版权声明:版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/z_feng12489/article/details/89183618
4. 随机梯度下降
梯度
- 导数 (标量)
- 偏微分 (函数延某个方向的变换量 标量)
- 梯度 (函数变化量最大的方向 向量)
梯度的意义:模为变换率大小,矢量方向。
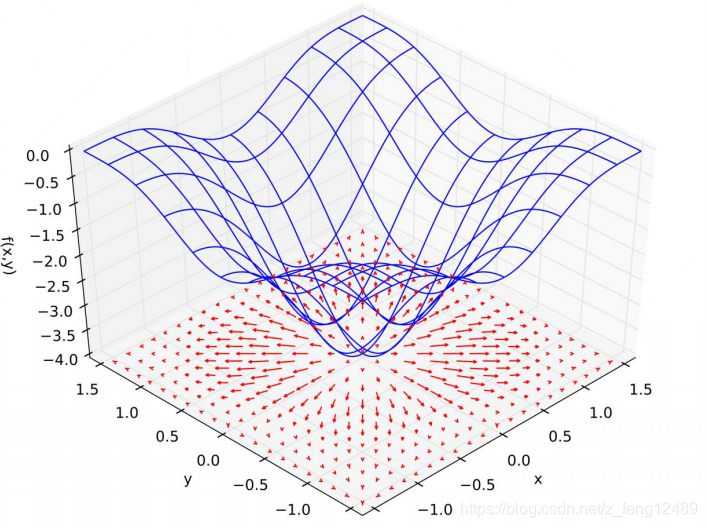
如何求取最小值:梯度下降

影响优化器优化精度的两个重要因素:
- 局部极小值
- 鞍点
凸函数才会有全局最小值,通常情况下存在局部极小值。
(ResNet-56 论文-2018 何凯明)

影响优化器搜索过程效果的因素:
- 初始化状态
- 学习率
- 动量(逃离局部极小值)
- …
常见函数的梯度
| 函数类型 | 函数 | 导数 |
|---|---|---|
| 常函数 | c | 0 |
| 线性函数 | ax | a |
| 二次函数 | 2ax | |
| 幂函数 | ||
| 指数函数 | ||
| 指数函数 | ||
| 对数函数 | ||
| 对数函数 | lnx | 1/x |
| 三角函数 | sin(x) | cos(x) |
| 三角函数 | cos(x) | sin(x) |
| 三角函数 | tan(x) | sec(x) |
激活函数
- Sigmoid/Logistic 会伴随严重的梯度弥散现象(长时间梯度的不到更新)。

求导:

z = torch.linspace(-100,100,5)
z #tensor([-100., -50., 0., 50., 100.])
torch.sigmoid(z) #tensor([0.00e+00, 1.92e-22, 5.00e-01, 1.00e+00, 1.00e+00])
- tanh 常用于循环神经网络

求导:
z = torch.linspace(-2, 2, 5)
z #tensor([-2., -1., 0., 1., 2.])
torch.tanh(z) #tensor([-0.9640, -0.7616, 0.0000, 0.7616, 0.9640])
- ReLu Rectified Linear Unit 整形的线性单元 (最常用的激活函数)


z = torch.linspace(-2, 2, 5)
z #tensor([-2., -1., 0., 1., 2.])
torch.relu(z) #tensor([0., 0., 0., 1., 2.])
Loss 损失函数的梯度
典型的损失函数:
- Mean Squared Error(均方误差)
- Cross Entropy Loss(交叉熵损失)
- 可用于二分类
- 可扩展为多分类
- 常与 softmax 函数搭配使用
- Mean Squared Error( 均 方 误 差 )
-
- Gradient API:
-
1.torch.autograd.grad(loss, [w1, w2, ...])
[w1 grad, w2 grad, ...]
2.loss.backward()
w1.grad
w2.grad
...
#Mean Square Error (MSE)
x = torch.ones(1)
y = torch.ones(1)
w = torch.full([1], 2, requires_grad=True)
mse = F.mse_loss(y,w*x) #(y-w*x)
mse #tensor(1., grad_fn=<MeanBackward1>)
#1.auto.grad (requires_grad)
torch.autograd.grad(mse, w) #(tensor([2.]),)
#2.backward
mse = F.mse_loss(y,w*x) #(y-w*x)
mse.backward()
w.grad #tensor([2.])
-
Cross Entropy Loss( 交 叉 熵 损 失)
-
Softmax

- 转移成概率值
- 拉大值之间的差距
Softmax 求导:

得到:


from torch.nn import functional as F
a = torch.rand(3, requires_grad=True)
p = F.softmax(a, dim=0)
a #tensor([0.4588, 0.0768, 0.0897], requires_grad=True)
p #tensor([0.4212, 0.2875, 0.2912], grad_fn=<SoftmaxBackward>)
torch.autograd.grad(p[0], a, retain_graph=True) #output scalar
#(tensor([ 0.2438, -0.1211, -0.1227]),)