10.1 进程概念及应用
1.1 两种类型的服务器端
“第一个连接请求的受理时间为0秒,第50个连接请求的受理时间为50秒,第100个连接请求的受理时间为100秒!但只要受理,服务只需1秒钟。”
如果排在前面的请求数能用一只手数清,客户端当然会对服务器感到满意。但只要超过这个数,客户端就会开始抱怨。还不如用下面这种方式提供服务。
“所有连接请求的受理时间不超过1秒,但平均服务时间为2~3秒。”
1.2 并发服务器端的实现方法
即使有可能延长服务时间,也有必要改进服务器端,使其同时向所有发起请求的客户端提供服务,以提高平均满意度。而且,网络程序中数据通信时间比CPU运算时间占比更大,因此,向多个客户端提供服务是一种有效利用CPU的方式。接下来讨论同时向多个客户端提供服务的并发服务器端。下面列出的是具有代表性的并发服务器端实现模型和方法。
- 多进程服务器:通过创建多个进程提供服务。(Windows不支持)
- 多路复用服务器:通过捆绑并统一管理I/O对象提供服务。
- 多线程服务器:通过生成与客户端等量的线程提供服务。
接下来学习第一种方法:多进程服务器
1.3 理解进程(Process)
进程,其定义如下:
“占用内存空间的正在运行的程序”
举例:
从网上下载了游戏并安装到硬盘。此时的游戏并非进程,而是程序。因为游戏并未进入运行状态。下面开始运行程序。此时游戏被加载到主内存并进入运行状态,这时才可成为进程。
再举个例子:
假设各位打开文档编辑软件,打开MP3播放器,再开MSN软件。此时共创建3个进程。从操作系统的角度看,进程是程序流的基本单位,若创建多个进程,则操作系统将同时运行。有时一个程序运行过程中也会产生多个进程。接下来要创建的多进程服务器就是其中的代表。
1.4 进程ID
无论进程是如何创建的,所有进程都会从操作系统分配到ID。此ID成为“进程ID”,其值为大于2的整数。1要分配给操作系统启动后(用于协助操作系统)首个进程,因此用户进程无法得到ID值1。接下来观察Linux中正在运行的进程。
ps au
运行结果:
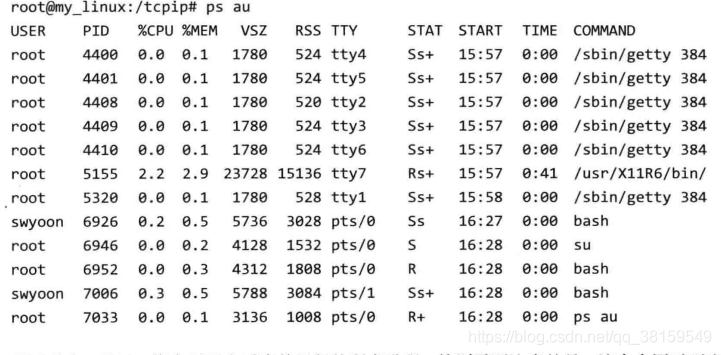
可以看出,通过ps指令 可以查看当前运行的所有进程。该命令同时列出了PID(进程ID),另外,上述示例通过指定a和u参数列出了所有进程详细信息。
1.5 通过调用fork函数创建进程
创建进程的方式很多,此处只介绍用于创建多进程服务端的 fork 函数。
#include <unistd.h>
pid_t fork(void);
// 成功时返回进程ID,失败时返回 -1
fork函数将创建调用的进程副本,复制正在运行的、调用fork函数的进程。两个进程都将执行fork函数调用后的语句(准确地说是在fork函数返回后)。但因为通过同一个进程、复制相同的内存空间,之后的程序流要根据fork函数的返回值加以区分。
- 父进程:fork函数返回子进程ID。
- 子进程:fork函数返回0。
“父进程”指的是原进程,即调用fork函数的主体; “子进程”是通过父进程调用fork函数复制出的进程。
下面是调用fork函数后的程序运行流程。
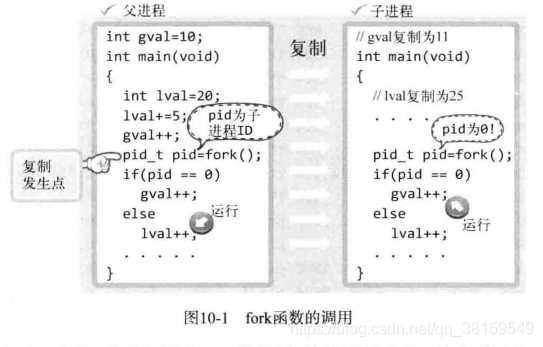
从图中可以看出,父进程调用 fork 函数的同时复制出子进程,并分别得到 fork 函数的返回值。但复制前,父进程将全局变量 gval 增加到 11,将局部变量 lval 的值增加到 25,因此在这种状态下完成进程复制。复制完成后根据 fork 函数的返回类型区分父子进程。父进程的 lval 的值增加 1 ,但这不会影响子进程的 lval 值。同样子进程将 gval 的值增加 1 也不会影响到父进程的 gval 。因为 fork 函数调用后分成了完全不同的进程,只是二者共享同一段代码而已。接下来给出示例验证之前的内容。
示例代码: fork.c
#include <stdio.h>
#include <unistd.h>
int gval = 10;
int main(int argc, char *argv[])
{
pid_t pid;
int lval = 20;
gval++, lval += 5;
