爬虫:可见即可爬 # 每个网站都有爬虫协议
基础爬虫需要使用到的三个模块
requests 模块 # 模拟发请求的模块
PS:python原来有两个模块urllib和urllib的升级urllib2,这两个模块使用很繁琐,后来在这两个模块上做了封装就出现了requests模块
beautifulsoup 模块 #数据解析库,re模块正则匹配解析库
senium 模块 # 控制浏览器模块
scrapy 模块 # 把上面三个模块进行一个封装,做成一个大框架,可以做分布式爬虫
requests的基本使用 # 使用 pip3 install requests
requests.get请求
requests.get方法就是帮你凑出一个http请求发送
有三个参数
url : 就是访问的地址
headers: 请求头
params : 输入的内容和页码
现在网站都有反扒技术,所以在模拟发送请求的时候尽量的要模拟的像浏览器一样,否则容易被反扒技术拦截,就算返回200状态码,也是网站返回的假状态码
Request Headers # 这些是请求头的内容,这个直接从浏览器里面复制即可
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9
Cache-Control:max-age=0
Connection:keep-alive
'''正常的cookie写在请求头中,但是因为要经常用,所有requests模块把这个单独拿出来做了处理,请求头中最有用的一个参数就是user_session,当然也可以把整个cookie复制过来'''
Cookie:BAIDUID=8472CC0AF18E17091C3918C619E26E6D:FG=1; BIDUPSID=8472CC0AF18E17091C3918C619E26E6D; PSTM=1553224384; BD_UPN=1a314353; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_645EC=d40c8VmPu6D48Clciaof7nl3ZoeWgKbduZIrfnNW%2FgKxKTRWYmN4scXUrJA; delPer=0; BD_HOME=0; H_PS_PSSID=1462_21120_28771_28721_28557_28833_28585_28640_26350_28604
Host:www.baidu.com # 可以用来判断是不是当前的域,这个用的少
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400 # 这个是浏览器类型,包含浏览器的信息,一般在发送请求的时候都要携带这个
PS:在爬虫的时候一直失败,肯定是模拟的不够像浏览器,所以用浏览器访问一次网站,查看下请求头的内容
request的基本使用和get请求实例
import requests # 爬虫需要用到的模块,模拟发送请求
'''requests的基本使用'''
# 输入中文和特殊字符需要编码
# 如果 查询关键词是中文或者是其他特殊符号,则不的不进行url编码,否则会乱码 'https://www.baidu.com/s?wd=%E8%A5%BF%E7%93%9C'这里地址内的乱码符号就是被转码后的中文或者特殊字符
# 可以from urllib.parse import urlencode #使用这个模块对输入的中文或特殊字符进行编码,但是requests自带了一个参数,param可以实现编码并且自动拼接到地址的后面
key = input('请输入需要的内容: ')
# 发送get请求有返回结果
url = 'https://www.baidu.com'
# 正常的cookie写在请求头中,但是因为要经常用,所有requests模块把这个单独拿出来做了处理
cookies = {'user_session':'BAIDUID=8472CC0AF18E17091C3918C619E26E6D:FG=1; BIDUPSI'}
# 反扒信息之一,要携带头信息的浏览器信息
res = requests.get(url,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
# baidu的页码规律是0=1,10=2的一个10倍数的跳转,所以params里面也可以拼地址进去直接跳转到指定的页数,就是get形式携带的参数
params={'wd': key, 'pn': 70},
cookies=cookies
)
# 这里将获取到的页面内容写入文件,用来验证是否成功
with open('a.html', 'w', encoding='utf-8')as f:
f.write(res.text)
# 请求回来的内容,text是整个页面的内容
print(res.text)
# 请求回来的状态码
print(res.status_code)
request的基本使用和post请求实例
post请求参数有三个 # 和get请求类似
param # 输入的内容和页码
headers # 请求头
Cookie # cookie
PS:先用错误的账号密码登陆,就可以在检查里看到请求发送的地址以及请求发送的数据格式 # 看图
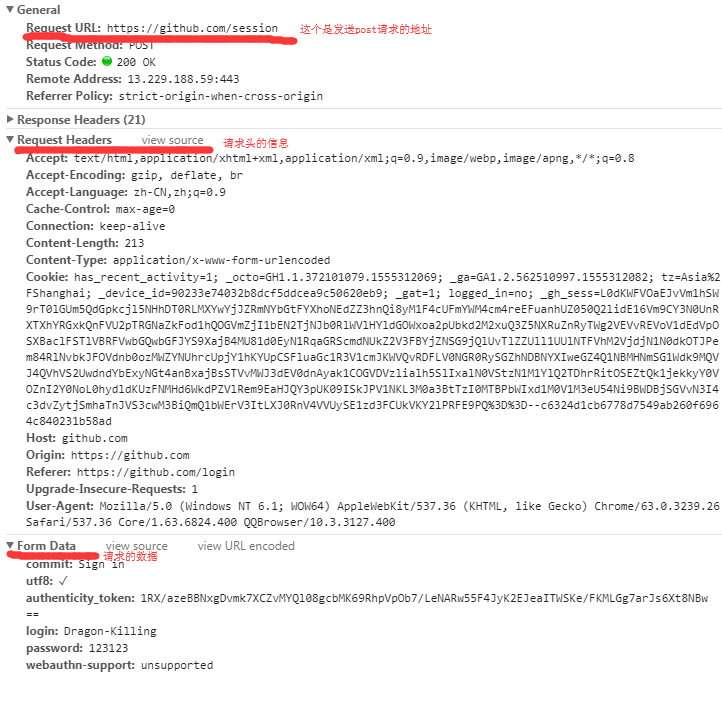
import requests, re
# 第一步
res_login = requests.get('https://github.com/login') # 访问页面获得返回数据
authenticity_token = re.findall(r'name="authenticity_token".*?value="(.*?)"',res_login.text,re.S)[0] # .*?正则表达式贪婪匹配,()是分组匹配,取出来的是一个列表,取索引位0的数据,re.S把字符串看成一行忽略字符串中的换行符
login_cookie = res_login.cookies.get_dict() # 这里获取一个没有经过认证的cookie
# 第二步
data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': authenticity_token,
'login': 'Dragon-Killing',
'password': 'Dk581588',
'webauthn-support': 'unsupported',
} # 这个就是网页里面Form Data携带的数据,就是请求体的数据
res = requests.post(url='https://github.com/session',
data=data,
# 这里也需要携带一个未认证的cookie,现在很多网站都在首次登陆时候都要求携带未认证的cookie,这也是一种反扒手段
cookies=login_cookie)
# 正常登陆成功,返回cookie,下次发送请求携带者cookie
res_cookie = res.cookies.get_dict() #res是一个对象,从对象中获取cookie,然后转成字典
# 第三步
url='https://github.com/settings/emails'
res = requests.get(url,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.6824.400 QQBrowser/10.3.3127.400'},
# baidu的页码规律是0=1,10=2的一个10倍数的跳转,所以params里面也可以拼地址进去直接跳转到指定的页数,就是get形式携带的参数
cookies=res_cookie
)
print('邮箱号' in res.text) # 这里判断邮箱是否在返回的数据中,成功就是True