准备操作数据
CREATE DATABASE mydb01;
USE mydb01;
CREATE TABLE mydb01.stu(
sid CHAR(6) COMMENT '学生学号',
sname CHAR(50) COMMENT '学生的名字',
age INT COMMENT '学生年龄',
grender VARCHAR(20) COMMENT'学生性别'
);
#插入数据
INSERT INTO stu VALUES('S_1001', 'liuYi', 35, 'male');
INSERT INTO stu VALUES('S_1002', 'chenEr', 15, 'female');
INSERT INTO stu VALUES('S_1003', 'zhangSan', 95, 'male');
INSERT INTO stu VALUES('S_1004', 'liSi', 65, 'female');
INSERT INTO stu VALUES('S_1005', 'wangWu', 55, 'male');
INSERT INTO stu VALUES('S_1006', 'zhaoLiu', 75, 'female');
INSERT INTO stu VALUES('S_1007', 'sunQi', 25, 'male');
INSERT INTO stu VALUES('S_1008', 'zhouBa', 45, 'female');
INSERT INTO stu VALUES('S_1009', 'wuJiu', 85, 'male');
INSERT INTO stu VALUES('S_1010', 'zhengShi', 5, 'female');
INSERT INTO stu VALUES('S_1011', 'xxx', NULL, NULL);
模糊查询
查询包含某个关键字的字段的方法
通过通配符来查询
通配符
_ :任意一个字符
%:任意0~n个字符
姓x的:“x%”
姓x的,并且2个字:“x_”
查询姓名有5个字符构成的学生记录
#查询姓名有5个字符构成的学生记录
SELECT
*
FROM
stu
WHERE
sname LIKE '_____';
查询姓名有5个字符组成,其中第五个字母是‘i’的记录
#查询姓名有5个字符组成,其中第五个字母是‘i’的记录;
SELECT
*
FROM
stu
WHERE
sname LIKE '____i';查询姓名以“z”开头的学生记录
#查询姓名以“z”开头的学生记录
SELECT
*
FROM
stu
WHERE
sname LIKE'z%'; 查询姓名中第2个字母为‘i’的学生记录
#查询姓名中第2个字母为‘i’的学生记录
SELECT
*
FROM
stu
WHERE
sname LIKE '_i%';姓名中包含“a”字符的学生记录
SELECT
*
FROM
stu
WHERE
sname LIKE '%a%';注意:
(1)模糊查询时候,匹配第一个字符尽量不要出现通配符,会导致全表扫描。
(2)企业中,模糊查询使用场景:搜索,
比如搜索商品:搜索商品 –》商品列表(只有商品部分信息) -》商品详情
企业中,会使用搜索引擎,而不是模糊查询,会使用开发搜索引擎solr
搜索引擎的基本实现思路:

商品上架 –》建立索引:将商品信息在存储一份(只包含列表需要的数据)
搜索:查找索引
字段控制查询
准备操作数据
CREATE TABLE emp(
empno INT COMMENT '员工编号',
ename VARCHAR(50) COMMENT '员工名字',
job VARCHAR(50) COMMENT '职位',
mgr INT COMMENT '领导 编号',
hiredate DATE COMMENT '入职日期',
sal DECIMAL(7,2) COMMENT '月薪',
comm DECIMAL(7,2) COMMENT '奖金',
deptno INT COMMENT '部门编号'
);
INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp VALUES(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp VALUES(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp VALUES(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp VALUES(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp VALUES(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp VALUES(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp VALUES(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp VALUES(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
