当前这个事件状态是False
print
(
'car%s正在等待'
%
i)
# 这辆车正在等待通过路口
e.wait()
# 阻塞,直到有一个e.set行为。正在等红灯
print
(
'car%s通过路口'
%
i)
# 等待状态为True,才能通过
if
__name__
=
=
'__main__'
:
e
=
Event()
# 创建事件,默认状态为False
Process(target
=
traffic_light,args
=
(e,
0
)).start()
# 启动红灯进程
for
i
in
range
(
1
,
6
):
# 模拟5个人
time.sleep(random.randrange(
0
,
5
,
2
))
# 大于等于0且小于5之间的奇数
Process(target
=
car,args
=
(i,e)).start()
# 启动交通灯进程
|
执行输出:
从结果上来看,挺完美的。
每辆车独立占用一个进程,交通灯也是一个进程,之前学的进程是隔离的,那么car进程为什么能感知到?
是因为进程之间用了socket网络通信
内部有一套通讯机制
注意:e.is_set() 状态不是固定的,每隔2秒,会变化一次。
控制信号灯的子进程、事件对象e、car子进程,都依赖于状态
wait只判断True和False
也就是红灯停,绿灯行
等待2秒之后,就切换一个状态
相当于执行了下面的代码:
|
1
2
3
4
5
6
7
|
flag
=
False
while
True
:
if
flag
is
True
:
flag
=
False
else
:
flag
=
True
time.sleep(
2
)
|
进程间通信——队列和管道(multiprocess.Queue、multiprocess.Pipe)
进程间通信
IPC(Inter-Process Communication)
IPC说的就是进程之间的通信,它只是缩写而已
队列
概念介绍
之前学的queue和现在要提到的queue之间的区别
import queue
它能维护一个先进先出的秩序,它不能进行IPC
from multiprocessing import Queue,Process
能维护一个先进先出的秩序,也能进行IPC
创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
遵循先进先出原则
Queue([maxsize])
创建共享的进程队列。
参数 :maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。
底层队列使用管道和锁定实现。
Queue([maxsize])
创建共享的进程队列。maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。底层队列使用管道和锁定实现。另外,还需要运行支持线程以便队列中的数据传输到底层管道中。
Queue的实例q具有以下方法:
q.get( [ block [ ,timeout ] ] )
返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True. 如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。如果在制定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
q.get_nowait( )
同q.get(False)方法。
q.put(item [, block [,timeout ] ] )
将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
q.qsize()
返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
q.empty()
如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
q.full()
如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的(参考q.empty()方法)。。
q.close()
关闭队列,防止队列中加入更多数据。调用此方法时,后台线程将继续写入那些已入队列但尚未写入的数据,但将在此方法完成时马上关闭。如果q被垃圾收集,将自动调用此方法。关闭队列不会在队列使用者中生成任何类型的数据结束信号或异常。例如,如果某个使用者正被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
q.cancel_join_thread()
不会再进程退出时自动连接后台线程。这可以防止join_thread()方法阻塞。
q.join_thread()
连接队列的后台线程。此方法用于在调用q.close()方法后,等待所有队列项被消耗。默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread()方法可以禁止这种行为。
简单用法:
|
1
2
3
4
5
6
|
from
multiprocessing
import
Process,Queue
q
=
Queue()
#创建共享的进程队列
q.put(
1
)
# 将一个值放入队列
q.put(
2
)
q.put(
'aaa'
)
print
(q.get())
# 返回q中的一个项目
|
执行输出:1
因为1先进去,所以它先出来。
|
1
2
3
4
5
6
7
8
9
|
from
multiprocessing
import
Process,Queue
def
wahaha(q):
print
