虚拟内存管理
从用户向内核看,所使用的内存表象形式会依次经历“逻辑地址”——“线性地址”——“物理地址”几种形式(关于几种地址的解释在前面已经讲述了)。逻辑地址经段机制转化成线性地址;线性地址又经过页机制转化为物理地址。(但是我们要知道Linux系统虽然保留了段机制,但是将所有程序的段地址都定死为0-4G,所以虽然逻辑地址和线性地址是两种不同的地址空间,但在Linux中逻辑地址就等于线性地址,它们的值是一样的)。
Linux进程内存管理
参考《后台开发5.5.2》
https://www.cnblogs.com/ralap7/p/9184773.html
进程内存空间
Linux操作系统采用虚拟内存管理技术,使得每个进程都有各自互不干涉的进程地址空间。该空间是块大小为4G的线性虚拟空间,用户所看到和接触到的都是该虚拟地址,无法看到实际的物理内存地址。利用这种虚拟地址不但能起到保护操作系统的效果(用户不能直接访问物理内存),而且更重要的是,用户程序可使用比实际物理内存更大的地址空间(具体的原因请看硬件基础部分)。
l 第一、4G的进程地址空间被人为的分为两个部分——用户空间与内核空间。用户空间从0到3G(0xC0000000),内核空间占据3G到4G。用户进程通常情况下只能访问用户空间的虚拟地址,不能访问内核空间虚拟地址。只有用户进程进行系统调用(代表用户进程在内核态执行)等时刻可以访问到内核空间。
l 第二、用户空间对应进程,所以每当进程切换,用户空间就会跟着变化;而内核空间是由内核负责映射,它并不会跟着进程改变,是固定的。内核空间地址有自己对应的页表(init_mm.pgd),用户进程各自有不同的页表。
l 第三、**每个进程的用户空间都是完全独立、互不相干的。**不信的话,你可以把上面的程序同时运行10次(当然为了同时运行,让它们在返回前一同睡眠100秒吧),你会看到10个进程占用的线性地址一模一样。
进程内存管理
进程内存管理的对象是进程线性地址空间上的内存镜像,这些内存镜像其实就是进程使用的虚拟内存区域(memory region)。进程虚拟空间是个32或64位的“平坦”(独立的连续区间)地址空间(空间的具体大小取决于体系结构)。要统一管理这么大的平坦空间可绝非易事,为了方便管理,虚拟空间被划分为许多大小可变的(但必须是4096的倍数)内存区域,这些区域在进程线性地址中像停车位一样有序排列。这些区域的划分原则是“将访问属性一致的地址空间存放在一起”,所谓访问属性在这里无非指的是“可读、可写、可执行等”。
如果你要查看某个进程占用的内存区域,可以使用命令cat /proc//maps获得(pid是进程号)

每行数据格式如下:
(内存区域)开始-结束 访问权限 偏移 主设备号:次设备号 i节点 文件。程序内存段和进程地址空间中的内存区域是种模糊对应,也就是说,堆、bss、数据段(初始化过的)都在进程空间中由数据段内存区域表示。
在Linux内核中对应进程内存区域的数据结构是: vm_area_struct, 内核将每个内存区域作为一个单独的内存对象管理,相应的操作也都一致。采用面向对象方法使VMA结构体可以代表多种类型的内存区域--比如内存映射文件或进程的用户空间栈等,对这些区域的操作也都不尽相同。
vm_area_strcut结构比较复杂,关于它的详细结构请参阅相关资料。我们这里只对它的组织方法做一点补充说明。vm_area_struct是描述进程地址空间的基本管理单元,对于一个进程来说往往需要多个内存区域来描述它的虚拟空间,如何关联这些不同的内存区域呢?大家可能都会想到使用链表,的确vm_area_struct结构确实是以链表形式链接,不过为了方便查找,内核又以红黑树(以前的内核使用平衡树)的形式组织内存区域,以便降低搜索耗时。并存的两种组织形式,并非冗余:链表用于需要遍历全部节点的时候用,而红黑树适用于在地址空间中定位特定内存区域的时候。内核为了内存区域上的各种不同操作都能获得高性能,所以同时使用了这两种数据结构。
进程的地址空间管理模型
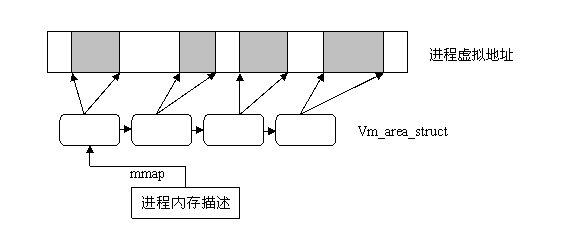
进程的地址空间对应的描述结构是“内存描述符结构”,它表示进程的全部地址空间,——包含了和进程地址空间有关的全部信息,其中当然包含进程的内存区域。
进程内存的分配与回收
