MazePathFinder using deep Q Networks
该程序将由几个封锁(由块颜色表示)组成的图像作为输入,起始点由蓝色表示,目的地由绿色表示。 它输出一个由输入到输出的可能路径之一组成的图像。 下面显示的是程序的输入和输出。
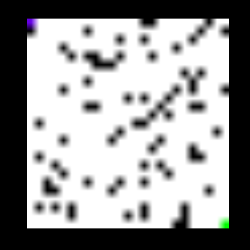
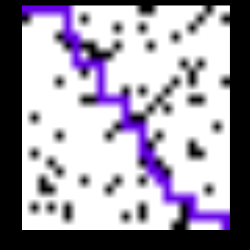
输入图像被馈送到由2个conv和2个fc层组成的模型,其输出对应于底部和右侧动作的Q值。 代理根据哪个Q值更大而向右或向下移动,并且使用代理的新位置生成的相应新图像再次被馈送到模型。获得输出状态并反馈新图像的过程保持重复 直到代理到达到达目的地的终端阶段。
Data Generation
代码DataGeneration.py为任务生成必需的数据。 它在25X25大小的图像中随机分配1X1像素大小的块。同时生成对应于每个不同起始位置的所有625个图像并将其存储在文件夹中。具有变化的阻塞位置的200个不同的这样的游戏的图像是 生成,因此总训练图像达250 * 625。 还生成与每个不同状态(图像)相关联的分数并将其存储在txt文件中,其中起始点与阻塞碰撞的状态获得-100的分数,当起始点与目的地碰撞时,其获得分数 100和所有剩余的状态得分为0。
Training
InitialisingTarget.py生成与每个训练图像相关联的初始Q值,并将它们存储在txt文件-Targets200_New.txt中。生成的Q值只不过是随机初始化模型的输出。 training2.py开始训练模型。从trainig数据中选择随机批量大小的图像集并将其馈送到模型。根据损失更新模型权重,该损失是输出Q值和预期Q值之间的平方差异。预期的Q(s,a)= r(s,a)+ gamma * max(Q1(s1,a)),其中max取2个动作。这里Q1对应于存储在’Targets200_New.txt’文件中的q值。奖励r也是下一个州和当前州之间得分的差异。几个训练Q1值的时期再次更新并存储在相同的txt文件中,输出来自训练模型。新的Q1值再次用于训练模型。生成目标Q值和训练模型的步骤重复几个步骤,直到模型学习所需特征。
Testing
就像DataGeneration.py一样,TestDataCollection.py也以相同的格式生成图像,除了它不是200个游戏,而是在单独的文件夹中生成仅对应20个游戏的图像。 对于20个游戏中的每个游戏,testing.py获取对应于代理位于0,0位置的图像,并将单个最终路径的图像输出到单独的文件夹中的目的地。 对于由于与阻塞冲突而无法找到路径的游戏,不会生成图像。