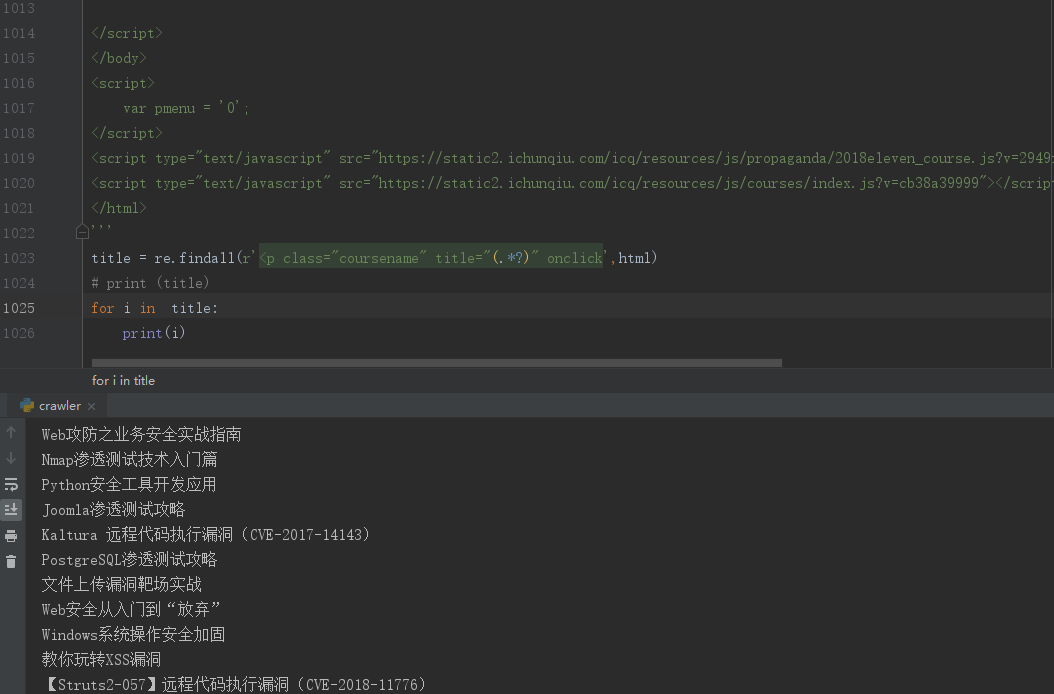
1.获取当前页的课程名称,地址:https://www.ichunqiu.com/courses/webaq
2.选区其中一门课程名称查看源代码:
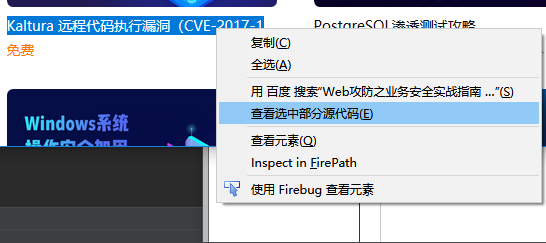
代码如下:
<p class="coursename" title="Kaltura 远程代码执行漏洞(CVE-2017-14143)" onclick="javascript:window.open
3.正则表达式获取课程名称:
#coding=utf-8 import re html = ''' <!DOCTYPE html> <html> #此处为需要爬去页面的源代码 </html> ''' title = re.findall(r'<p class="coursename" title="(.*?)" onclick',html) print (title)
执行结果如下:页面所以课程名称获取到
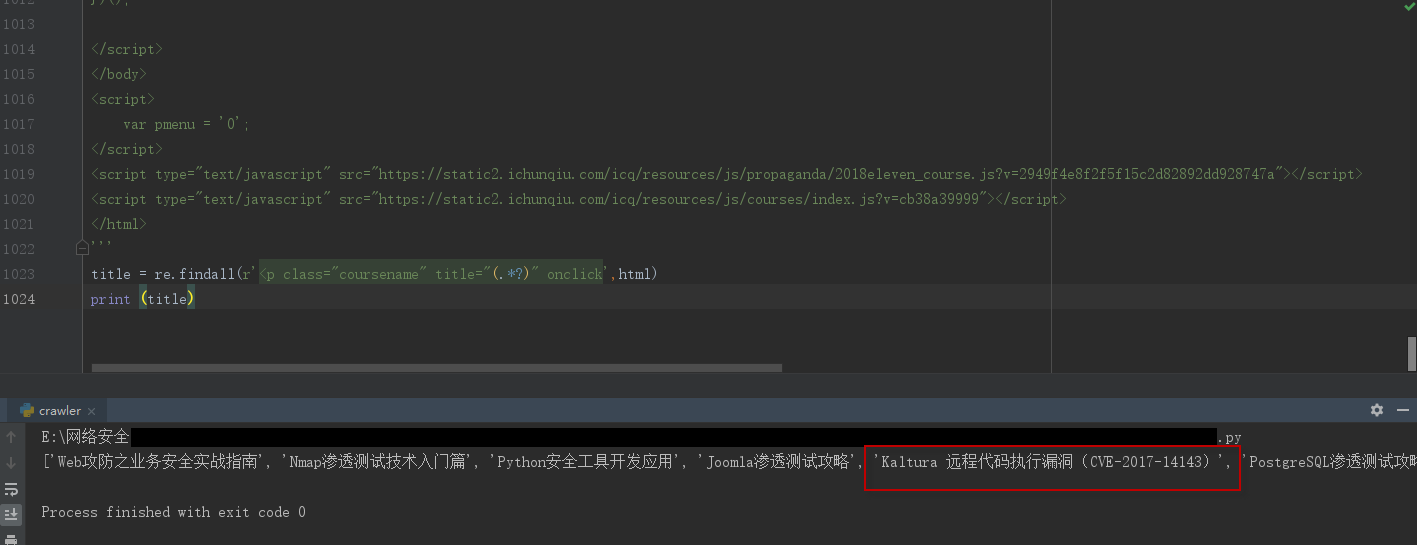
遍历:
#coding=utf-8 import re html = ''' <!DOCTYPE html> <html> #此处为需要爬去页面的源代码 </html> ''' title = re.findall(r'<p class="coursename" title="(.*?)" onclick',html) # print (title) for i in title: print(i)
效果如下: