Introduction
人工智能和机器学习将成为我们未来十年的最大帮手!
今天早上,我正在阅读一篇文章,该文章报道了一个人工智能系统赢得了20名律师的支持,而律师们实际上很高兴人工智能能够处理重复的部分角色并帮助他们处理复杂的主题。 这些律师很高兴人工智能将使他们能够拥有更多充实的角色。
今天,我将分享一个类似的例子 - 如何使用深度学习和计算机视觉计算人群中的人数? 但是,在我们这样做之前 - 让我们逐渐了解人群计数科学家的生活是多么容易。
Act like a Crowd Counting Scientist
开始吧!
你能帮我估算/估计这张照片参加这个活动的人数吗?

好的 - 这个怎么样?

你了解它。 在本教程结束时,我们将以惊人的准确度创建一个人群计数算法(与您和我一样的人类相比)。 你会用这样的助手吗?
附: 本文假设您具有卷积神经网络(CNN)如何工作的基本知识。 在继续操作之前,您可以参考以下帖子来了解此主题:
Table of Contents
- 什么是人群计数?
- 为什么需要人群计数?
- 了解用于人群计数的不同计算机视觉技术
- CSRNet的架构和培训方法
- 在Python中构建自己的Crowd Counting模型
本文受到了文章的极大启发 - CSRNet:用于理解高度拥挤场景的扩张卷积神经网络。
What is Crowd Counting?
人群计数是一种计算或估计图像中人数的技术。 花点时间分析下图:

你能告诉我框架中有多少人? 是的,包括背景中存在的那些。 最直接的方法是手动计算每个人,但这是否具有实际意义? 当人群如此庞大时,这几乎是不可能的!

人群科学家(是的,这是一个真正的职位!)计算图像某些部分的人数,然后推断出来估算。 更常见的是,我们不得不依靠粗略的指标来估算这个数字几十年。
当然必须有更好,更精确的方法吗?
就在这里!
虽然我们还没有能够为我们提供精确数字的算法,但大多数计算机视觉技术都能产生令人印象深刻的精确估算。 让我们首先理解为什么人群计数在深入研究背后的算法之前很重要。
Why is Crowd Counting useful?
让我们通过一个例子来理解人群计数的有用性。 想象一下 - 贵公司刚刚完成了一次大型数据科学会议。 活动期间举行了许多不同的会议。
您被要求分析和估计参加每个会话的人数。 这将有助于您的团队了解哪种会议吸引了最多的人群(以及哪些会议在这方面失败)。 这将形成明年的会议,所以这是一项重要任务!

