分类和回归的主要区别在于:在分类中,我们预测一个状态,在回归中,我们预测一个值。
批量梯度下降法与随机梯度下降法
到目前为止,我们已经见过两种线性回归方法。
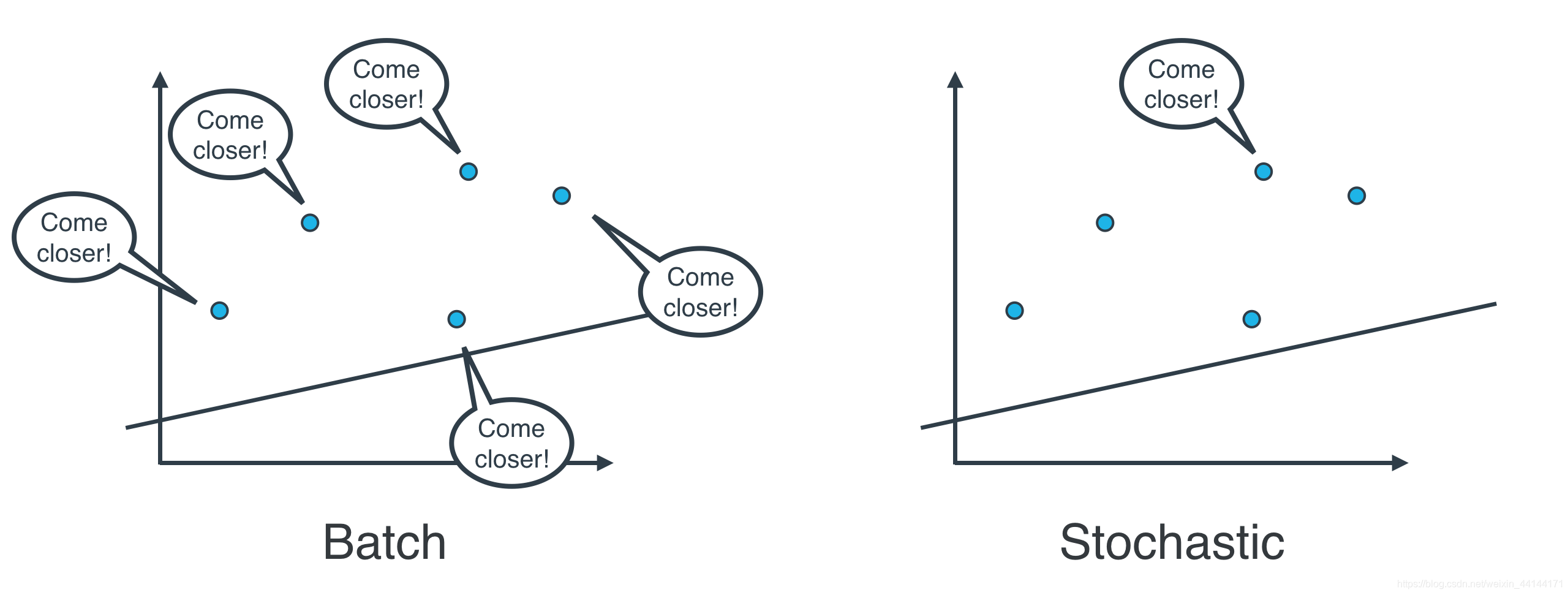
随机梯度下降法:逐个地在每个数据点应用平方(或绝对)误差,并重复这一流程很多次。
具体而言,向数据点应用平方(或绝对)误差时,就会获得可以与模型权重相加的值。我们可以加上这些值,更新权重,然后在下个数据点应用平方(或绝对)误差。
批量梯度下降法:同时在每个数据点应用平方(或绝对)误差,并重复这一流程很多次。
具体而言,向数据点应用平方(或绝对)误差时,就会获得可以与模型权重相加的值。我们可以加上这些值,更新权重,然后同时对所有点计算这些值,加上它们,然后使用这些值的和更新权重。
 问题是,实际操作中使用哪种方法?
问题是,实际操作中使用哪种方法?
