续我的上篇博文:https://mp.csdn.net/postedit/89017772。即Hadoop单机模式已经安装部署好。
本篇博文安装的是Hadoop的伪分布模式。
一、实验环境(rhel7.3版本)
1、selinux和firewalld状态为disabled
2、各主机信息如下:
| 主机 | ip |
|---|---|
| server1(NameNode、DataNode、 Secondary Namenode) | 172.25.83.1 |
二、Hadoop伪分布模式的安装与部署
1、安装、部署Hadoop单机模式
具体步骤:https://mp.csdn.net/postedit/89017772
扫描二维码关注公众号,回复:
5933080 查看本文章

2、修改配置文件
<1>指定Namenode的地址
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim core-site.xml #在文件的最后写入下面的内容
19 <configuration>
20 <property>
21 <name>fs.defaultFS</name>
22 <value>hdfs://localhost:9000</value> #这里的localhost也可以换为172.25.83.1(因为部署的是伪分布模式,所有的节点都在一台主机上,所以写localhost,172.25.83.1都可以;但如果部署分布模式,则必须写为172.25.83.1,写成localhost会导致别的主机无法访问)
23 </property>
24 </configuration>
<2>指定Datanode地址以及hdfs保存数据的副本数量(hdfs保存数据的副本数默认是3,因为这里只有一个Datanode,所以这里设定为1)
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim slaves
172.25.83.1
[hadoop@server1 hadoop]$ vim hdfs-site.xml #在文件的最后,写入下面的内容
19 <configuration>
20 <property>
21 <name>dfs.replication</name>
22 <value>1</value> #hdfs保存数据的副本数量为1
23 </property>
24 </configuration>
3、设置ssh免密登陆(前提:安装ssh服务)
#设置server1——>server1免密的第一种方法
[hadoop@server1 hadoop]$ ssh-keygen
[hadoop@server1 hadoop]$ cd ~/.ssh/
[hadoop@server1 .ssh]$ ls
id_rsa id_rsa.pub
[hadoop@server1 .ssh]$ cp id_rsa.pub authorized_keys
[hadoop@server1 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub
#设置server1——>server1免密的第二种方法
[hadoop@server1 hadoop]$ ssh-keygen
[hadoop@server1 hadoop]$ cd ~/.ssh/
[hadoop@server1 .ssh]$ ls
id_rsa id_rsa.pub
[hadoop@server1 .ssh]$ ssh-copy-id localhost
[hadoop@server1 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts示图:验证免密登陆

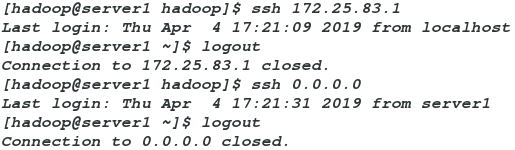
4、格式化元数据节点(Namenode)
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ ll /tmp/
total 4
drwxrwxr-x 3 hadoop hadoop 17 Apr 9 21:03 hadoop-hadoop
-rw-rw-r-- 1 hadoop hadoop 5 Apr 9 21:03 hadoop-hadoop-namenode.pid
drwxr-xr-x 2 hadoop hadoop 6 Apr 9 21:03 hsperfdata_hadoop示图:格式化后生成的文件

