在进行文本预处理的过程中,有时候需要将文本中的日期数据提取出来并将其按照一定的格式标准化,进而进行比较大小之类的操作。
1、日期提取
在文本中日期呈现的方式各种各样,如:2018.12.2、2018.12.02、2018-12-2、2018-12-02、201/12/2、二零一八年十二月二日、2018年12月2日 等等,我们可以利用正则表达式将其提取出来。
假设存在如下文本数据,我们需要提取文中最后出现的日期数据:
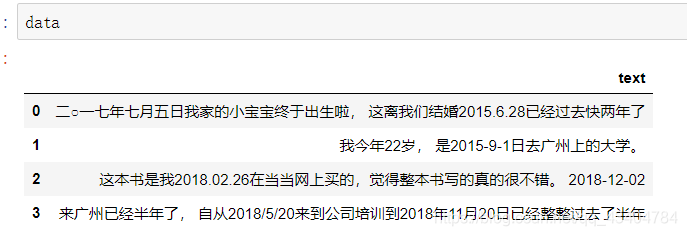
利用正则表达式和apply函数将日期一次性提取出来:
import re
pattern = re.compile('\d{4}[\.\-/年]{1}\d{1,2}[\.\-/月]{1}\d{1,2}[日号]{0,1}|二.{3}年.{1,2}月.{1,3}[日号]{1}')
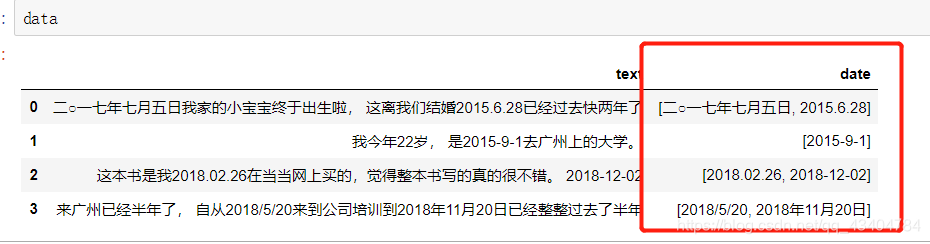
data['date'] = data['text'].apply(lambda s: pattern.findall(s))
结果如下图所示:
若要选取最后出现的日期,可更改一下代码:
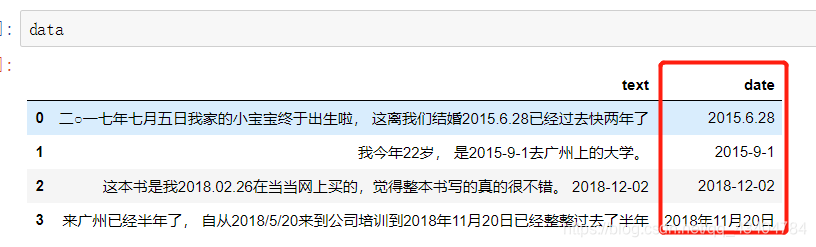
data['date'] = data['text'].apply(lambda s: pattern.findall(s)[-1])
效果如下:
2、日期格式化
通过正则表达式提取的日期格式比较乱,无法对其进行进一步的计算或者比较,因此可将其格式化为××××-××-×× eg:2018-01-01这种字符串。
2.1、中文替换为数字,连接符替换为 -
注意: 大的中文数字必须放在小的之前,否则替换的时候会产生奇妙的化学反应。(哈哈哈哈)
replace_dic = {'元': '01', '二○一七': '2017', '二○一八': '2018', '二〇一七': '2017', '二〇一八': '2018', '年': '-', '月': '-',
'日': '','\.': '-', '/': '-', '号': '','三十一': '31', '三十': '30', '二十九': '29', '二十八': '28', '二十七': '27',
'二十六': '26', '二十五': '25','二十四': '24', '二十三': '23', '二十二': '22', '二十一': '21', '二十': '20', '十九': '19',
'十八': '18','十七': '17', '十六': '16', '十五': '15', '十四': '14', '十三': '13', '十二': '12', '十一': '11', '十': '10',
'九': '09', '八': '08', '七': '07', '六': '06', '五': '05', '四': '04', '三': '03', '二': '02','一': '01'}
for key, value in replace_dic.items():
data['date'] = data['date'].apply(lambda s: re.sub(key, value, s))
2.2、某些个位数前加上0
经过以上处理,所有的日期数据已经快接近我们想要的最终模式了,唯一的问题出在1-9这些数字, 在标准的格式中,应为01 - 09。因此我们还需做最后一步调整。
# 首先自定义格式化函数。
def to_time(s):
a = s.split('-')
# return pd.datetime.strptime(s,'%Y-%m-%d')
return str(datetime.date(int(a[0]), int(a[1]), int(a[2])))
import datetime
data['date'] = data['date'].apply(to_time)
最后的结果:

其实在这里这样处理也可以:
data['time'] = pd.to_datetime(data.date, format='%Y-%m-%d')
但是前面的代码,可以在自定义函数中做一些其他的修改,可以捕捉错误等等。如:
def to_time(s):
try:
a = s.split('-')
# return pd.datetime.strptime(s,'%Y-%m-%d')
return str(datetime.date(int(a[0]), int(a[1]), int(a[2])))
except:
return ''
3、完整的代码
import re
import pandas as pd
import datetime
# 1、自定义数据
data = pd.DataFrame({'text':['二○一七年七月五日我家的小宝宝终于出生啦, 这离我们结婚2015.6.28已经过去快两年了',
'我今年22岁, 是2015-9-1去广州上的大学。',
'这本书是我2018.02.26在当当网上买的,觉得整本书写的真的很不错。 2018-12-02',
'来广州已经半年了, 自从2018/5/20来到公司培训到2018年11月20日已经整整过去了半年']})
# 2、日期提取
pattern = re.compile('\d{4}[\.\-/年]{1}\d{1,2}[\.\-/月]{1}\d{1,2}[日号]{0,1}|二.{3}年.{1,2}月.{1,3}[日号]{1}')
data['date'] = data['text'].apply(lambda s: pattern.findall(s)[-1])
# 3、格式化日期数据
replace_dic = {'元': '01', '二○一七': '2017', '二○一八': '2018', '二〇一七': '2017', '二〇一八': '2018', '年': '-', '月': '-',
'日': '','\.': '-', '/': '-', '号': '','三十一': '31', '三十': '30', '二十九': '29', '二十八': '28', '二十七': '27',
'二十六': '26', '二十五': '25','二十四': '24', '二十三': '23', '二十二': '22', '二十一': '21', '二十': '20', '十九': '19',
'十八': '18','十七': '17', '十六': '16', '十五': '15', '十四': '14', '十三': '13', '十二': '12', '十一': '11', '十': '10',
'九': '09', '八': '08', '七': '07', '六': '06', '五': '05', '四': '04', '三': '03', '二': '02','一': '01'}
for key, value in replace_dic.items():
data['date'] = data['date'].apply(lambda s: re.sub(key, value, s))
# 首先自定义格式化函数。
def to_time(s):
a = s.split('-')
# return pd.datetime.strptime(s,'%Y-%m-%d')
return str(datetime.date(int(a[0]), int(a[1]), int(a[2])))
import datetime
data['date'] = data['date'].apply(to_time)