创建进程fork()、程序载入execve()、映射文件mmap()、动态内存分配malloc()/brk()等进程相关操作都需要分配内存给进程。不过这时进程申请和获得的还不是实际内存,而是虚拟内存,准确的说是“内存区域”。进程对内存区域的分配最终都会归结到do_mmap()函数上来(brk调用被单独以系统调用实现,不用do_mmap())。
内核使用do_mmap()函数创建一个新的线性地址区间。但是说该函数创建了一个新VMA并不非常准确,因为如果创建的地址区间和一个已经存在的地址区间相邻,并且它们具有相同的访问权限的话,那么两个区间将合并为一个。如果不能合并,那么就确实需要创建一个新的VMA了。但无论哪种情况, do_mmap()函数都会将一个地址区间加入到进程的地址空间中--无论是扩展已存在的内存区域还是创建一个新的区域。同样,释放一个内存区域应使用函数do_ummap(),它会销毁对应的内存区域。
如何从虚拟地址变为物理地址
从上面已经看到进程所能直接操作的地址都为虚拟地址。当进程需要内存时,从内核获得的仅仅是虚拟的内存区域,而不是实际的物理地址,进程并没有获得物理内存(物理页面——页的概念请大家参考硬件基础一章),获得的仅仅是对一个新的线性地址区间的使用权。实际的物理内存只有当进程真的去访问新获取的虚拟地址时,才会由“请求页机制”产生“缺页”异常,从而进入分配实际页面的例程。
该异常是虚拟内存机制赖以存在的基本保证——它会告诉内核去真正为进程分配物理页,并建立对应的页表,这之后虚拟地址才实实在在地映射到了系统的物理内存上。(当然,如果页被换出到磁盘,也会产生缺页异常,不过这时不用再建立页表了)
这种请求页机制把页面的分配推迟到不能再推迟为止,并不急于把所有的事情都一次做完(这种思想有点像设计模式中的代理模式(proxy))。之所以能这么做是利用了内存访问的“局部性原理”,请求页带来的好处是节约了空闲内存,提高了系统的吞吐率。要想更清楚地了解请求页机制,可以看看《深入理解linux内核》一书。
这里我们需要说明在内存区域结构上的nopage操作。当访问的进程虚拟内存并未真正分配页面时,该操作便被调用来分配实际的物理页,并为该页建立页表项。在最后的例子中我们会演示如何使用该方法。
进程如何使用内存(组织内存区域的方式)
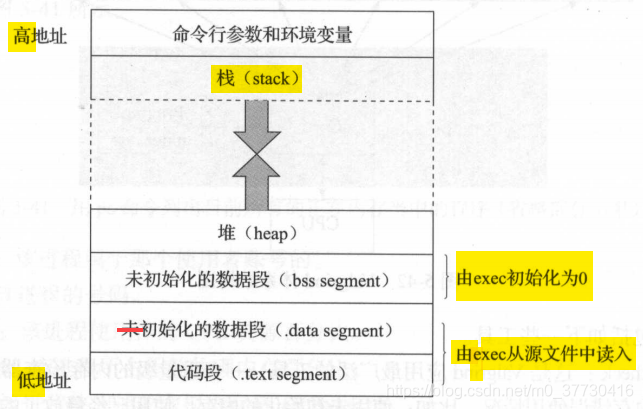
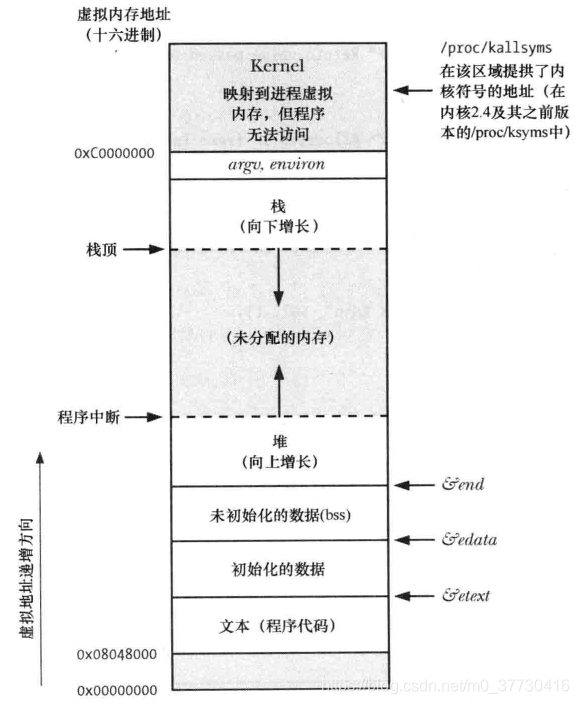
进程对应的内存空间中所包含的5种不同的数据区:
代码段:代码段是用来存放可执行文件的操作指令,也就是说是它是可执行程序在内存中的镜像。代码段需要防止在运行时被非法修改,所以只准许读取操作,而不允许写入(修改)操作——它是不可写的。
数据段:数据段用来存放可执行文件中已初始化全局变量,换句话说就是存放程序静态分配的变量和全局变量。static也存放在数据段,即静态存储区。 在C语言中,全局变量又分为初始化的和未初始化的,在C++里面没有这个区分了,他们共同占用同一块内存区。
BSS段[2]:BSS段包含了程序中未初始化的全局变量,在内存中 bss段全部置零。未初始化是在编译阶段未初始化,在内核调用exec函数启动该程序时会由exec初始化为0。
堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
动态申请的变量初始值为随机值。
栈:栈是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进后出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。
由高地址向低地址生长。存放局部变量(初始值为随机值),不包括static
C++内存管理
http://www.cnblogs.com/qiubole/archive/2008/03/07/1094770.html
https://www.jianshu.com/p/19771f5a89ea
http://www.cnblogs.com/QG-whz/p/5140930.html
对于C++的内存结构,主要有两种说法,一个是{栈区,堆区,全局区(静态区), 常量区,代码区}。另一种说法为{栈区,堆区,全局区(静态区), 自由存储区}。
