一、LinkedBlockingQueue 与 万能的生产者-消费者模型
1. LinkedBlockingQueue实现生产者-消费者模型
由于过早地发现了<LinkedBlockingQueue>这个类,三次作业中几乎所有信息交互与协同都是围绕着阻塞队列展开的,当然好处也极为明显,完全不需要考虑wait、notify、synchronize等方法与关键字。其自带的take()与put()方法可以方便地刻画生产者与消费者模型,我们以生产者为例:
1 private void produce() { 2 Tray tray = Tray.getInstance(); 3 while (true) { 4 PersonRequest request = elevatorInput.nextPersonRequest(); 5 try { 6 tray.getPersonRequests().put(request); 7 } catch (InterruptedException e) { 8 e.printStackTrace(); 9 } 10 } 11 }
我们可以看到对LinkedBlockingQueue的读写操作是线程安全的,而且是不需要我们自行维护的,十分方便。
2. 万物皆可生产者-消费者模型
三次作业中,控制器向电梯发送指令可以用生产者-消费者模型刻画,但是当控制器需要获得电梯实时状态时,我们可能仍然需要求助于同步处理过的get和set方法,同步不当仍然会造成死锁或者程序运行缓慢,处于安(省)全(事)考量,我仍然希望可以将其划归为生产者-消费者模型。
