近期,有幸拜读了Hadoop起源 Google三驾马车之一,GFS这篇论文,无奈知识有限,许多内容都不甚清楚,但总归还是有一些自己的浅见,难登大雅之堂,仅作为以后深入学习的一个回顾。
说起GFS,不得不提到分布式这个概念。早期的互联网不像现在这样发达,也没有现在这样先进,设想一种情况,20年前,双十一有如今这样的火爆,访问量更是数以亿级,相当于一次大规模的DDoS攻击,15年前的服务器性能水平,在如此高强度的访问之下,恐怕撑不了多少时间就会崩溃,正是基于应对这样的情况的前提下,分布式系统,应运而生。
早先,传统的模式是采取单服务器应对这种模式的,即后台只有一台服务器来应对这些访问,那个时代互联网并没有普及到千家万户,甚至可以说是小众化产品,访问过载时,采取的方案是提升服务器的性能,大部分情况下,这种方案是有效的,但在今天,这种单一的方案早已被淘汰。取而代之的是采用多服务器联动的方式来应对高并发的场景。
而GFS,正是在分布式这个基础之上,而发展起来的。
简单而言,GFS,是大型的分布式文件系统,在传统的分布式文件系统上,提供了更多的功能,例如容错功能,可扩展功能,等等。
下面浅析它的工作原理。
首先我们将数以TB计的数据分割为许多块。
这些文件将被放到不同的物理机上面去,正如图中白色方框里面那样。
然后,我们将在众多的物理机中,选举出一台Master服务器,用来管理其他的物理机,即chunk物理机
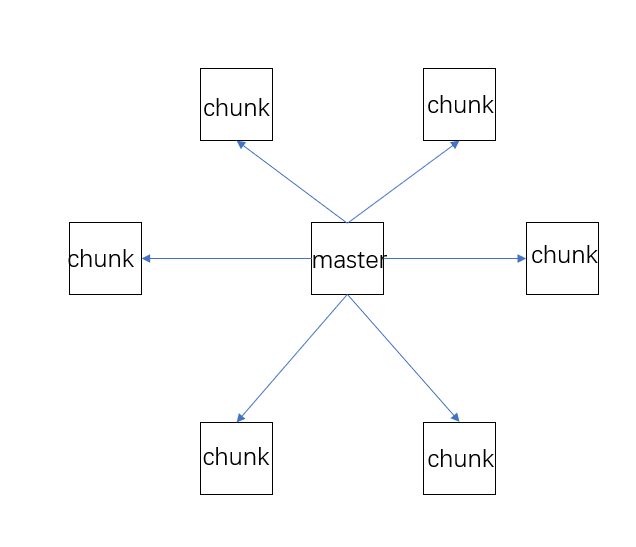
每一个chunk服务器将会赋予一个64位的全球唯一标识,用于标记一台chunk服务器。
chunk服务器的作用主要用于存放分布式的文件,而master服务器的作用主要用来管理这些chunk服务器,调用chunk服务器的资源,同时提供外部访问的接口。
高并发情况下,对于企业而言,GFS确实是一个相当不错的选择。
当然,不知如此,GFS还为后来的Hadoop奠定了夯实的基础,在大数据领域,数以亿级的数据相当常见,如果不采取必要的措施,没有一台物理机能够承受住如此高压,GFS的出现,恰好是一个解决问题的优秀方案,如果没有分布式,可能就不会出现GFS,没有GFS,也就不会有今天这个大数据技术井喷的时代。
以上,便是我对GFS这篇论文的小小看法,我自己对这边论文也没有看懂多少,都是一些个人见解,有许多错误和不足的地方,欢迎大家在评论区中指正。(另附上GFS 论文原图)
