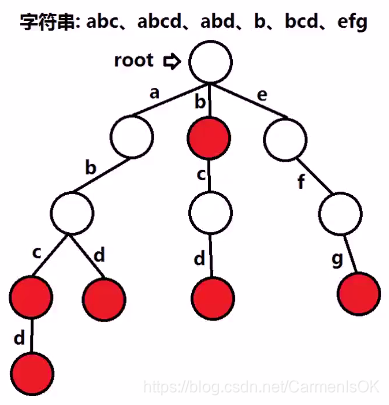
Trie树(字典树)概述
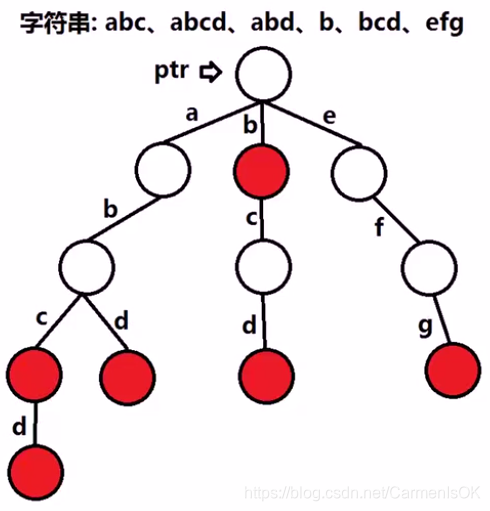
- trie树,又称字典树或前缀树,是一种有序的、用于统计、排序和存储字符串的数据结构,它与二叉查找树不同,关键字不是直接保存在结点中,而是由结点在书中的位置决定。
- 一个结点的所有子孙都有相同的前缀,也就是这个结点对应的字符串,而根结点对应空字符串。一般情况下,不是所有的结点都有对应的值,只有叶子结点和部分内部结点所对应的键才有相关的值。
- trie树的最大优点是利用字符串的公共前缀来减少存储空间与查询时间,从而最大限度地减少无谓的字符串比较,是非常高效的字符串查找数据结构。
#define TRIE_MAX_CHAR_NUM 26
struct TrieNode{
TrieNode *child[TRIE_MAX_CHAR_NUM];
bool is_end;
TrieNode():is_end(false){
for(int i=0;i<TRIE_MAX_CHAR_NUM;i++){
child[i]=0;
}
}
};
//前序遍历
void preorder_trie(TrieNode *node,int layer){
for(int i=0;i<TRIE_MAX_CHAR_NUM;i++){
if(node->child[i]!=0){
for(int j=0;j<layer;j++){
printf("---");
}
printf("%c",i+'a');
if(node->child[i].is_end==true){
printf(“(end)”);
}
printf("\n");
preorder_trie(node->child[i],layer+1);
}
}
}
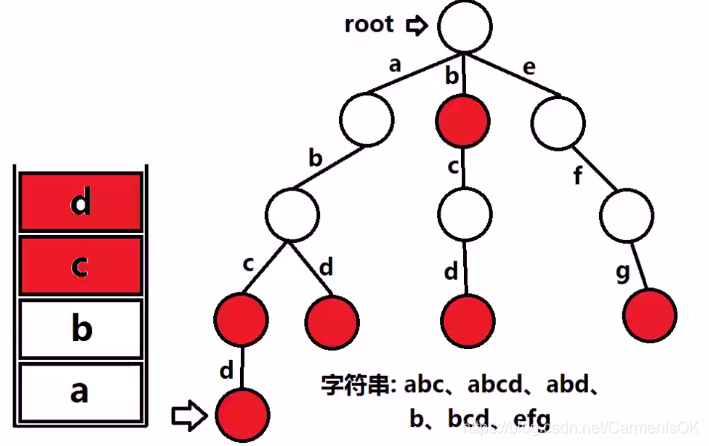
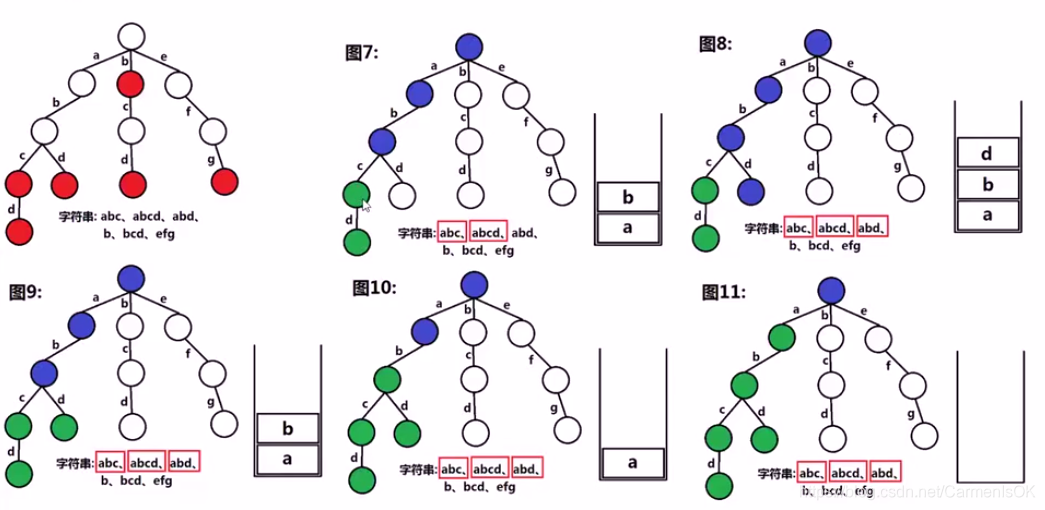
Trie树获取全部单词
深度搜索trie树,对于正在搜索的结点node:
遍历该结点26个孩子指针child[i](‘a’-‘z’),如果指针不空:
将该child[i]对应的字符(i+‘a’),push进入栈中,如果该孩子指针标记的is_end为真(说明这个位置是一个单词):
从栈底到栈顶对栈进行遍历,生成字符串,将它保存到结果数组中

void get_all_word_from_trie(TrieNode *node,string &word,vector<string>&word_list){
for(int i=0;i<TRIE_MAX_CHAR_NUM;i++){
if(node->child[i]!=0){
word.push_back(i-'a');
if(node->child[i]->is_end){
word_list.push_back(word);
}
get_all_word_from_trie(node->child[i],word,word_list);
word.erase(word.length()-1,1);
}
}
}
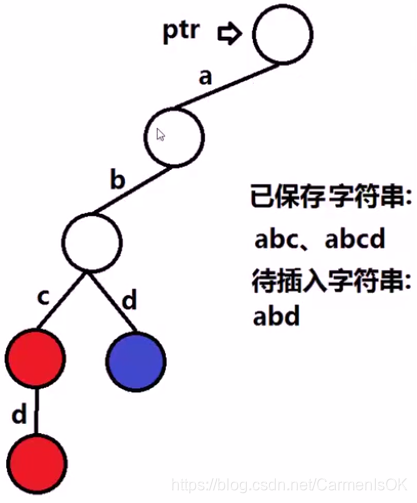
Trie树的单词插入
使用ptr指针指向root
逐个遍历待插入的字符串中的各个字符:
计算下标pos=正在遍历字符-‘a’
如果ptr指向的结点的第pos个孩子为假:
创建该结点的第pos个孩子
ptr指向该结点的第pos个孩子
标记ptr指向的结点is_end为true
class TrieTree{
public:
TrieTree(){}
~TrieTree(){
for(int i=0;i<_node_vec.size();i++){
delete _node_vec[i];
}
}
void insert(const char *word){
TrieNode *ptr=&_root;
while(*word){
int pos=*word-'a';
if(ptr->child[pos]==0){
ptr->child[pos]=new_node();
}
ptr=ptr->child[pos];
word++;
}
ptr->is_end=true;
}
private:
TrieNode *new_node(){
TrieNode *node=new TrieNode();
_node_vec.push_back(node);
return node;
}
vector<TrieNode *> _node_vec;
/*便于析构比较复杂的数据结构,比如树、图,析构时需要前序还是后序析构?相当复杂*/
TrieNode _root;
};
Trie树的单词搜索
使用ptr指针指向root
逐个遍历待插入的字符串中的各个字符:
计算下标pos=正在遍历字符-‘a’
如果ptr指向的结点的第pos个孩子为假:
返回假
ptr指向该结点的第pos个孩子
标记ptr指向的结点is_end
bool search(const char* word){
TrieNode *ptr= &_root;
