前言
现在我学习任何一门知识首先就是问:这是什么玩意?要费我脑子学?凭什么?虽然有点功利,但是时刻提醒自己在干什么不失为一种提高学习效率 的手段。废话不多说,切入正题。本文大部分是对大神的归纳,并加入自己的理解。
一、JVM的概念——什么是JVM
JVM(Java Virtual Machine,Java虚拟机)
Java程序的跨平台特性主要是指字节码文件可以在任何具有Java虚拟机的计算机或者电子设备上运行,Java虚拟机中的Java解释器负责将字节码文件解释成为特定的机器码进行运行。因此在运行时,Java源程序需要通过编译器编译成为.class文件。众所周知java.exe是java class文件的执行程序,但实际上java.exe程序只是一个执行的外壳,它会装载jvm.dll(windows下,下皆以windows平台为例,linux下和solaris下其实类似,为:libjvm.so),这个动态连接库才是java虚拟机的实际操作处理所在。
JVM是JRE的一部分。它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM有自己完善的硬件架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。Java语言最重要的特点就是跨平台运行。使用JVM就是为了支持与操作系统无关,实现跨平台。所以,JAVA虚拟机JVM是属于JRE的,而现在我们安装JDK时也附带安装了JRE(当然也可以单独安装JRE)。
--简单来说:使用JVM就是为了支持与操作系统无关,实现跨平台。而通过后面学习我们可以更加清楚了解到Java程序在eclipse等IDE内部是如何执行的。
二、架构图分析
--我认为对于技术是由“先把书读薄再把书读厚”的,这和之前学习为了高考是不一样的,那些都是基础,较为简单,知识体系也没有工作时面对的技术知识体系的那么大。学习了一段时间,我深刻体会到这个道理,别嫌我啰嗦,我是不断在提醒你,你在干什么而已。对于学习后台开发,知识点非常的多,知识体系非常庞大,我们不能死磕一个知识点,关键是要先快速过一遍,以后遇到了再回过头学习,那种快感真是记忆犹新!
先对JVM架构有个整体认识:
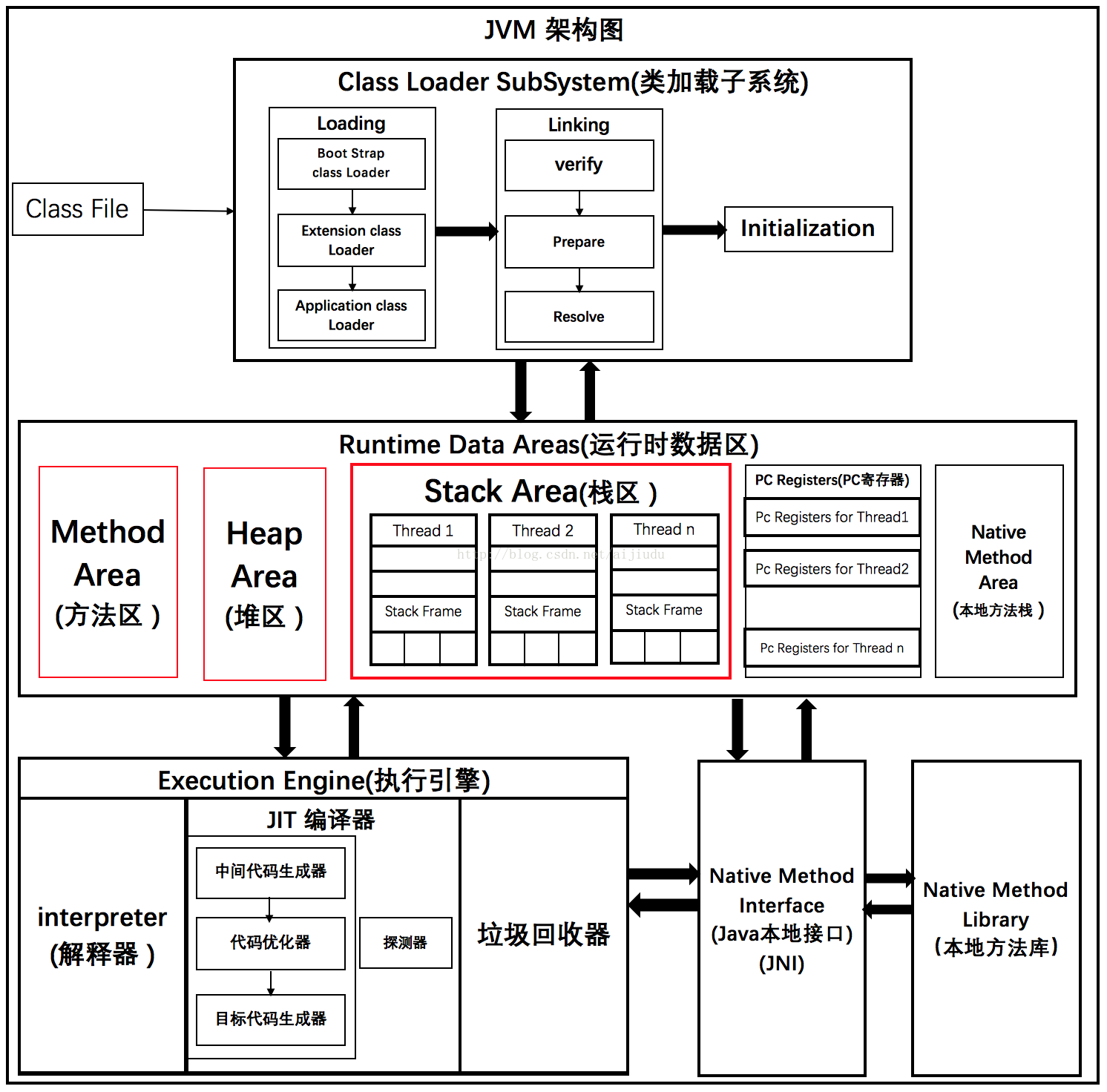
这张图新手是不是看了头晕,过段时间我来画张知识树状图。233
三、JVM的组成——体系结构
1.类加载器子系统
--Java的动态类加载功能是由类加载器子系统处理。当它在运行时(不是编译时)首次引用一个类时,它加载、链接并初始化该类文件。
(1)加载
--类由此组件加载。启动类加载器 (BootStrap class Loader)、扩展类加载器(Extension class Loader)和应用程序类加载器(Application class Loader) 这三种类加载器帮助完成类的加载。
a. 启动类加载器 – 负责从启动类路径中加载类,无非就是rt.jar。这个加载器会被赋予最高优先级。
b. 扩展类加载器 – 负责加载ext 目录(jre\lib)内的类.