在第二种说法中,增加了自由存储区,其与堆区没有本质区别,只是new分配的存储在堆区,malloc分配的存储在自由存储区。
内存分配方式
堆(heap)
堆(heap)是C语言和操作系统的术语。堆是操作系统所维护的一块特殊内存,它提供了动态分配的功能,当运行程序调用malloc()时就会从中分配,稍后调用free可把内存交还。
自由存储区
自由存储是C++中通过new和delete动态分配和释放对象的抽象概念,通过new来申请的内存区域可称为自由存储区。基本上,所有的C++编译器默认使用堆来实现自由存储,也即是缺省的全局运算符new和delete也许会按照malloc和free的方式来被实现,这时藉由new运算符分配的对象,说它在堆上也对,说它在自由存储区上也正确。但程序员也可以通过重载操作符,改用其他内存来实现自由存储,例如全局变量做的对象池,这时自由存储区就区别于堆了。我们所需要记住的就是:
堆是操作系统维护的一块内存,而自由存储是C++中通过new与delete动态分配和释放对象的抽象概念。堆与自由存储区并不等价。
栈
在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。里面的变量通常是局部变量或者函数参数。
全局/静态存储区
全局变量和静态变量被分配到同一块内存中,在以前的 C 语言中,全局变量又分为初始化的和未初始化的(初始化的全局变量和静态变量在一块区域,未初始化的全局变量与静态变量在相邻的另一块区域,同时未被初始化的对象存储区可以通过 void* 来访问和操纵,程序结束后由系统自行释放),在 C++ 里面没有这个区分了,他们共同占用同一块内存区。
常量存储区
一块比较特殊的存储区,他们里面存放的是常量,不允许修改(当然,你要通过非正当手段也可以修改,而且方法很多)
自由存储区和堆的区别
Bjarne Stroustrup的书籍中数次看到free store (自由存储区),说实话,我一直把自由存储区等价于堆。而在Herb Sutter的《exceptional C++》中,明确指出了free store(自由存储区) 与 heap(堆) 是有区别的。关于自由存储区与堆是否等价的问题讨论,大概就是从这里开始的。
堆和栈的区别
管理方式
对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制,容易产生内存泄漏。
空间大小
堆的大小理论上大概等于进程虚拟空间大小-内核虚拟内存大小。windows下,进程的高位2G留给内核,低位2G留给用户,所以进程堆的大小小于2G。Linux下,进程的高位1G留给内核,低位3G留给用户,所以进程堆大小小于3G。但是对于栈来讲,32位Windows,一个进程栈的默认大小是1M,在vs的编译属性可以修改程序运行时进程的栈大小。Linux下进程栈的默认大小是10M,可以通过 ulimit -s查看并修改默认栈大小。默认一个线程要预留1M左右的栈大小,所以进程中有N个线程时,Windows下大概有N*M的栈大小。
碎片问题
对于堆来讲,频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,他们是如此的一一对应,以至于永远都不可能有一个内存块从栈中间弹出,在他弹出之前,在他上面的后进的栈内容已经被弹出
生长方向
对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
分配方式
堆都是动态分配的,没有静态分配的堆。栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由 alloca 函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
分配效率
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是 C/C++ 函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
堆和栈相比,由于大量 new/delete 的使用,容易造成大量的内存碎片;由于没有专门的系统支持,效率很低;**由于可能引发用户态和核心态的切换,内存的申请,代价变得更加昂贵。**所以栈在程序中是应用最广泛的,就算是函数的调用也利用栈去完成,函数调用过程中的参数,返回地址,EBP 和局部变量都采用栈的方式存放。所以,我们推荐大家尽量用栈,而不是用堆。