while(*word){
int pos=*word-'a';
if(!ptr->child[pos]){
return false;
}
ptr=ptr->child[pos];
word++;;
}
return ptr->is_end;
}
Trie树的前缀查询
通常以该前缀开始有哪些单词。
该代码段只实现是否存在该前缀开始的单词。
bool startsWith(const char *prefix){
TrieNode *ptr=&_root;
while(*prefix){
int pos=*prefix-'a';
if(!ptr->child[pos]){
return false;
}
ptr=ptr->child[pos];
prefix++;
}
return true;
}
- 实现 Trie (前缀树)
实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。
示例:
Trie trie = new Trie();
trie.insert(“apple”);
trie.search(“apple”); // 返回 true
trie.search(“app”); // 返回 false
trie.startsWith(“app”); // 返回 true
trie.insert(“app”);
trie.search(“app”); // 返回 true
说明:
你可以假设所有的输入都是由小写字母 a-z 构成的。
保证所有输入均为非空字符串。
#define TRIE_MAX_CHAR_NUM 26
struct TrieNode{
TrieNode *child[TRIE_MAX_CHAR_NUM];
bool is_end;
TrieNode():is_end(false){
for(int i=0;i<TRIE_MAX_CHAR_NUM;i++){
child[i]=0;
}
}
};
class TrieTree{
public:
TrieTree(){}
~TrieTree(){
for(int i=0;i<_node_vec.size();i++){
delete _node_vec[i];
}
}
void insert(const char *word){
TrieNode *ptr=&_root;
while(*word){
int pos=*word-'a';
if(ptr->child[pos]==0){
ptr->child[pos]=new_node();
}
ptr=ptr->child[pos];
word++;
}
ptr->is_end=true;
}
bool search(const char* word){
TrieNode *ptr= &_root;
while(*word){
int pos=*word-'a';
if(!ptr->child[pos]){
return false;
}
ptr=ptr->child[pos];
word++;;
}
return ptr->is_end;
}
bool startsWith(const char *prefix){
TrieNode *ptr=&_root;
while(*prefix){
int pos=*prefix-'a';
if(!ptr->child[pos]){
return false;
}
ptr=ptr->child[pos];
prefix++;
}
return true;
}
private:
TrieNode *new_node(){
TrieNode *node=new TrieNode();
_node_vec.push_back(node);
return node;
}
vector<TrieNode *> _node_vec;
TrieNode _root;
};
class Trie {
public:
/** Initialize your data structure here. */
Trie() {
}
/** Inserts a word into the trie. */
void insert(string word) {
_trie_tree.insert(word.c_str());
}
/** Returns if the word is in the trie. */
bool search(string word) {
return _trie_tree.search(word.c_str());
}
/** Returns if there is any word in the trie that starts with the given prefix. */
bool startsWith(string prefix) {
return _trie_tree.startsWith(prefix.c_str());
}
private:
TrieTree _trie_tree;
};
/**
* Your Trie object will be instantiated and called as such:
* Trie* obj = new Trie();
* obj->insert(word);
* bool param_2 = obj->search(word);
* bool param_3 = obj->startsWith(prefix);
*/
- 添加与搜索单词 - 数据结构设计
设计一个支持以下两种操作的数据结构:
void addWord(word)
bool search(word)
search(word) 可以搜索文字或正则表达式字符串,字符串只包含字母 . 或 a-z 。 . 可以表示任何一个字母。
示例:
addWord(“bad”)
addWord(“dad”)
addWord(“mad”)
search(“pad”) -> false
search(“bad”) -> true
search(".ad") -> true
search(“b…”) -> true
说明:
你可以假设所有单词都是由小写字母 a-z 组成的。


#define TRIE_MAX_CHAR_NUM 26
struct TrieNode{
TrieNode *child[TRIE_MAX_CHAR_NUM];
bool is_end;
TrieNode():is_end(false){
for(int i=0;i<TRIE_MAX_CHAR_NUM;i++){
child[i]=0;
}
}
};
class TrieTree{
public:
TrieTree(){}
~TrieTree(){
for(int i=0;i<_node_vec.size();i++){
delete _node_vec[i];
}
}
void insert(const char *word){
TrieNode *ptr=&_root;
while(*word){
int pos=*word-'a';
if(ptr->child[pos]==0){
ptr->child[pos]=new_node();
}
ptr=ptr->child[pos];
word++;
}
ptr->is_end=true;
}
TrieNode *root(){
return &_root;
}
private:
TrieNode *new_node(){
TrieNode *node=new TrieNode();
_node_vec.push_back(node);
return node;
}
vector<TrieNode *> _node_vec;
TrieNode _root;
};
class WordDictionary {
public:
/** Initialize your data structure here. */
WordDictionary() {
}
/** Adds a word into the data structure. */
void addWord(string word) {
_trie_tree.insert(word.c_str());
}
/** Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter. */
bool search(string word) {
return search_trie(_trie_tree.root(),word.c_str());
}
bool search_trie(TrieNode *node,const char* word){
if(*word=='\0'){
return node->is_end;
}
if(*word=='.'){
for(int i=0;i<TRIE_MAX_CHAR_NUM;i++){
if(node->child[i]
&&search_trie(node->child[i],word+1))
return true;
}
}
else{
int pos=*word-'a';
if(node->child[pos]
&&search_trie(node->child[pos],word+1)){
return true;
}
}
return false;
}
private:
TrieTree _trie_tree;
};
/**
* Your WordDictionary object will be instantiated and called as such:
* WordDictionary* obj = new WordDictionary();
* obj->addWord(word);
* bool param_2 = obj->search(word);
*/
- 朋友圈
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
示例 1:
输入:
[[1,1,0],
[1,1,0],
[0,0,1]]
输出: 2
说明:已知学生0和学生1互为朋友,他们在一个朋友圈。
第2个学生自己在一个朋友圈。所以返回2。
示例 2:
输入:
[[1,1,0],
[1,1,1],
[0,1,1]]
输出: 1