(q.get())
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
Process(target
=
wahaha,args
=
(q,)).start()
q.put(
1
)
|
执行输出:1
因为主程序先执行
双向通信
既能取值,也能增加值
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import
time
from
multiprocessing
import
Process,Queue
def
wahaha(q):
print
(q.get())
# 取值
q.put(
'aaa'
)
# 增加一个aaa
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
Process(target
=
wahaha,args
=
(q,)).start()
q.put(
1
)
time.sleep(
0.5
)
# 等待0.5秒,让子程序执行完
print
(q.get())
# 取值
|
执行输出:
1
aaa
''' multiprocessing模块支持进程间通信的两种主要形式:管道和队列 都是基于消息传递实现的,但是队列接口 ''' from multiprocessing import Queue q=Queue(3) #put ,get ,put_nowait,get_nowait,full,empty q.put(3) q.put(3) q.put(3) # q.put(3) # 如果队列已经满了,程序就会停在这里,等待数据被别人取走,再将数据放入队列。 # 如果队列中的数据一直不被取走,程序就会永远停在这里。 try: q.put_nowait(3) # 可以使用put_nowait,如果队列满了不会阻塞,但是会因为队列满了而报错。 except: # 因此我们可以用一个try语句来处理这个错误。这样程序不会一直阻塞下去,但是会丢掉这个消息。 print('队列已经满了') # 因此,我们再放入数据之前,可以先看一下队列的状态,如果已经满了,就不继续put了。 print(q.full()) #满了 print(q.get()) print(q.get()) print(q.get()) # print(q.get()) # 同put方法一样,如果队列已经空了,那么继续取就会出现阻塞。 try: q.get_nowait(3) # 可以使用get_nowait,如果队列满了不会阻塞,但是会因为没取到值而报错。 except: # 因此我们可以用一个try语句来处理这个错误。这样程序不会一直阻塞下去。 print('队列已经空了') print(q.empty()) #空了
上面这个例子还没有加入进程通信,只是先来看看队列为我们提供的方法,以及这些方法的使用和现象。
import time from multiprocessing import Process, Queue def f(q): q.put([time.asctime(), 'from Eva', 'hello']) #调用主函数中p进程传递过来的进程参数 put函数为向队列中添加一条数据。 if __name__ == '__main__': q = Queue() #创建一个Queue对象 p = Process(target=f, args=(q,)) #创建一个进程 p.start() print(q.get()) p.join()
上面是一个queue的简单应用,使用队列q对象调用get函数来取得队列中最先进入的数据。 接下来看一个稍微复杂一些的例子:
import os import time import multiprocessing # 向queue中输入数据的函数 def inputQ(queue): info = str(os.getpid()) + '(put):' + str(time.asctime()) queue.put(info) # 向queue中输出数据的函数 def outputQ(queue): info = queue.get() print ('%s%s\033[32m%s\033[0m'%(str(os.getpid()), '(get):',info)) # Main if __name__ == '__main__': multiprocessing.freeze_support() record1 = [] # store input processes record2 = [] # store output processes queue = multiprocessing.Queue(3) # 输入进程 for i in range(10): process = multiprocessing.Process(target=inputQ,args=(queue,)) process.start() record1.append(process) # 输出进程 for i in range(10): process = multiprocessing.Process(target=outputQ,args=(queue,)) process.start() record2.append(process) for p in record1: p.join() for p in record2: p.join()
生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
生产者消费者模型
消费者 消费数据 吃包子
生产者 产生数据的人 做包子
假如生产了10个包子,但是来了15个人,供不应求了。
这就产生了供销矛盾,那怎么解决呢?