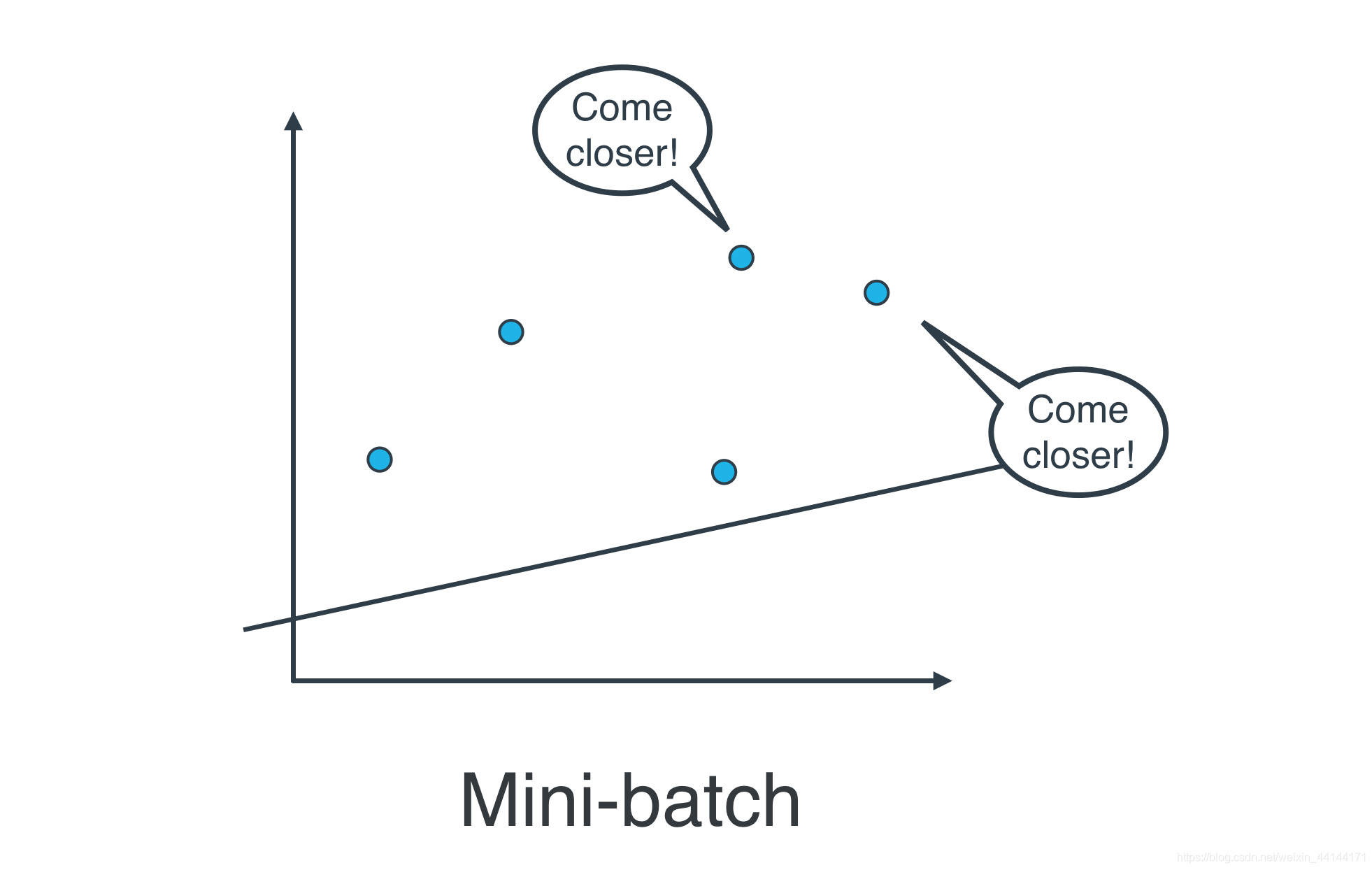
实际上,在大部分情况下,两种都不用。思考以下情形:如果你的数据十分庞大,两种方法的计算速度都将会很缓慢。线性回归的最佳方式是将数据拆分成很多小批次。每个批次都大概具有相同数量的数据点。然后使用每个批次更新权重。这种方法叫做小批次梯度下降法。