pid = fork();
if (pid == 0)
gval += 2, lval += 2;
else
gval -= 2, lval -= 2;
if (pid == 0)
printf("Child Proc: [%d,%d] \n", gval, lval);
else
printf("Parent Proc: [%d,%d] \n", gval, lval);
return 0;
}
编译运行:
gcc fork.c -o fork
./fork
运行结果:

可以看出,当执行了 fork 函数之后,此后就相当于有了两个程序在执行代码,对于父进程来说,fork 函数返回的是子进程的ID,对于子进程来说,fork 函数返回 0。所以这两个变量,父进程进行了 +2 操作 ,而子进程进行了 -2 操作,所以结果是这样。
10.2 进程和僵尸进程
如果进程未销毁,它们将变成僵尸进程。
2.1 僵尸进程
进程完成工作后(执行完main函数中的程序后)应被销毁,但有时这些进程变成僵尸进程,占用系统中的重要资源。这种状态下的进程称作“僵尸进程”,这也是给系统带来负担的原因之一。
2.2 产生僵尸进程的原因
利用如下两个示例展示调用fork函数产生子进程的终止方式。
- 传递参数并调用exit函数。
- main函数中执行return语句并返回值。
向exit函数传递的参数值和main函数的return语句返回的值都会传递给操作系统。而操作系统不会销毁子进程,直到把这些值传递给产生该子进程的父进程。处在这种状态下的进程就是僵尸进程。也就是说,将子进程变成僵尸进程的正是操作系统。既然如此,此僵尸进程何时被销毁呢?其实已经给出提示。
“应该向创建子进程的父进程传递子进程的eixt参数值或return语句的返回值。”
如何向父进程传递这些值呢?
操作系统不会主动把这些值传递给父进程。只如果父进程未主动要求获得子进程的结束状态值,操作系统将一直保存,并让子进程长时间处于僵尸进程状态。接下来的示例将创建僵尸进程。
示例代码: zombie.c
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
pid_t pid = fork();
if (pid == 0)
{
puts("Hi, I am a child Process");
}
else
{
printf("Child Process ID: %d \n", pid);
sleep(30);
}
if (pid == 0)
puts("End child proess");
else
puts("End parent process");
return 0;
}
编译运行:
gcc zombie.c -o zombie
./zombie
结果:

因为暂停了 30 秒,所以在这个时间内可以验证一下子进程是否为僵尸进程。
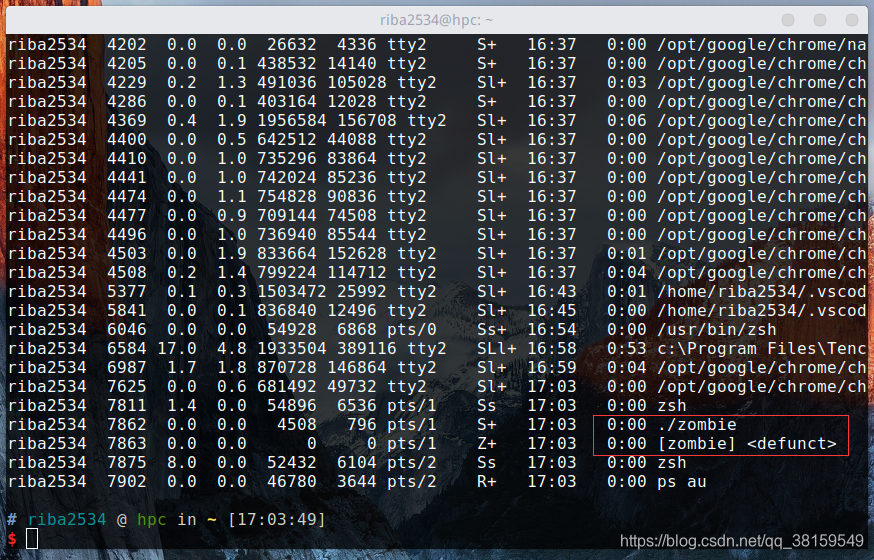
通过ps au 命令可以看出,子进程仍然存在,并没有被销毁,僵尸进程在这里显示为(Z+)。30秒后,红框里面的两个进程会同时被销毁。
利用
./zombie &可以使程序在后台运行,不用打开新的命令行窗口。(&将处罚后台处理)
2.3 销毁僵尸进程 1: 利用wait函数
有2种方法。第一种,调用如下函数。
#include <sys/wait.h>
pid_t wait(int *statloc);
/*
成功时返回终止的子进程 ID ,失败时返回 -1
*/
调用此函数时如果已有子进程终止,那么子进程终止时传递的返回值(exit函数的参数值、main函数的return返回值)将保存到该函数的参数statloc所指内存空间。但函数参数指向的单元中还包含其他信息,因此需要通过下列宏进行分离。
WIFEXITED子进程正常终止时返回“真”(true)。WEXITSTATUS返回子进程的返回值。
也就是说,向wait函数传递变量status的地址时,调用wait函数后应编写如下代码。
if (WIFEXITED(status))
{
puts("Normal termination");