我的基本思路为:将状态信息看作产品,状态信息的改变看作生产产品,观测端的观测结果与上一次观测结果和本次观测结果共同决定,逻辑如下:
1 static int lastState = initState; 2 int getstate() { 3 Tray tray = Tray.getStates(); 4 while (tray.getPersonRequests().peek()!= null) { 5 try { 6 lastState = tray.getStates().take(); 7 } catch (Exception e) { 8 e.printStackTrace(); 9 } 10 } 11 return lastState; 12 }
当然这种做法的弊端很明显:如果电梯状态有多个消费者,你可能需要维护多个队列,这与设计初衷并不相符。
3. 一种可能的设计思路
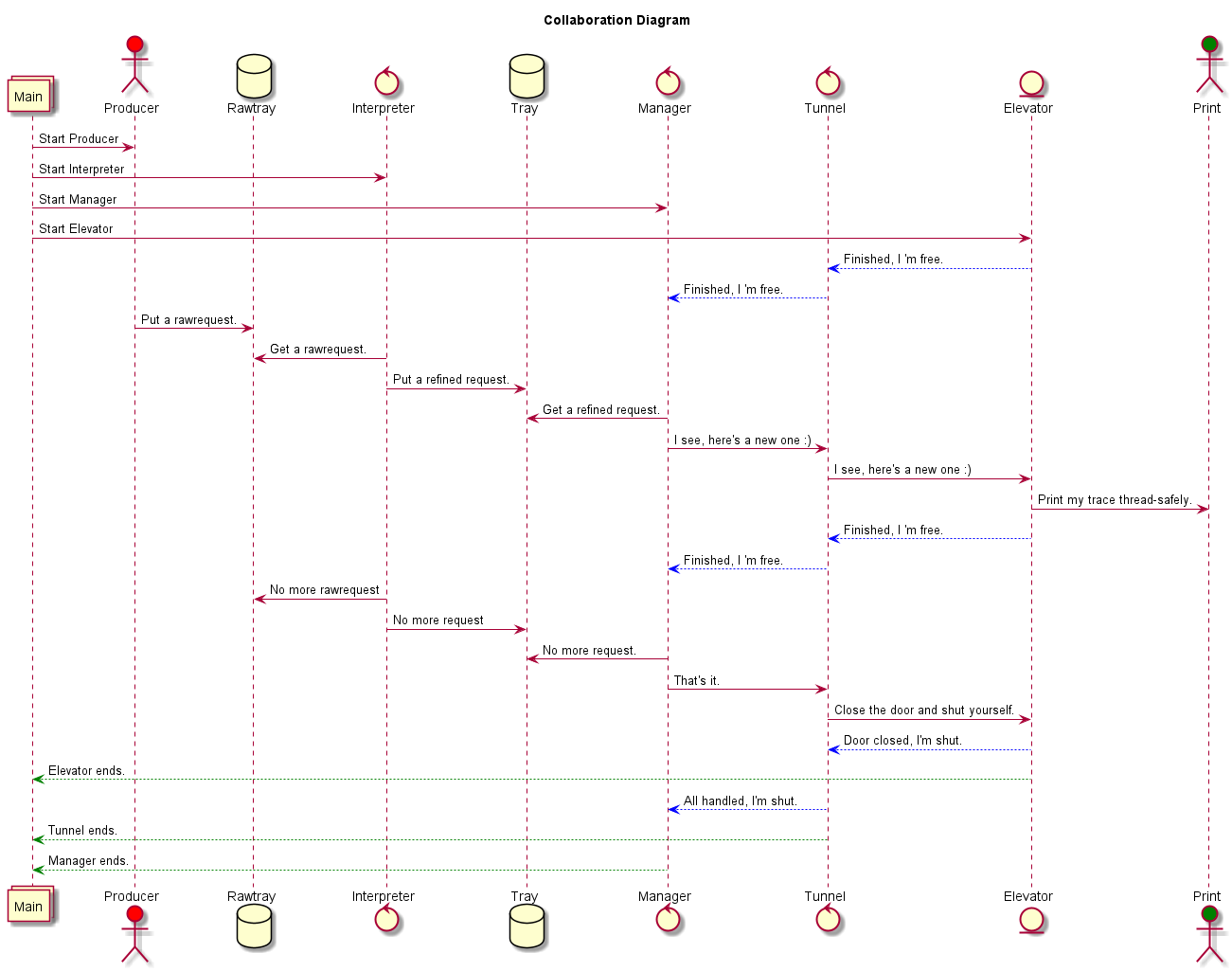
采取类流水线方式:输入、指令拆分、指令分配、指令拆解、具体实行:
二、度量模型
1. UML图
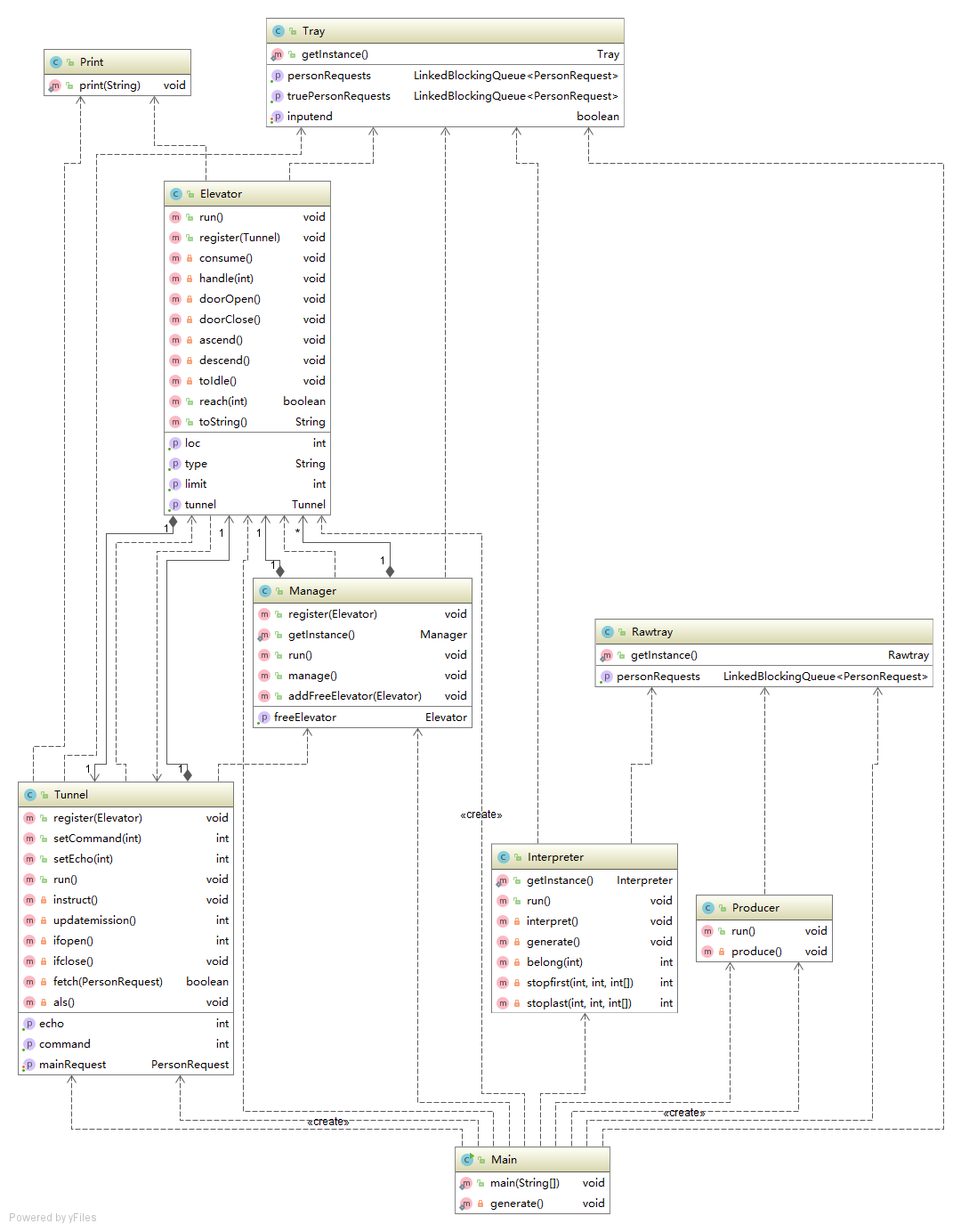
以最后一次作业为例,绘制类图:
类复杂度:
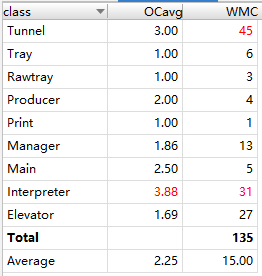
可以看出Interpreter和Tunnel中由于分别包含了顶层分配算法和ALS捎带算法复杂度较高。
类依赖图:
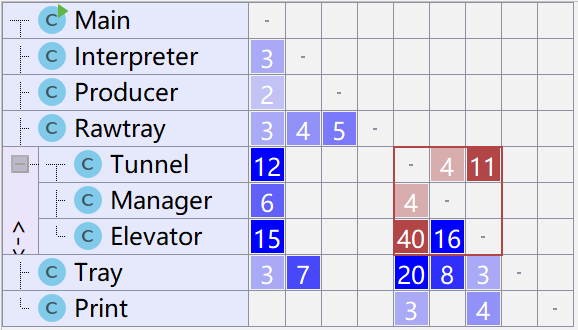