虽然栈有如此众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,还是用堆好一些。
附:static相关内容
函数内部定义的变量,在程序执行到它的定义处时,编译器为它在栈上分配空间,函数在栈上分配的空间在此函数执行结束时会释放掉,这样就产生了一个问题: 如果想将函数中此变量的值保存至下一次调用时,如何实现? 最容易想到的方法是定义一个全局的变量,但定义为一个全局变量有许多缺点,最明显的缺点是破坏了此变量的访问范围(使得在此函数中定义的变量,不仅仅受此 函数控制)。需要一个数据对象为整个类而非某个对象服务,同时又力求不破坏类的封装性,即要求此成员隐藏在类的内部,对外不可见。
static内部机制:
静态数据成员要在程序一开始运行时就必须存在。因为函数在程序运行中被调用,所以静态数据成员不能在任何函数内分配空间和初始化。这样,它的空间分配有三个可能的地方,一是作为类的外部接口的头文件,那里有类声明;二是类定义的内部实现,那里有类的成员函数定义;三是应用程序的 main()函数前的全局数据声明和定义处。
静态数据成员要实际地分配空间,故不能在类的声明中定义(只能声明数据成员)。类声明只声明一个类的“尺寸和规格”,并不进行实际的内存分配,所以在类声明中写成定义是错误的。它也不能在头文件中类声明的外部定义,因为那会造成在多个使用该类的源文件中,对其重复定义。
static 被引入以告知编译器,将变量存储在程序的静态存储区而非栈上空间,静态数据成员按定义出现的先后顺序依次初始化,注意静态成员嵌套时,要保证所嵌套的成员已经初始化了。消除时的顺序是初始化的反顺序。
static优点:
可以节省内存,因为它是所有对象所公有的,因此,对多个对象来说,静态数据成员只存储一处,供所有对象共用。静态数据成员的值对每个对象都是一样,但它的 值是可以更新的。只要对静态数据成员的值更新一次,保证所有对象存取更新后的相同的值,这样可以提高时间效率。引用静态数据成员时,采用如下格式:
<类名>::<静态成员名>
如果静态数据成员的访问权限允许的话(即 public 的成员),可在程序中,按上述格式来引用静态数据成员。
另:
(1) 类的静态成员函数是属于整个类而非类的对象,所以它没有this指针,这就导致了它仅能访问类的静态数据和静态成员函数。
(2) 不能将静态成员函数定义为虚函数。
(3) 由于静态成员声明于类中,操作于其外,所以对其取地址操作,就多少有些特殊,变量地址是指向其数据类型的指针,函数地址类型是一个“nonmember 函数指针”。(nonmember 函数,用于每个参数都需要类型转化的情况)
(4) 由于静态成员函数没有 this 指针,所以就差不多等同于 nonmember 函数,结果就产生了一个意想不到的好处:成为一个 callback 函数,使得我们得以将 c++ 和 c-based x window 系统结合,同时也成功的应用于线程函数身上。
(5) static 并没有增加程序的时空开销,相反她还缩短了子类对父类静态成员的访问时间,节省了子类的内存空间。
(6) 静态数据成员在<定义或说明>时前面加关键字 static。
(7) 静态数据成员是静态存储的,所以必须对它进行初始化。
(8) 静态成员初始化与一般数据成员初始化不同:
初始化在类体外进行,而前面不加 static,以免与一般静态变量或对象相混淆;
初始化时不加该成员的访问权限控制符 private、public;
初始化时使用作用域运算符来标明它所属类;
所以我们得出静态数据成员初始化的格式:
<数据类型><类名>::<静态数据成员名>=<值>
(9) 为了防止父类的影响,可以在子类定义一个与父类相同的静态变量,以屏蔽父类的影响。这里有一点需要注意:我们说静态成员为父类和子类共享,但我们有重复定义了静态成员,这会不会引起错误呢?不会,我们的编译器采用了一种绝妙的手法:name-mangling 用以生成唯一的标志。
继续看
https://blog.csdn.net/caogenwangbaoqiang/article/details/79788368