一、引言
本文记录了困扰团队两周的HBase随机宕机事件的解决方案,并回顾了JVM GC调优基础知识,供各位参考。
欢迎转载,请注明出处:
http://blog.csdn.net/u010967382/article/details/42394031
二、实验环境
16台虚拟机,每台4G内存,1核CPU,400G硬盘
Ubuntu 14.04 LTS (GNU/Linux 3.13.0-29-generic x86_64)
CDH5.2.0套装(包括相应版本的Hadoop,HIVE,Hbase,Mahout,Sqoop,Zookeeper等)
Java 1.7.0_60
64-Bit Server
三、异常现场
在以上实验环境中执行计算任务,计算任务涉及HIVE、Mahout、Hbase bulkload、MapReduce,工作流驱动通过Shell脚本控制,整个任务执行过程涉及基础行为数据160万条,业务数据40万条。
多次执行任务过程中反复随机出现以下各类异常,仅用文字描述,就不拷贝异常现场了,大家各自对号入座:
1.Hbase的Regionserver进程随机挂掉(该异常几乎每次都发生,只是挂掉的Regionser节点不同)
2.HMaster进程随机挂掉
3.主备Namenode节点随机挂掉
4.Zookeeper节点随机挂掉
5.Zookeeper连接超时
6.JVM GC睡眠时间过长
7.datanode写入超时
等等
通过调研分析和调试,发现问题解决需从以下几个方面着手:
1.Hbase的ZK连接超时相关参数调优:默认的ZK超时设置太短,一旦发生FULL GC,极其容易导致ZK连接超时;
2.Hbase的JVM GC相关参数调优:可以通过GC调优获得更好的GC性能,减少单次GC的时间和FULL GC频率;
3.ZK Server调优:这里指的是ZK的服务端调优,ZK客户端(比如Hbase的客户端)的ZK超时参数必须在服务端超时参数的范围内,否则ZK客户端设置的超时参数起不到效果;
4.HDFS读写数据相关参数需调优;
5.YARN针对各个节点分配资源参数调整:YARN需根据真实节点配置分配资源,之前的YARN配置为每个节点分配的资源都远大于真实虚拟机的硬件资源;
6.集群规划需优化:之前的集群规划中,为了充分利用虚拟机资源,NameNode、NodeManager、DataNode,RegionServer会混用同一个节点,这样会导致这些关键的枢纽节点通信和内存压力过大,从而在计算压力较大时容易发生异常。正确的做法是将枢纽节点(NameNode,ResourceManager,HMaster)和数据+计算节点分开。
四、为了解决该问题而实施的各类配置及集群调整
HBase
hbase-site.xml
<property>
<name>zookeeper.session.timeout</name>
<value>300000</value>
</property>
<property>
<name>hbase.zookeeper.property.tickTime</name>
<value>60000</value>
</property>
<property>
<name>hbase.hregion.memstroe.mslab.enable</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.maxClientCnxns</name>
<value>10000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>240000</value>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>280000</value>
</property>
<property>
<name>hbase.hregion.max.filesize</name>
<value>107374182400</value>
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.client.socket-timeout</name>
<value>300000</value>
<description>Down the DFS timeout from 60 to 10 seconds.</description>
</property>
hbase-env.sh
export HBASE_HEAPSIZE=2048M
export HBASE_HOME=/home/fulong/Hbase/hbase-0.98.6-cdh5.2.0
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_OPTS="
-server -Xms1g -Xmx1g -XX:NewRatio=2 -XX:PermSize=128m -XX:MaxPermSize=128m -verbose:gc -Xloggc:$HBASE_HOME/logs/hbasegc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=$HBASE_HOME/logs"
zookeeper
zoo.cfg
syncLimit=10
#New in 3.3.0: the maximum session timeout in milliseconds that the server will allow the client to negotiate. Defaults to 20 times the tickTime.