printf("Child pass num: %d", WEXITSTATUS(status));
}
根据上述内容编写示例
示例代码:wiat.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc, char *argv[])
{
int status;
pid_t pid = fork(); //这里的子进程将在第13行通过 return 语句终止
if (pid == 0)
{
return 3;
}
else
{
printf("Child PID: %d \n", pid);
pid = fork(); //这里的子进程将在 21 行通过 exit() 函数终止
if (pid == 0)
{
exit(7);
}
else
{
printf("Child PID: %d \n", pid);
wait(&status); //之间终止的子进程相关信息将被保存到 status 中,同时相关子进程被完全销毁
if (WIFEXITED(status)) //通过 WIFEXITED 来验证子进程是否正常终止。如果正常终止,则调用 WEXITSTATUS 宏输出子进程返回值
printf("Child send one: %d \n", WEXITSTATUS(status));
wait(&status); //因为之前创建了两个进程,所以再次调用 wait 函数和宏
if (WIFEXITED(status))
printf("Child send two: %d \n", WEXITSTATUS(status));
sleep(30);
}
}
return 0;
}
编译运行:
gcc wait.c -o wait
./wait
结果:

此时,系统中并没有上述 PID 对应的进程,这是因为调用了 wait 函数,完全销毁了该子进程。另外两个子进程返回时返回的 3 和 7 传递到了父进程。
这就是通过 wait 函数消灭僵尸进程的方法, 调用 wait 函数时,如果没有已经终止的子进程,那么程序将阻塞(Blocking)直到有子进程终止,因此要谨慎调用该函数。
2.4 销毁僵尸进程2:使用waitpid函数
wait函数会引起程序阻塞,还可以考虑调用waitpid函数。这是方式僵尸进程的第二种方法,也是防止阻塞的方法。
#include<sys/wait.h>
pid_t waitpid(pid_t pid, int * statloc, int options);
/*
成功时返回终止的子进程ID 或 0 ,失败时返回 -1
pid: 等待终止的目标子进程的ID,若传 -1,则与 wait 函数相同,可以等待任意子进程终止
statloc: 与 wait 函数的 statloc 参数具有相同含义
options: 传递头文件 sys/wait.h 声明的常量 WNOHANG ,即使没有终止的子进程也不会进入阻塞状态,而是返回 0 退出函数。
*/
下面介绍调用上述函数的示例。
调用waitpid函数时,程序不会阻塞。
示例代码: waitpid.c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc, char *argv[])
{
int status;
pid_t pid = fork();
if (pid == 0)
{
sleep(15); //用 sleep 推迟子进程的执行
return 24;
}
else
{
//调用waitpid 传递参数 WNOHANG ,这样之前有没有终止的子进程则返回0
while (!waitpid(-1, &status, WNOHANG))
{
sleep(3);
puts("sleep 3 sec.");
}
if (WIFEXITED(status))
printf("Child send %d \n", WEXITSTATUS(status));
}
return 0;
}
编译运行:
gcc waitpid.c -o waitpid
./waitpid
结果:

可以看出第20行共执行了5次。另外,这也证明waitpid函数并未阻塞。
未完待续……