CREATE TABLE dept(
deptno INT COMMENT '部门编号',
dename VARCHAR(100) COMMENT '部门名称',
loc VARCHAR(50) COMMENT '部门所在地'
)
INSERT INTO dept VALUES(10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO dept VALUES(20, 'RESEARCH', 'DALLAS');
INSERT INTO dept VALUES(30, 'SALES', 'CHICAGO');
INSERT INTO dept VALUES(40, 'OPERATIONS', 'BOSTON');
去除重复记录
2行或者2行以上记录中 数据相同的去掉,
比如emp表中sal字段就存在相同的值,当查询emp中sal字段的时候,就会出现重复记录
如果需要去除重复记录,需要使用distinct。
SELECT
DISTINCT sal
FROM
emp;查看雇员的月薪与佣金之和
因为sal 和comm两列的数据类型都是数值类型,所有可以直接做加运行
但是如果2个字段中有一个不是数值类型,就会出错。
可以使用ifnull(字段值,赋的值);函数,该函数判断某列的某个值为null时,会自动为其赋值
SELECT
empno,ename,sal,comm,sal+IFNULL(comm,0)
FROM
emp;给列添加别名
SELECT
empno,ename,sal,comm,sal+IFNULL(comm,0)AS total
FROM
emp;排序 order by
order by asc|desc 升序|降序 默认为升序
查询所有学生记录,按照年龄升序排序
SELECT
*
FROM
stu
ORDER BY
age ASC;查询所有学生记录,按照年龄降序排序
SELECT
*
FROM
stu
ORDER BY
age DESC;查询所有雇员,按照月薪降序,如果月薪相同,按照编号升序排序
SELECT
*
FROM
emp
ORDER BY
sal DESC ,empno ASC;查询所有雇员,按照月薪降序,如果月薪相同,按照编号降序排序
SELECT
*
FROM
emp
ORDER BY
sal DESC ,empno DESC;聚合函数
聚合函数式用来做纵(列)向运算的函数
Count():计算指定列不为null的记录行数。
Max():计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算。
Min():计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算。
Sum():计算指定列的和,如果指定列是不是数值类型,那么计算结果为0
Avg():计算指定列的平均值,如果指定列是不是数值类型,那么计算结果为0
Count
查询emp表中记录数
SELECT
COUNT(*) AS cnt
FROM
emp;查询emp表中有佣金的个数
SELECT
COUNT(sal) AS sal_count
FROM
emp;查询emp表中,月薪大于2500的人数。
SELECT
COUNT(*) AS cnt
FROM
emp
WHERE
sal > 2500;统计月薪与佣金之和大于2500元的人数
SELECT
COUNT(*)
FROM
emp
WHERE
sal + IFNULL(comm,0) > 2500;查询有佣金的人数,以及有领导的人数
SELECT
COUNT(comm) AS count_count,
COUNT(mgr) AS mgr_count
FROM
emp;
Sum和avg
查询所有雇员月薪和
SELECT
SUM(sal) AS sal_sum
FROM
emp;
查询所有雇员月薪和,以及所有雇员佣金和
SELECT
SUM(sal) AS sal_sum,
SUM(comm) AS comm_sum
FROM
emp;
查询所有雇员薪水+佣金和
SELECT
SUM(sal + IFNULL(comm,0)) AS total
FROM
emp;统计所有员工的平均工资
SELECT
AVG(sal) AS avg_sal
FROM
emp;Max和Min
查询最高工资与最低工资
SELECT
MAX(sal),
MIN(sal)
FROM
emp;
分组查询
当需要分组查询的时候,需要使用group by语句,
例如:查询每个部门的工资和,说明需要使用部门来分组
关键字:每,各个
查询每个部门 的部门编号和每个部门的工资和
SELECT
deptno,SUM(sal)AS sal_sum
FROM
