论文分享第四期-2019.04.16
Residual Attention Network for Image Classification,CVPR 2017,RAN
核心:将注意力机制与ResNet结合,用于图像分类。论文设计了一个注意力模块(Attention Module),通过级联该模块(即增加模型深度),网络可以学到细粒度的特征图谱(fined-grained feature maps),因为随着层数的加深,来自不同模块的注意力感知特征可以自适应地改变。
除了注意机制带来的更具判别性的特征,RAN还具有其他特性:
- 增加注意模块数量可以提升性能,因为能广泛地捕捉不同类型的注意力
- 以端到端的训练方式与最先进的深层网络结构相结合。显著减少了计算
论文将自己的贡献总结为三点:
- 堆叠的网络结构(stacked network structure):将多个注意力模块级联,处在不同网络深度的注意力模块捕捉不同类型的注意力
- 注意力残差训练(attention residual learning):直接堆叠注意力模块(没有加和的操作)会导致模型性能显著下降。因此提出类似于残差学习的训练方法,注意力模块的输出加上输入的特征,使模型学到具有残差性质的注意力
- 自底向上-自顶向下的前馈注意力(bottom-up top-down):即编码-解码的结构得到注意力图谱
注意力模块的网络结构(Attention Module):
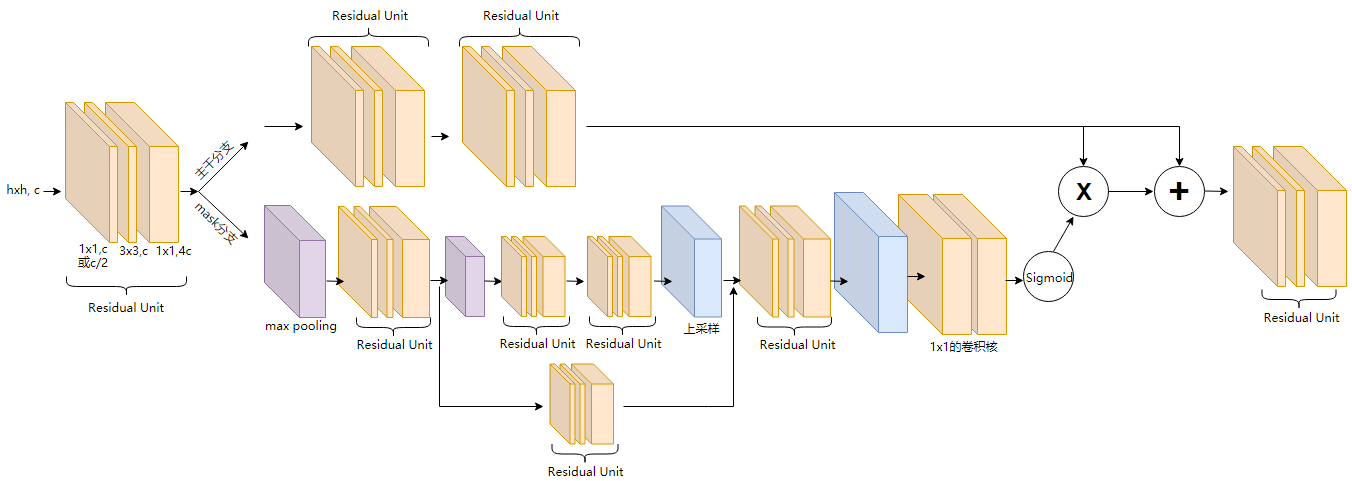
如上图所示,是RAN网络的注意里模块的结构。先通过一个残差单元,然后分为主干分支(trunk branch)和掩码分支(mask branch),再将两个分支的输出依通道逐像素点乘,在与主干分支的输出依通道逐像素求和,最后通过一个残差单元,即得到该深度处的、结合了注意力机制的特征图谱。输出公式如公式(1)。
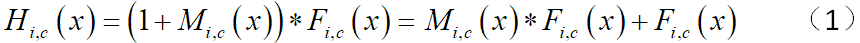
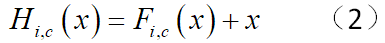
对于论文中自述的贡献2,将此公式与ResNet中残差训练的公式对比(公式2),ResNet中网络学到的是残差函数Fi,c(x),而RAN中的两个分支都是需要学习的,Fi,c(x)是主干分支的输出特征图谱;代表残差概念的是两个分支输出的点乘,也就是两个分支合起来的作用相当于ResNet中的残差函数,所以但就mask分支得到的并不是残差,而是一种掩码。但是mask分支输出的掩码,也有其作用,论文中总结为两点:
- 具有前向推理中的特征选择功能;
- 在反向传播时还具有梯度更新滤波的作用。掩码分支(mask branch)可以阻止错误的梯度来更新主干分支(trunk branch),使模型对噪声标签具有更好的鲁棒性。
论文中所提到的直接堆叠,应该是指没有上图中加和的操作。简单地直接堆叠注意模块会使性能显著下降,论文中解释的原因:1.在0和1之间不断与mask进行点积,会使更深层的特征数值降低。2.soft mask可能会破坏主干分支的好的特性,如残差单元的恒等映射。
对于论文中自述的贡献3,即mask分支中的编码-解码的结构,在图像分割的全卷积网络FCN、人体姿态估计的沙漏网络中都有体现,这种结构现在看来已经很普遍了,不算是很大的创新点。在本论文中还引入了跳转连接,但是该跳转连接经过了一个残差单元,这在其他一些结构中是没有的。处在网络浅层的注意力模型中,跳转连接较多,随着网络加深,这种跳转连接逐渐减少直至没有。
RAN网络的整体结构(Residual Attention Network):

上述整体结构对应于自述贡献1,处在不同网络深度中的注意力模型,会捕捉不同类型的注意力。
现在就有一个最核心的疑问:这样的卷积网络结构为什么就具有捕捉注意力的能力呢?到底什么是注意力机制,设计带有注意力机制的网络结构,其应该具有什么样的特点?或是说共性