说明:已知学生0和学生1互为朋友,学生1和学生2互为朋友,所以学生0和学生2也是朋友,所以他们三个在一个朋友圈,返回1。
注意:
N 在[1,200]的范围内。
对于所有学生,有M[i][i] = 1。
如果有M[i][j] = 1,则有M[j][i] = 1。
方法1:图的深度优先搜索
void DFS_graph(int u,vector<vector<int>> &graph,vector<int>& visit){
visit[u]=1;
for(int i=0;i<graph[u].size();i++){
if(visit[i]==0&&graph[u][i]==1){
DFS_graph(i,graph,visit);
}
}
}
class Solution {
public:
int findCircleNum(vector<vector<int>>& M) {
vector<int> visit(M.size(),0);
int count=0;
for(int i=0;i<M.size();i++){//邻接矩阵
if(visit[i]==0){
DFS_graph(i,M,visit);
count++;
}
}
return count;
}
};
方法2:并查集概述




int find(int p){
while(p!=_id[p]){//当找到一个根和自己的值相等的,则是元素的总根
_id[p]=_id[_id[p]]//压缩过程
p=_id[p];
}
return p;
}


class DisjointSet{
public:
DisjointSet(int n){
for(int i=0;i<n;i++){
_id.push_back(i);
_size.push_back(1);
}
_count=n;
}
int find(int p){
while(p!=_id[p]){//当找到一个根和自己的值相等的,则是元素的总根
_id[p]=_id[_id[p]];//压缩过程
p=_id[p];
}
return p;
}
void union_(int p,int q){
int i=find(p);
int j=find(q);
if(i==j){
return ;
}
if(_size[i]<_size[j]){
_size[j]+=_size[i];
_id[i]=j;
}
else{
_size[i]+=_size[j];
_id[j]=i;
}
_count--;
}
int count(){return _count;}
private:
vector<int> _id;
vector<int> _size;
int _count;
};
class Solution {
public:
int findCircleNum(vector<vector<int>>& M) {
DisjointSet disjoint_set(M.size());
for(int i=0;i<M.size();i++){
for(int j=i+1;j<M.size();j++){
if(M[i][j]){
disjoint_set.union_(i,j);
}
}
}
return disjoint_set.count();
}
};
- 区域和检索 - 数组可修改
给定一个整数数组 nums,求出数组从索引 i 到 j (i ≤ j) 范围内元素的总和,包含 i, j 两点。
update(i, val) 函数可以通过将下标为 i 的数值更新为 val,从而对数列进行修改。
示例:
Given nums = [1, 3, 5]
sumRange(0, 2) -> 9
update(1, 2)
sumRange(0, 2) -> 8
说明:
数组仅可以在 update 函数下进行修改。
你可以假设 update 函数与 sumRange 函数的调用次数是均匀分布的。
线段树
其中,15=0+1+2+3+4+5;3=0+1+3;12=3+4+5;…



void build_segment_tree(vector<int> &value,vector<int> &nums,
int pos,int left,int right){
if(left==right){
value[pos]=nums[left];
return;
}
int mid=(right+left)/2;
build_segment_tree(value,nums,2*pos+1,left,mid);
build_segment_tree(value,nums,2*pos+2,mid+1,right);
value[pos]=value[pos*2+1]+value[pos*2+2];
}

int sum_range_segment_tree(vector<int>&value,int pos,int left,int right,
int qleft,int qright){
if(qright<left||qleft>right){
return 0;
}
if(qleft<=left&&qright>=right){
return value[pos];
}