c. 应用程序类加载器 – 负责加载应用程序级别类路径,涉及到路径的环境变量等etc.
上述的类加载器会遵循委托层次算法(Delegation Hierarchy Algorithm)加载类文件。
(2)链接
a. 校验 – 字节码校验器会校验生成的字节码是否正确,如果校验失败,我们会得到校验错误。
b. 准备 – 分配内存并初始化默认值给所有的静态变量。
c. 解析 – 所有符号内存引用被方法区(Method Area)的原始引用所替代。
(3)初始化
这是类加载的最后阶段,这里所有的静态变量会被赋初始值, 并且静态块将被执行。
2. 运行时数据区(Runtime Data Area)
--既然虚拟机作为一个虚拟的计算机, 来执行我们的程序, 那么在执行的过程中, 必然要有地方存放我们的代码(class文件); 在执行的过程中, 总会创建很多对象, 必须有地方存放这些对象; 在执行的过程中, 还需要保存一些执行的状态, 比如, 将要执行哪个方法, 当前方法执行完成之后, 要返回到哪个方法等信息, 所以, 必须有一个地方来保持执行的状态。 上面的描述中, “地方”指的当然就是内存区域, 程序运行起来之后, 就是一个动态的过程, 必须合理的划分内存区域, 来存放各种数据——这就是JVM的运行时数据区。
--运行时数据区域被划分为5个主要组件:
(1)方法区(Method Area)
所有类级别数据将被存储在这里,包括静态变量。每个JVM只有一个方法区,它是一个共享的资源。(不是线程安全的)
(2)堆区(Heap Area)
所有的对象和它们相应的实例变量以及数组将被存储在这里。每个JVM同样只有一个堆区。由于方法区和堆区的内存由多个线程共享,所以存储的数据不是线程安全的。
(3)栈区(Stack Area)
对每个线程会单独创建一个运行时栈。对每个函数呼叫会在栈内存生成一个栈帧(Stack Frame)。所有的局部变量将在栈内存中创建。栈区是线程安全的,因为它不是一个共享资源。栈帧被分为三个子实体:
a.局部变量数组 – 包含多少个与方法相关的局部变量并且相应的值将被存储在这里。
b.操作数栈 – 如果需要执行任何中间操作,操作数栈作为运行时工作区去执行指令。
c.帧数据 – 方法的所有符号都保存在这里。在任意异常的情况下,catch块的信息将会被保存在帧数据里面。
(4)PC寄存器
每个线程都有一个单独的PC寄存器来保存当前执行指令的地址,一旦该指令被执行,pc寄存器会被更新至下条指令的地址。
(5) 本地方法栈
本地方法栈保存本地方法信息。对每一个线程,将创建一个单独的本地方法栈。
--结合下图和上文对运行时数据区会有更深刻的理解和印象吧:

3.执行引擎
--分配给运行时数据区的字节码将由执行引擎执行。执行引擎读取字节码并逐段执行。
(1) 解释器::
解释器能快速的解释字节码,但执行却很慢。 解释器的缺点就是,当一个方法被调用多次,每次都需要重新解释。
(2)编译器:
JIT编译器消除了解释器的缺点。执行引擎利用解释器转换字节码,但如果是重复的代码则使用JIT编译器将全部字节码编译成本机代码。本机代码将直接用于重复的方法调用,这提高了系统的性能。
a. 中间代码生成器 – 生成中间代码
b. 代码优化器 – 负责优化上面生成的中间代码
c. 目标代码生成器 – 负责生成机器代码或本机代码
d. 探测器(Profiler) – 一个特殊的组件,负责寻找被多次调用的方法。
(3) 垃圾回收器:(面试必考!)
--收集并删除未引用的对象。可以通过调用"System.gc()"来触发垃圾回收,但并不保证会确实进行垃圾回收。
a.JVM的垃圾回收只收集那些由new关键字创建的对象。
b.如果不是用new创建的对象,你可以使用finalize函数来执行清理。
4.Java本地接口 (JNI):
JNI 会与本地方法库进行交互并提供执行引擎所需的本地库。
5.本地方法库:
它是一个执行引擎所需的本地库的集合。
本文转自https://blog.csdn.net/aijiudu/article/details/72991993