emp
GROUP BY
deptno;
查询每个部门的部门编号以及每个部分的人数
SELECT
deptno,COUNT(*) AS dept_num
FROM
emp
GROUP BY
deptno;
查询每个部门的部门编号以及每个部门工资大于1500的人数。
SELECT
deptno,COUNT(*) AS COUNT
FROM
emp
WHERE
sal >1500
GROUP BY
deptno;Having 过滤
SELECT
deptno,SUM(sal) AS sal_sum
FROM
emp
GROUP BY
deptno
HAVING
sal_sum > 9000;注意:having与where的区别
(1)having是在分组后对数据进行过滤
where是在分组前对数据进行过滤
(2)having可以使用分组函数(聚合函数)的别名
Where 后面不能使用分组函数。
Limit
Limit用来限制查询结果的起始行,以及总行数
查询5个雇员信息,起始从0开始
SELECT
*
FROM
emp
LIMIT
0,5;查询10行,起始行从3开始
SELECT
*
FROM
emp
LIMIT
3,10;查询5条数据
SELECT
*
FROM
emp
LIMIT
5;不写开始位置则默认从0开始,即第一行
分页查询
企业中:为什么有分页查询这个功能(需求)。
用户的手机一屏只能放10条记录,加载10条就过来。
性能优化:
减少数据的加载,减少网络资源,
速度快,用户体验好。
总结
查询SQL语句编写顺序:
select … from …where …group by …having …order by … limit
查询SQL语句执行顺序:
from…where …group by …having ….select … order by …limit
数据的完整性
作用:保证用户输入的数据保存到数据库中是正确的。
确保数据的完整性 :在创建表的时候给表添加约束
完整性的分类:实体完整性,域完整性,引用完整性
实体完整性
实体:entity,就也是表中一行(一条记录)代表一个实体
实体完整性的作用:标识每一行数据不重复
约束的类型:
主键约束(primary key)
唯一约束(unique)
自动增长列(auto_increment)
主键约束(primary key)
特点:数据是唯一,且不能为空
方式一:
CREATE TABLE stu_table(
id INT PRIMARY KEY,
NAME VARCHAR(50)
);
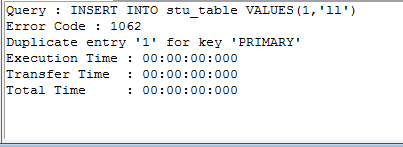
INSERT INTO stu_table VALUES(1,'ll');
INSERT INTO stu_table VALUES(1,'ll');再次插入id=1这条记录时就会出错
方式二
此种方式优势在于,可以创建联合主键
CREATE TABLE stu_table1(
id INT ,
classid INT,
NAME VARCHAR(50),
PRIMARY KEY (id,classid)
);
INSERT INTO stu_table1 VALUES(1,22,'ll');
INSERT INTO stu_table1 VALUES(1,22,'ll');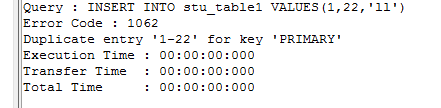
方式三:
CREATE TABLE stu_table2(
id INT ,
classid INT,
NAME VARCHAR(50)
);
ALTER TABLE stu_table2 ADD PRIMARY KEY (id);
DESC stu_table2;主键分类(个人看法)
自然主键:
该字段有意义,
身份证号码,电话号码,
代理主键:
该字段没有任何的业务意义,仅仅是为了实现功能添加的。
用户id,订单id
唯一约束(unique):
数据不能重复
CREATE TABLE stu_table3(
id INT ,
classid INT,
NAME VARCHAR(50)UNIQUE
);
INSERT INTO stu_table3 VALUES(1,22,'ll');
INSERT INTO stu_table1 VALUES(1,22,'ll');
自动增长列(auto_increment)
给主键添加自动增长的数值,该列的值自动增长(i++),列的数据类型只能是整数类型。
自动增长的列,插入数据的时候,可以不给值。
CREATE TABLE stu_table4(
id INT PRIMARY KEY AUTO_INCREMENT,
classid INT,
NAME VARCHAR(50)UNIQUE
);
INSERT INTO stu_table4(classid,NAME) VALUES(22,'ll');
INSERT INTO stu_table4 VALUES(222,22,'66');
SELECT * FROM stu_table4;