做这个工作的原因是因为书籍和论文给的相关架构已经过时,最明显的就是移除了Real-Time Node.
(一)What is Druid ?
Druid是一个高性能的OLAP时序分析数据库,最常用于GUI分析应用或者是需要快速聚合的高并发API后端.Druid常用领域包含:
1. 网站点击流量分析
2. 网络流量分析
3. 服务器指标存储
4.应用性能指标
5.数字营销分析
6.商业智能/ OLAP
Druid的关键特征有:
1.列式存储格式
2.可扩展的分布式系统
3.大规模的并行处理
4.实时和批量摄入
5.自愈、自平衡、易操作
6.可容错的架构(不会丢失数据)、Cloud-native
7.快速过滤的索引:Druid使用CONCISE或Roaring压缩位图索引来创建索引,这些索引可以跨多个列进行快速过滤和搜索。
8.近似算法:Druid包含各种近似的聚合计算,可以节省内存,当然也提供了精确计算
9.在摄取时自动汇总数据: 实质上就是一个预计算的过程.节省成本提高性能
(二)When should i use Druid?
1.插入速率特别快但是很少需要更新的时候
2.查询经常是聚合查询或者分组查询
3.要求查询延时在100ms ~ 数秒之间
4.数据自带时间戳属性
5.高基数数据列,并且需要快速计数和排名
(三) 架构
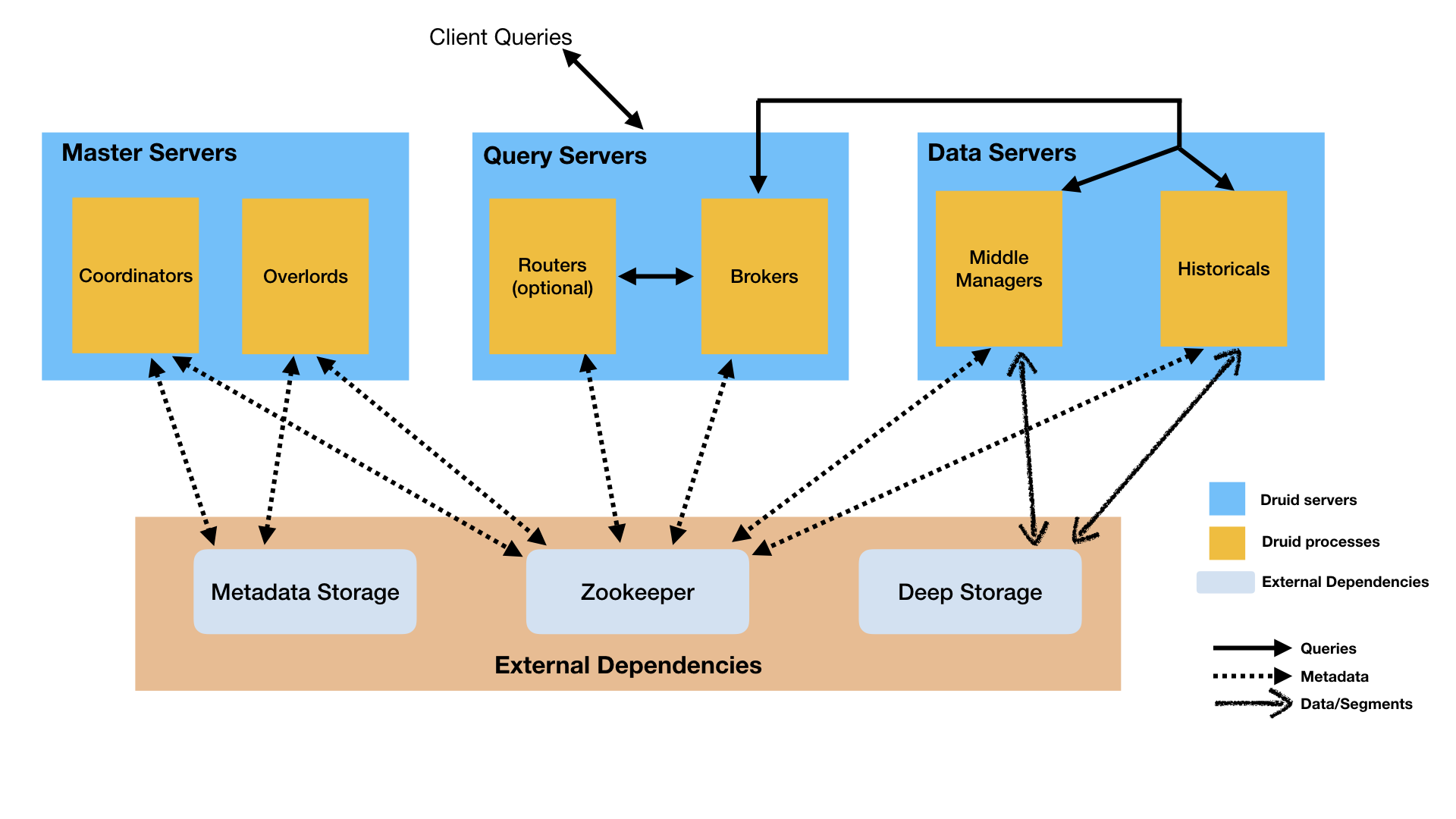
Druid是一个多进程的分布式架构,易操作,每个Druid进程类型可以独立进行配置和扩展,这样可以给集群提供最大的伸缩性,这样的设计同时也提供了增强的容错能力,一个组件的中断不会马上影响其他的组件
Druid的架构可以根据节点来进行理解
1.Historical Node 这个节点是用来查询历史数据(包含任何被提交到系统并且过了一段时间的数据流),历史结点从Deep Storage当中下载segments,并且对于查询请求它会将查询对应的segments返回回去。在历史节点当中不支持写操作
ps: segments是Druid存储数据的物理单位,按说法是可以包含数百万个row,Deep Storage可以理解为第三方存储系统,并且一般都是HDFS。
2.MiddleManager Node: 处理集群摄入进来的实时数据,它负责从外部数据源读取数据 并且发布新的Druid segments.