int mid=(left+right)/2;
return sum_range_segment_tree(value,pos*2+1,left,mid,qleft,qright)
+sum_range_segment_tree(value,pos*2+2,mid+1,right,qleft,qright);
}

void update_segment_tree(vector<int>&value,int pos,int left,int right,
int index,int new_value){
if(left==right&&left==index){
value[pos]=new_value;
return;
}
int mid=(left+right)/2;
if(index<=mid){
update_segment_tree(value,pos*2+1,left,mid,index,new_value);
}
else{
update_segment_tree(value,pos*2+2,mid+1,right,index,new_value);
}
value[pos]=value[pos*2+1]+value[pos*2+2];
}
void build_segment_tree(vector<int> &value,vector<int> &nums,
int pos,int left,int right){
if(left==right){
value[pos]=nums[left];
return;
}
int mid=(right+left)/2;
build_segment_tree(value,nums,2*pos+1,left,mid);
build_segment_tree(value,nums,2*pos+2,mid+1,right);
value[pos]=value[pos*2+1]+value[pos*2+2];
}
int sum_range_segment_tree(vector<int>&value,int pos,int left,int right,
int qleft,int qright){
if(qright<left||qleft>right){
return 0;
}
if(qleft<=left&&qright>=right){
return value[pos];
}
int mid=(left+right)/2;
return sum_range_segment_tree(value,pos*2+1,left,mid,qleft,qright)
+sum_range_segment_tree(value,pos*2+2,mid+1,right,qleft,qright);
}
void update_segment_tree(vector<int>&value,int pos,int left,int right,
int index,int new_value){
if(left==right&&left==index){
value[pos]=new_value;
return;
}
int mid=(left+right)/2;
if(index<=mid){
update_segment_tree(value,pos*2+1,left,mid,index,new_value);
}
else{
update_segment_tree(value,pos*2+2,mid+1,right,index,new_value);
}
value[pos]=value[pos*2+1]+value[pos*2+2];
}
class NumArray {
public:
NumArray(vector<int>& nums) {
if(nums.size()==0){
return;
}
int n=nums.size()*4;//一般线段树数组大小是原数组大小长度的四倍
for(int i=0;i<n;i++){
_value.push_back(0);
}
build_segment_tree(_value,nums,0,0,nums.size()-1);
_right_end=nums.size()-1;//线段的右端点
}
void update(int i, int val) {
update_segment_tree(_value,0,0,_right_end,i,val);
}
int sumRange(int i, int j) {
return sum_range_segment_tree(_value,0,0,_right_end,i,j);
}
private:
vector<int> _value;
int _right_end;
};
/**
* Your NumArray object will be instantiated and called as such:
* NumArray* obj = new NumArray(nums);
* obj->update(i,val);
* int param_2 = obj->sumRange(i,j);
*/