maxSessionTimeout=300000
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/fulong/Zookeeper/CDH/zookdata
# the port at which the clients will connect
clientPort=2181
修改以下两个文件是为了跟踪ZK日志,ZK的默认日志查看不方便。
log4j.properties
zookeeper.root.logger=INFO,CONSOLE,ROLLINGFILE
zookeeper.console.threshold=INFO
zookeeper.log.dir=/home/fulong/Zookeeper/CDH/zooklogs
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=DEBUG
zookeeper.tracelog.dir=/home/fulong/Zookeeper/CDH/zooklogs
zookeeper.tracelog.file=zookeeper_trace.log
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
# Max log file size of 10MB
log4j.appender.ROLLINGFILE.MaxFileSize=50MB
zkEnv.sh
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,CONSOLE,ROLLINGFILE"
fi
备注:修改完以上两个文件后,并没有如愿的见到ZK的Log4j日志文件,原因待进一步调研。
HDFS
hdfs-site.xml
<property>
<name>dfs.datanode.socket.write.timeout</name>
<value>600000</value>
</property>
<property>
<name>dfs.client.socket-timeout</name>
<value>300000</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
YARN
yarn-site.xml
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.zk-timeout-ms</name>
<value>120000</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3072</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>128</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3072</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.nodemanager.container-monitor.interval-ms</name>
<value>300000</value>
</property>
集群调整
NN Active, NN Standby, RM Active, RM Standby 所在节点均不运行DN,NM,RS
DN、NM、RS所在节点一一对应。
调整过后的布局:

说明:如果遇到类似问题,可以重点参考以上配置项,但
具体数值请根据具体情况具体分析。
五、补充回顾--JVM GC
调优过程中GC问题十分明显,未调优之前,频繁出现3~6min的Full GC时间,调优过后,GC时间能控制在20s以内。
GC调优对于Hadoop集群十分重要,是必须掌握的基础知识,在此简单记录。
完整知识叙述请参见:
以及Oracle网站上的相关说明:
以下仅仅描述最重要的基础知识:
每个JVM主要内存区域分为两部分:
Permanent Space 和 Heap Space
。
Permanent即持久代(Permanent Generation),主要存放的是Java类定义信息,与垃圾收集器要收集的Java对象关系不大。
Heap={Old+NEW={Eden,Survivor 0 ,Survivor 1}}
,Old即老年代(Old Generation),New即年轻代(Young Generation)。
年轻代(Young Generation)
用来保存那些第一次被创建的对象,它进一步被分为三个空间:
一个伊甸园空间(Eden ),
两个幸存者空间(Survivor )。
老年代和年轻代的划分对垃圾收集影响比较大。
基本的执行顺序如下:
- 绝大多数刚刚被创建的对象会存放在伊甸园(Eden )空间。
- 在伊甸园(Eden )空间执行了第一次GC之后,存活的对象被移动到其中一个幸存者空间。
- 此后,在伊甸园空间执行GC之后,存活的对象会被堆积在同一个幸存者空间。
- 当一个幸存者空间饱和,还在存活的对象会被移动到另一个幸存者空间。之后会清空已经饱和的那个幸存者空间。
- 在以上的步骤中重复几次依然存活的对象,就会被移动到老年代。
截止目前版本,Java可配置的垃圾收集器有5种类型:
- Serial GC
- Parallel GC
- Parallel Old GC (Parallel Compacting GC)
- Concurrent Mark & Sweep GC (or “CMS”)
- Garbage First (G1) GC
其中用得较多比较成熟的是CMS。
我们可以通过各种工具来监控JVM GC情况,比较简单直观的是jstat。
比如我们要监控NameNode的GC情况,可以先用jps查看到进程号,然后通过jstat查看gc情况:
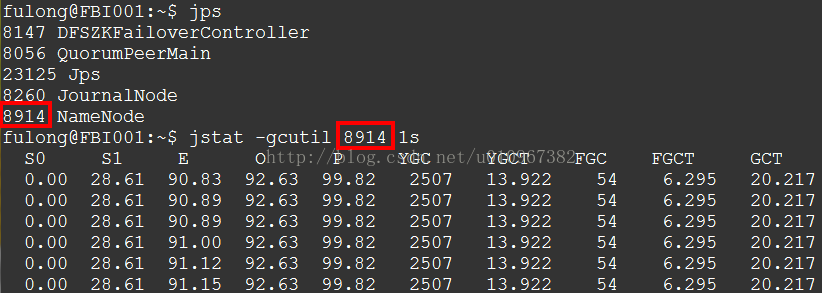
jstat -gcutil后面跟的参数是JVM进程号,1s是数据刷新时间。命令输出的每一列依次是:幸存者0的空间占用比例,幸存者1的空间占用比例,伊甸园空间的占用比例,老年代空间的占用比例,持久代空间的占用比例,年轻代(S0+S1+E)发生GC的次数,年轻代发生GC的总时间(秒为单位),FULL GC发生的次数,FULL GC发生的总时间
(秒为单位)
,GC消耗的总时间
(秒为单位)。
最后附上我们本次调优hbase设置的JVM参数:
-server //开启java服务器模式
-Xms1g //最小最大堆内存
-Xmx1g
-XX:NewRatio=2 //老年代空间:年轻代空间=2
-XX:PermSize=128m //初始和最大持久代空间,感觉可以进一步缩减,目前观察持久代空间使用没超过30%
-XX:MaxPermSize=128m
-Xloggc:$HBASE_HOME/logs/hbasegc.log //开启gc日志功能,便于调试,基本不会影响性能
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+UseParNewGC //开启CMS垃圾回收期
-XX:+CMSParallelRemarkEnabled
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75