活动中有数百人 - 手动计算它们需要数天时间! 这就是你的数据科学家的技能所在。你设法从每个会话中获得人群的照片,并建立一个计算机视觉模型来完成剩下的工作!
还有很多其他场景,人群计数算法正在改变行业的运作方式:
- 计算参加体育赛事的人数
- 估计有多少人参加了就职典礼或游行(也许是政治集会)
- 监测人流量大的区域
- 帮助配置人员配置和资源分配
你能提出一些其他用例吗? 请在下面的评论部分告诉我们! 我们可以连接并尝试弄清楚如何在您的场景中使用人群计数技术。
Understanding the Different Computer Vision Techniques for Crowd Counting
从广义上讲,目前我们可以使用四种方法来计算人群中的人数:
1.基于检测的方法
在这里,我们使用移动的窗口式探测器来识别图像中的人并计算其中的人数。用于检测的方法需要经过良好训练的分类器,其可以提取低级特征。尽管这些方法适用于检测面部,但它们在拥挤的图像上表现不佳,因为大多数目标对象不清晰可见。
2.基于回归的方法
我们无法使用上述方法提取低级功能。基于回归的方法在这里胜出。我们首先从图像中裁剪补丁,然后为每个补丁提取低级特征。
3.基于密度估计的方法
我们首先为对象创建密度图。然后,该算法学习提取的特征与其对象密度图之间的线性映射。我们还可以使用随机森林回归来学习非线性映射。
4.基于CNN的方法
啊,旧的可靠的卷积神经网络(CNNs)。我们不是查看图像的补丁,而是使用CNN构建端到端的回归方法。这将整个图像作为输入并直接生成人群计数。 CNN在回归或分类任务方面运作良好,并且它们也证明了它们在生成密度图方面的价值。
CSRNet是我们将在本文中实现的一种技术,它可以部署更深入的CNN,用于捕获高级功能并生成高质量的密度映射,而不会扩展网络复杂性。在跳转到编码部分之前,让我们了解CSRNet是什么。
了解CSRNet的架构和培训方法
CSRNet使用VGG-16作为前端,因为它具有强大的转移学习能力。 VGG的输出大小是原始输入大小的1/3。 CSRNet还在后端使用扩张的卷积层。
但世界上有什么扩张的卷积?这是一个公平的问题。考虑下面的图像:
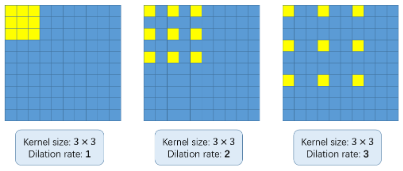
使用扩张卷积的基本概念是在不增加参数的情况下扩大内核。 因此,如果扩张率为1,我们将内核并在整个图像上进行卷积。 然而,如果我们将膨胀率增加到2,则内核如上图所示延伸(遵循每个图像下方的标签)。 它可以替代汇集图层。
基础数学(推荐,但可选)
我将花点时间解释一下数学是如何工作的。 请注意,这不是在Python中实现算法所必需的,但我强烈建议学习基本思想。 当您需要调整或修改模型时,这将派上用场。
假设我们有一个输入x(m,n),一个滤波器w(i,j)和一个扩张率r。 输出y(m,n)将是:
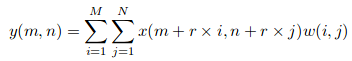
我们可以使用具有膨胀率r的(k * k)核来推广该等式。内核扩大到:
([k +(k-1)(r-1)] * [k +(k-1)(r-1)])
因此,为每张图像生成了基本事实。使用高斯内核模糊给定图像中的每个人的头部。所有图像都被裁剪成9个色块,每个色块的大小是图像原始大小的1/4。和我一起到目前为止?
前4个补丁分为4个季度,其他5个补丁随机裁剪。最后,每个补丁的镜像被用来使训练集加倍。
简而言之,这就是CSRNet背后的架构细节。接下来,我们将查看其培训详细信息,包括使用的评估指标。
随机梯度下降用于训练CSRNet作为端到端结构。在训练期间,固定学习率设置为1e-6。损失函数被认为是欧几里德距离,以便测量地面实况和估计密度图之间的差异。这表示为:
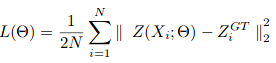
其中N是训练批次的大小。 CSRNet中使用的评估度量是MAE和MSE,即平均绝对误差和均方误差。 这些是由下式给出的:
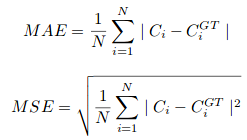
Here, Ci is the estimated count:
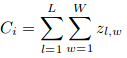
L和W是预测密度图的宽度。
我们的模型将首先预测给定图像的密度图。 如果没有人,则像素值将为0。 如果该像素对应于人,则将分配某个预定义值。 因此,计算与人对应的总像素值将为我们提供该图像中的人数。 太棒了吧?
现在,女士们,先生们,现在是时候建立我们自己的人群计数模型了!
建立自己的人群计数模型
你的笔记本电脑上电了吗?
我们将在ShanghaiTech数据集上实施CSRNet。 这包含1198个注释图像,总共330,165人。 您可以从此处下载数据集。
使用以下代码块克隆CSRNet-pytorch存储库。 这包含用于创建数据集,训练模型和验证结果的完整代码:
git clone https://github.com/leeyeehoo/CSRNet-pytorch.git
请在继续操作之前安装CUDA和PyTorch。 这些是我们将在下面使用的代码背后的支柱。
现在,将数据集移动到上面克隆的存储库中并解压缩。 然后我们需要创建基本真值。 make_dataset.ipynb文件是我们的救星。 我们只需要在那个笔记本上做一些小改动:
# importing libraries
import h5py
import scipy.io as io
import PIL.Image as Image