3.Broker Node: broker应该翻译成代理,他们会接收外界的查询并且转发到Historical Node 和 MiddleManager Node 上.
4.Coordinator Node: 对Historical Node进行监控,他们负责将Segments传给指定的服务器,并且保证segments在Historical节点间的存储是负载均衡的.
5.Overlord Node:监控MiddleManager,同时也是Druid摄入数据的控制器,它负责分配摄入任务给MiddleManagers和segment的publishing coordinating.
(segment 的状态有三种 use、publish、available)
available:是否已经被Druid服务器进程(Historical Node)所服务
publish:是否被写入了Deep storage 和 metadata store
use:是否还是个active segment,如果被重写或者drop就不是了.
6.Router: 在Druid的Brokers,Overlords、Coordinators之前提供一个统一的API网关
Druid推荐的部署计划是这样的:
1. 数据服务器用来运行Historical 进程 和 MiddleManager进程
2.查询服务器用来运行Broker 和 Router 进程(Router可选).
3.主服务器运行Coordinator 和 Overlord 进程,还可以再跑个ZK顺路。
Druid还有3个必须的外部设施
1.Deep Storage:每个Druid服务器都可以共享上面的存储文件.
2.Metadata store:一般就是用mysql来存一些元数据信息
3.ZK:内部服务发现、协调、leader选举.
The following diagram shows how queries and data flow through this architecture:
Druid数据存储在datasources里, 类似于RDBMS的table一样,每个datasource根据时间来分区,每个time range叫做chunk,一个chunk包含一个或多个segments.
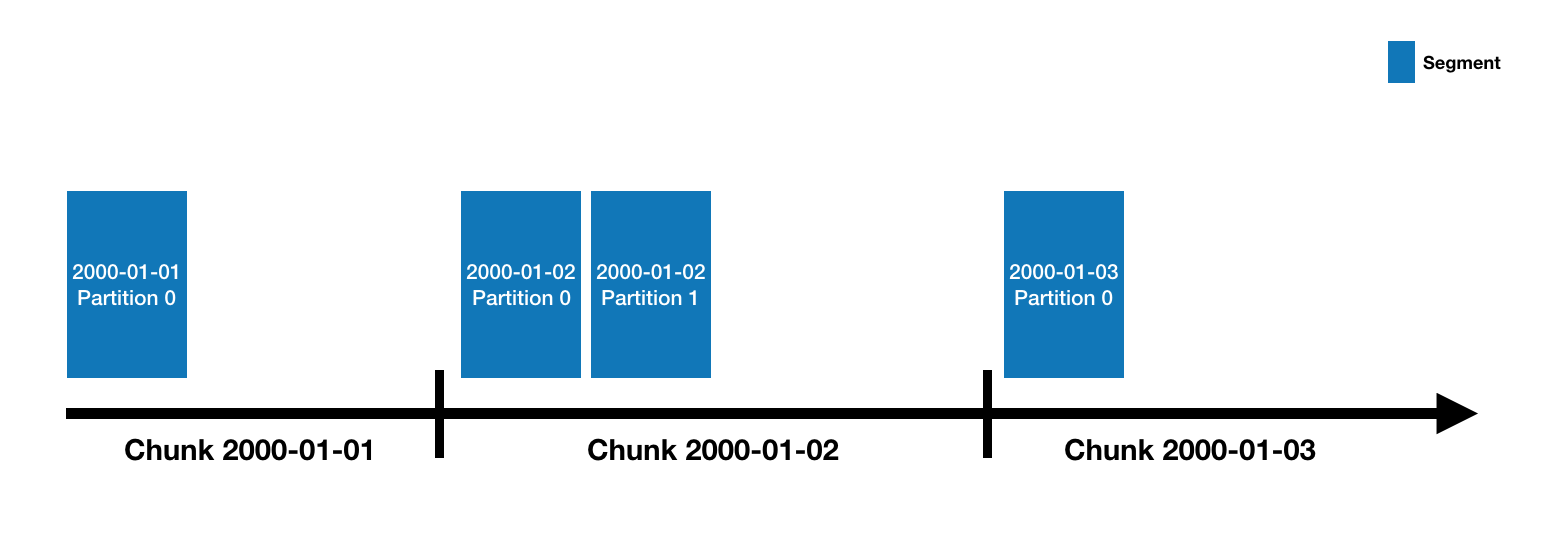
一个datasource可能只有几个segments或者多达数百万,每个segment在MiddleManager中开始被构建,此时是可变和未提交的状态,segment的构建主要利用了位图索引技术和列式压缩技术。segments会被定期的提交和发布,这个时候就已经是不可变的了,他们被写入了deep storage,并且从MiddleManagers 转移到Historical Node,关于segment的entry也会被存入到metadata store当中,entry是关于segment的元数据信息描述,包括schema、在deepstorage中的位置,Coordinator 通过这些entry来了解集群上哪些数据可用。
(四) 查询处理
查询首先进入Broker节点, 然后Broker节点会识别出哪些Segments拥有查询相关的数据,并且识别这些Segments由哪些MiddleManager和Historical节点在服务,然后发送一个子查询去相应的节点上获取结果然后返回。
.