增加做包子的人
或者采用同步模式 :做一个包子 卖一包子
再举一个例子:
生产数据 在淘宝买东西 --- 产生消费者行为数据
消费数据 阿里巴巴 --- 即时性要求非常高 必须要快速把用户生产的数据消费完
看下图
笼屉,只能放100个包子
如果蒸包子的数量过多,没人买了,那么就需要减少蒸包子的人
如果蒸包子的根据买包子的人,来生产包子,就比较完美了
queue队列就是笼屉
基于队列实现生产者消费者模型
举例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import
time
import
random
from
multiprocessing
import
Process,Queue
def
producer(q):
#生产者
for
i
in
range
(
5
):
# 生产5个包子
time.sleep(random.random())
# 模拟生产包子时间
q.put(
'包子%s'
%
i)
def
consumer(q):
# 消费者
for
i
in
range
(
5
):
# 5个消费者
print
(q.get())
# 买一个包子
time.sleep(random.random())
# 模拟吃包子时间
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
p1
=
Process(target
=
producer,args
=
(q,))
p2
=
Process(target
=
consumer, args
=
(q,))
p1.start()
# 启动进程
p2.start()
|
执行输出:
包子0
包子1
包子2
包子3
包子4
增加颜色,显示更明显
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import
time
import
random
from
multiprocessing
import
Process,Queue
def
producer(q):
#生产者
for
i
in
range
(
1
,
6
):
# 生产5个包子
time.sleep(random.random())
# 模拟生产包子时间
print
(
'\033[1;31m生产了包子%s\033[0m'
%
i)
def
consumer(q):
# 消费者
for
i
in
range
(
1
,
6
):
# 5个消费者
print
(
'\033[1;32m消费了包子%s\033[0m'
%
i)
time.sleep(random.uniform(
1
,
2
))
# 模拟吃包子时间
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
p1
=
Process(target
=
producer,args
=
(q,))
p2
=
Process(target
=
consumer, args
=
(q,))
p1.start()
# 启动进程
p2.start()
|
执行输出:
发现供需不平衡
需要改变供需平衡
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import
time
import
random
from
multiprocessing
import
Process,Queue
def
producer(q):
#生产者
for
i
in
range
(
1
,
11
):
# 生产5个包子
time.sleep(random.random())
# 模拟生产包子时间
q.put(
'包子%s'
%
i)
# 生产包子,将包子放入队列,比如包子1
print
(
'\033[1;31m生产了包子%s\033[0m'
%
i)
def
consumer(q):
# 消费者
for
i
in
range
(
1
,
6
):
# 5个消费者
food
=
q.get()
# 买一个包子
print
(
'\033[1;32m消费了包子%s\033[0m'
%
food)
time.sleep(random.uniform(
1
,
2
))
# 模拟吃包子时间
if
__name__
=
=
'__main__'
:
q
=
Queue()
#创建共享的进程队列
p1
=
Process(target
=
producer,args
=
(q,))
p2
=
Process(target
=
consumer, args
=
(q,))
p3
=
Process(target
=
consumer, args
=
[q])
# 增加一个消费者进程
p1.start()
# 启动进程
p2.start()
p3.start()
|
执行输出:
上面是通过消费者和包子数量对等,解决供需平衡问题的。
其他例子:
基于队列实现生产者消费者模型
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): for i in range(10): time.sleep(random.randint(1,3)) res='包子%s' %i q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) #开始 p1.start() c1.start() print('主')
此时的问题是主进程永远不会结束,原因是:生产者p在生产完后就结束了,但是消费者c在取空了q之后,则一直处于死循环中且卡在q.get()这一步。
解决方式无非是让生产者在生产完毕后,往队列中再发一个结束信号,这样消费者在接收到结束信号后就可以break出死循环。
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() if res is None:break #收到结束信号则结束 time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): for i in range(10): time.sleep(random.randint(1,3)) res='包子%s' %i q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) q.put(None) #发送结束信号 if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) #开始 p1.start() c1.start() print('主')
注意:结束信号None,不一定要由生产者发,主进程里同样可以发,但主进程需要等生产者结束后才应该发送该信号
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() if res is None:break #收到结束信号则结束 time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(q): for i in range(2): time.sleep(random.randint(1,3)) res='包子%s' %i q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=(q,)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) #开始 p1.start() c1.start() p1.join() q.put(None) #发送结束信号 print('主')
但上述解决方式,在有多个生产者和多个消费者时,我们则需要用一个很low的方式去解决
from multiprocessing import Process,Queue import time,random,os def consumer(q): while True: res=q.get() if res is None:break #收到结束信号则结束 time.sleep(random.randint(1,3)) print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res)) def producer(name,q): for i in range(2): time.sleep(random.randint(1,3)) res='%s%s' %(name,i) q.put(res) print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res)) if __name__ == '__main__': q=Queue() #生产者们:即厨师们 p1=Process(target=producer,args=('包子',q)) p2=Process(target=producer,args=('骨头',q)) p3=Process(target=producer,args=('泔水',q)) #消费者们:即吃货们 c1=Process(target=consumer,args=(q,)) c2=Process(target=consumer,args=(q,)) #开始 p1.start() p2.start() p3.start() c1.start() p1.join() #必须保证生产者全部生产完毕,才应该发送结束信号 p2.join() p3.join() q.put(None) #有几个消费者就应该发送几次结束信号None q.put(None) #发送结束信号 print('主')