import numpy as np
import os
import glob
from matplotlib import pyplot as plt
from scipy.ndimage.filters import gaussian_filter
import scipy
import json
from matplotlib import cm as CM
from image import *
from model import CSRNet
import torch
from tqdm import tqdm
%matplotlib inline
# function to create density maps for images
def gaussian_filter_density(gt):
print (gt.shape)
density = np.zeros(gt.shape, dtype=np.float32)
gt_count = np.count_nonzero(gt)
if gt_count == 0:
return density
pts = np.array(list(zip(np.nonzero(gt)[1], np.nonzero(gt)[0])))
leafsize = 2048
# build kdtree
tree = scipy.spatial.KDTree(pts.copy(), leafsize=leafsize)
# query kdtree
distances, locations = tree.query(pts, k=4)
print ('generate density...')
for i, pt in enumerate(pts):
pt2d = np.zeros(gt.shape, dtype=np.float32)
pt2d[pt[1],pt[0]] = 1.
if gt_count > 1:
sigma = (distances[i][1]+distances[i][2]+distances[i][3])*0.1
else:
sigma = np.average(np.array(gt.shape))/2./2. #case: 1 point
density += scipy.ndimage.filters.gaussian_filter(pt2d, sigma, mode='constant')
print ('done.')
return density
#setting the root to the Shanghai dataset you have downloaded
# change the root path as per your location of dataset
root = '/home/pulkit/CSRNet-pytorch/'
现在,让我们为part_A和part_B中的图像生成基本真值:
part_A_train = os.path.join(root,'part_A/train_data','images')
part_A_test = os.path.join(root,'part_A/test_data','images')
part_B_train = os.path.join(root,'part_B/train_data','images')
part_B_test = os.path.join(root,'part_B/test_data','images')
path_sets = [part_A_train,part_A_test]
img_paths = []
for path in path_sets:
for img_path in glob.glob(os.path.join(path, '*.jpg')):
img_paths.append(img_path)
for img_path in img_paths:
print (img_path)
mat = io.loadmat(img_path.replace('.jpg','.mat').replace('images','ground-truth').replace('IMG_','GT_IMG_'))
img= plt.imread(img_path)
k = np.zeros((img.shape[0],img.shape[1]))
gt = mat["image_info"][0,0][0,0][0]
for i in range(0,len(gt)):
if int(gt[i][1])<img.shape[0] and int(gt[i][0])<img.shape[1]:
k[int(gt[i][1]),int(gt[i][0])]=1
k = gaussian_filter_density(k)
with h5py.File(img_path.replace('.jpg','.h5').replace('images','ground-truth'), 'w') as hf:
hf['density'] = k
为每个图像生成密度图是一个耗时的步骤。 因此,在代码运行时,冲泡一杯咖啡。
到目前为止,我们已经为part_A中的图像生成了基本真值。 我们将对part_B图像执行相同的操作。 但在此之前,让我们看一个示例图像并绘制其地面真实热图:
plt.imshow(Image.open(img_paths[0]))