5、开启dfs
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
6、配置环境变量,以使得jps命令生效
[hadoop@server1 hadoop]$ vim ~/.bash_profile #在第10行本身就有的内容(PATH=$PATH:$HOME/.local/bin:$HOME/bin)后面添加:~/java/bin(或者是$HOME/java/bin)
10 PATH=$PATH:$HOME/.local/bin:$HOME/bin:~/java/bin
[hadoop@server1 hadoop]$ source ~/.bash_profile #刷新使刚刚添加的环境变量生效7、jps命令查看java进程
[hadoop@server1 hadoop]$ jps
7862 NameNode #数据节点
7974 DataNode #元数据节点
9286 Jps
8152 SecondaryNameNode #从元数据节点[hadoop@server1 hadoop]$ ps ax
7862 ? Sl 0:09 /home/hadoop/java/bin/java -Dproc_namenode -Djava.net.preferIPv4Stack=true -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dyarn.log.dir=/home/hadoop/hadoop-3.0.3/logs -Dyarn.log.file=hadoop-hadoop-namenode-server1.l
7974 ? Sl 0:07 /home/hadoop/java/bin/java -Dproc_datanode -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=ERROR,RFAS -Dyarn.log.dir=/home/hadoop/hadoop-3.0.3/logs -Dyarn.log.file=hadoop-hadoop-datanode-server1.log -Dyarn.home.dir=/home/hadoop/hadoo
8152 ? Sl 0:05 /home/hadoop/java/bin/java -Dproc_secondarynamenode -Djava.net.preferIPv4Stack=true -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dyarn.log.dir=/home/hadoop/hadoop-3.0.3/logs -Dyarn.log.file=hadoop-hadoop-secondary
- 查看9870端口是否已经打开

浏览器访问:http://172.25.83.1:9870

选择Datanodes

上面浏览器中的内容,也可以通过命令在终端中进行显示
[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -report #显示文件系统的基本数据
Configured Capacity: 18238930944 (16.99 GB)
Present Capacity: 11567726592 (10.77 GB)
DFS Remaining: 11567718400 (10.77 GB)
DFS Used: 8192 (8 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 127.0.0.1:9866 (localhost)
Hostname: server1
Decommission Status : Normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 6671204352 (6.21 GB)
DFS Remaining: 11567718400 (10.77 GB)
DFS Used%: 0.00%
DFS Remaining%: 63.42%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Tue Apr 09 21:20:19 CST 2019
Last Block Report: Tue Apr 09 21:07:14 CST 20198、进行测试:
<1>第一步:创建目录并上传input
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ ls #其中input目录和output目录是上篇博文实验的结果
bin etc include input lib libexec LICENSE.txt logs NOTICE.txt output README.txt sbin share
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls / #列出hdfs文件系统根目录下的目录和文件
[hadoop@server1 hadoop]$
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls #列出hdfs文件系统家目录(/user/hadoop)下的目录和文件。因为此时还没有建立家目录,所以会显示下面的错误
ls: `.': No such file or directory
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop #递归建立目录/user/hadoop。值的注意的是:该目录的名字必须是/user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls / #显示有刚刚建立的目录/user
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-04-09 21:47 /user
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls #因为家目录/user/hadoop中没有任何内容,所以显示为空
[hadoop@server1 hadoop]$
[hadoop@server1 hadoop]$ bin/hdfs dfs -put input/ #上传input,不指定上传的位置的话:默认上传到家目录下(/user/hadoop)
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-04-09 21:56 input
刷新浏览器并查看

选择Utilities——>Browse the file system

选择user

选择hadoop

选择input

<2>第二步:执行hadoop自带实例
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt NOTICE.txt README.txt share
etc input libexec logs output sbin
[hadoop@server1 hadoop]$ rm -rf input/ output/ #删除上篇博文实验结果,以便更清楚的查看本次实验的结果(其实这步可做,也可不做)
[hadoop@server1 hadoop]$ ls
bin etc include lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep input output 'dfs[a-z.]+'
刷新浏览器并查看

点击output

[hadoop@server1 hadoop]$ bin/hdfs dfs -ls
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2019-04-09 21:56 input
drwxr-xr-x - hadoop supergroup 0 2019-04-09 22:08 output
[hadoop@server1 hadoop]$ bin/hdfs dfs -cat output/*
1 dfsadmin
1 dfs.replication
#当然也可以下载到本地进行查看
[hadoop@server1 hadoop]$ bin/hdfs dfs -get output
[hadoop@server1 hadoop]$ ll -d output/
drwxr-xr-x 2 hadoop hadoop 42 Apr 9 22:12 output/
[hadoop@server1 hadoop]$ cat output/*
1 dfsadmin
1 dfs.replication
[hadoop@server1 hadoop]$ rm -rf output/ #查看之后,删除output目录,以清空本次实验的结果,进行后续实验