比较糟糕的是,本次设计还是出现了循环依赖的情况,原因在于Manager中同时充当了作为Free_elevator_List 的角色,致使Tunnel中需要引用Manager。其实这一问题于协作图中已经体现出来:Manager 和 Tunnel之间、Tunnel 和 Elevator之间没有托盘类。
2. 设计原则检查
1) SRP 原则 : 每一个类职责明确。这一点上整体做得不错,缺点上面已经提到,即有三个类没有完全将控制职责和存储职责剥离干净。
2) OCP 原则 : 电梯类由于在本设计中只能执行上、下、开、关等操作,三次作业中无需重构。然而承载调度算法的调度类却由于各次调度复杂性差距过大而被迫重构。
3) LSP 原则 : 本次作业对于不同类型电梯仍然使用了硬编码方式,没有利用继承。
4) ISP 原则 : 本次作业除了使用了Runnable结构之外没有自行设计接口。
5) DIP 原则 : 消息队列的设计最大化的满足了依赖导致原则,原因很简单,消息队列的写入与读写方法的单一性可以看作抽象接口,使得类与类之间耦合性降到最低。
三. Bug分析
关于自己的bug分析源于第三次作业翻车之后,一段鲜能跑到的程序段出现了致命的bug。反思发现测试时并没有做到覆盖性测试,同时最基础的单元测试也由于使用了python语言而使得没有发现表达上的漏洞。这也提醒大家做单元测试时一定要用源代码,不可以用其他自以为逻辑等价的程序代替。bug发生之后学习了关于单元测试和代码覆盖率查看相关方法,发现很多bug其实本应避免。
很遗憾,本单元作业并没有成功帮助同学发现自己的bug【手动滑稽】
四. 感想
多线程编程能力可以算是区分信息专业和非信息专业同学编程能力的一个重要方面,【果然很难】,继续加油吧。