1. 压缩的好处和坏处
压缩技术分为有损和无损:大数据场景下我们用到的都是无损;不允许丢失数据
好处
- 节省我们的磁盘空间,提升磁盘利用率
- 降低IO(网络的IO和磁盘的IO)
- 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度
缺点
- 由于使用数据时,需要先将数据解压,加重CPU负荷;所以如果整个集群cpu利用率非常高,不要开压缩;若集群负载不高,强烈建议开压缩!
压缩在Hadoop中的应用
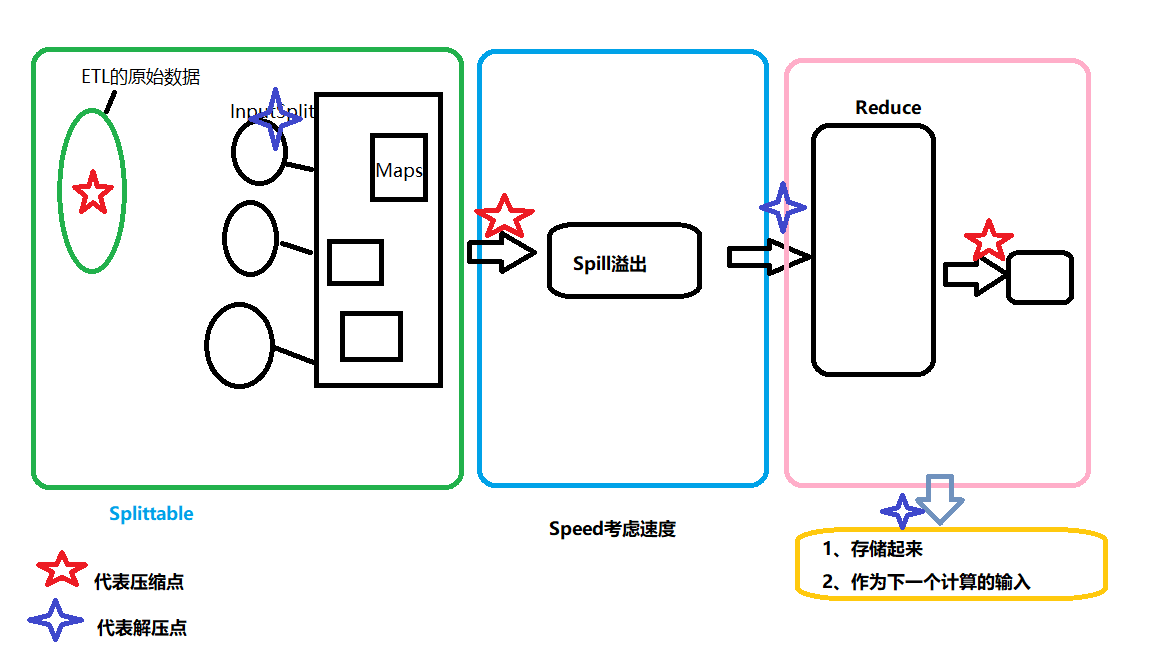
离线压缩场景
- input: Flume Sink HDFS < == Spark/MapReduce ##采用可分片的压缩方式
- temp: Sink DISK ## 采用速度快的压缩方式
- output: Spark/MapReduce = => Sink Hadoop ## 视情况而定采用
2. 压缩格式
| 压缩格式 | 工具 | 算法 | 扩展名 | codec类 | 多文件 | splitable | native | hadoop自带 | Hadoop编解码 |
| deflate | 无 | deflate | .deflate | DeflateCodec | 否 | 否 | 是 | 是 | org.apache.hadoop.io.compress.DeflateCodec |
| gzip | gzip | deflate | .gz | GzipCodec | 否 | 否 | 是 | 是 | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | Bzip2Codec | 是 | 是 | 否 | 是 | org.apache.hadoop.io.compress.Bzip2Codec |
| lzo | lzop | lzo | .lzo | LzopCodec | 否 | 是[ifIndex] | 否 | 否 | com.hadoop.compression.lzo.LzoCodec |
| lz4 | 无 | lz4 | .lz4 | Lz4Codec | 否 | 否 | 是 | 否 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | 无 | Snappy | .snappy | SnappyCodec | 否 | 否 | 是 | 否 | org.apache.hadoop.io.compress.SnappyCodec |
注:压缩格式中,有的不支持native是因为缺少so包(有的压缩是java写的,有的是c写的,比如lzo就是c写的)
压缩比

| 压缩格式 | 压缩比 | 压缩速度 | 解压速度 |
| Snappy | 49.9% | 218.8MB/s | 70.7MB/s |
| LZ4 | 49.3% | 217.5MB/s | 594.4MB/s |
| LZO | 48.7% | 184.3MB/s | 125.6MB/s |
| Gzip/deflate | 31.8% | 16.3MB/s | 64.2MB/s |
| Bzip2 | 27.7% | 9.8MB/s | 22.2MB/s |
可以看出,压缩比越高,压缩时间越长,压缩比:Snappy<LZ4<LZO<GZIP<BZIP2
3.压缩格式各自优缺点
a. gzip
优点:
压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便
缺点:
不支持split
b. lzo
优点:
压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便
缺点:
压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式)
c. snappy
优点:
压缩速度快;支持hadoop native库
缺点:
不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令
d. bzip2
优点:
支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便
缺点:
压缩/解压速度慢;不支持native
总结:
不同的场景选择不同的压缩方式,肯定没有一个一劳永逸的方法,如果选择高压缩比,那么对于cpu的性能要求要高,同时压缩、解压时间耗费也多;选择压缩比低的,对于磁盘io、网络io的时间要多,空间占据要多;对于支持分割的,可以实现并行处理。
应用场景:
input: Flume Sink HDFS <== Spark/MapReduce 比如flume采集到hdfs会使用到压缩
temp: Sink DISK 比如中间数据落地磁盘也可以使用压缩
output: Spark/MapReduce ==> Sink Hadoop 比如spark/mr的输出会到hdfs使用到压缩
一般在HDFS 、Hive、HBase中会使用;
当然一般较多的是结合Spark 来一起使用。