现在越来越有趣了!
gt_file = h5py.File(img_paths[0].replace('.jpg','.h5').replace('images','ground-truth'),'r')
groundtruth = np.asarray(gt_file['density'])
plt.imshow(groundtruth,cmap=CM.jet)

让我们来计算这张图片中有多少人:
np.sum(groundtruth)
270.32568
同样,我们将为part_B生成值:
path_sets = [part_B_train,part_B_test]
img_paths = []
for path in path_sets:
for img_path in glob.glob(os.path.join(path, '*.jpg')):
img_paths.append(img_path)
# creating density map for part_b images
for img_path in img_paths:
print (img_path)
mat = io.loadmat(img_path.replace('.jpg','.mat').replace('images','ground-truth').replace('IMG_','GT_IMG_'))
img= plt.imread(img_path)
k = np.zeros((img.shape[0],img.shape[1]))
gt = mat["image_info"][0,0][0,0][0]
for i in range(0,len(gt)):
if int(gt[i][1])<img.shape[0] and int(gt[i][0])<img.shape[1]:
k[int(gt[i][1]),int(gt[i][0])]=1
k = gaussian_filter_density(k)
with h5py.File(img_path.replace('.jpg','.h5').replace('images','ground-truth'), 'w') as hf:
hf['density'] = k
现在,我们有图像以及相应的地面实况值。 是时候训练我们的模型!
我们将使用克隆目录中提供的.json文件。 我们只需要更改json文件中图像的位置。 为此,请打开.json文件,并将当前位置替换为图像所在的位置。
请注意,所有这些代码都是用Python 2编写的。如果您正在使用任何其他Python版本,请进行以下更改:
- 在model.py中,将第18行中的xrange更改为range
- 更改model.py中的第19行:list(self.frontend.state_dict().items())[i][1].data[:] = list(mod.state_dict().items())[i][1].data[:]
- 在image.py中,将ground_truth替换为ground-true
做出改变? 现在,打开一个新的终端窗口并键入以下命令:
cd CSRNet-pytorch
python train.py part_A_train.json part_A_val.json 0 0
再次,请坐下来因为这需要一些时间。 您可以减少train.py文件中的纪元数以加速该过程。 如果您不想等待,可以选择下载预先训练好的权重来自此处。
最后,让我们检查模型在看不见的数据上的表现。 我们将使用val.ipynb文件来验证结果。 请记住更改预训练重量和图像的路径。
#importing libraries
import h5py
import scipy.io as io
import PIL.Image as Image
import numpy as np
import os
import glob
from matplotlib import pyplot as plt
from scipy.ndimage.filters import gaussian_filter
import scipy
import json
import torchvision.transforms.functional as F
from matplotlib import cm as CM
from image import *
from model import CSRNet
import torch
%matplotlib inline
from torchvision import datasets, transforms
transform=transforms.Compose([
transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
#defining the location of dataset
root = '/home/pulkit/CSRNet/ShanghaiTech/CSRNet-pytorch/'
part_A_train = os.path.join(root,'part_A/train_data','images')
part_A_test = os.path.join(root,'part_A/test_data','images')
part_B_train = os.path.join(root,'part_B/train_data','images')
part_B_test = os.path.join(root,'part_B/test_data','images')
path_sets = [part_A_test]
#defining the image path
img_paths = []
for path in path_sets:
for img_path in glob.glob(os.path.join(path, '*.jpg')):
img_paths.append(img_path)
model = CSRNet()
#defining the model
model = model.cuda()
#loading the trained weights
checkpoint = torch.load('part_A/0model_best.pth.tar')
model.load_state_dict(checkpoint['state_dict'])
检查测试图像上的MAE(平均绝对误差)以评估我们的模型:
mae = 0
for i in tqdm(range(len(img_paths))):
img = transform(Image.open(img_paths[i]).convert('RGB')).cuda()
gt_file = h5py.File(img_paths[i].replace('.jpg','.h5').replace('images','ground-truth'),'r')
groundtruth = np.asarray(gt_file['density'])
output = model(img.unsqueeze(0))
mae += abs(output.detach().cpu().sum().numpy()-np.sum(groundtruth))
print (mae/len(img_paths))
我们的MAE值为75.69,非常好。 现在让我们检查单个图像上的预测:
from matplotlib import cm as c
img = transform(Image.open('part_A/test_data/images/IMG_100.jpg').convert('RGB')).cuda()
output = model(img.unsqueeze(0))
print("Predicted Count : ",int(output.detach().cpu().sum().numpy()))
temp = np.asarray(output.detach().cpu().reshape(output.detach().cpu().shape[2],output.detach().cpu().shape[3]))
plt.imshow(temp,cmap = c.jet)
plt.show()
temp = h5py.File('part_A/test_data/ground-truth/IMG_100.h5', 'r')
temp_1 = np.asarray(temp['density'])
plt.imshow(temp_1,cmap = c.jet)
print("Original Count : ",int(np.sum(temp_1)) + 1)
plt.show()
print("Original Image")
plt.imshow(plt.imread('part_A/test_data/images/IMG_100.jpg'))
plt.show()

哇,原计数是382,我们的模型估计图像中有384人。 这是一个令人印象深刻的表现!
恭喜您建立自己的人群计数模型!
End Notes
我鼓励您在不同的图片上尝试这种方法,并在下面的评论部分分享您的结果。 人群计数有很多不同的应用程序,并且已经被组织和政府机构采用。
添加到您的投资组合中是一项有用的技能。 相当多的行业都在寻找可以使用人群计数算法的数据科学家。 学习它,尝试它,并给自己深刻学习的礼物!
你觉得这篇文章有用吗? 请随时在下面留下您的建议和反馈,我很乐意与您联系。