GROUP BY语句
GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列对结果进行分组,然后对每个组进行聚合操作
下面我们根据手机的名字对数据进行聚合操作,分别计算每个手机的销量
![]()
Having语句
HAVING子句允许用户通过一个简单的语法完成原本需要通过子查询才能对GROUP BY语句产生的分组进行条件过滤的任务。如下是对前面的查询语句增加一个HAVING语句来限制输出结果中销量大于100:
![]()
JOIN语句
INNER JOIN
内连接 中,只有进行连接的两个表中都存在与连接标准相匹配的数据才会被保留下来。例如,如下这个查询对苹果公司的股价(股票代码AAPL)和IBM公司的股价(股票代码IBM)进行比较。股票表stocks进行自连接,连接条件是ymd字段内容必须相等

On子句指定了两个表间数据进行连接的条件。where子句限制了左边表是AAPL的记录,右边表是IBM的记录。同时用户可以看到这个查询中需要为两个表分别指定表别名。
LEFT OUTER JOIN
左外连接通过关键字LEFT OUTER进行标识:

运行结果如下所示:

在这种join连接操作中,join操作符左边表中符合where子句的所有记录将会被返回。join操作符右边表中如果没有符合on后面连接条件的记录时,那么从右边表指定选择的列的值将会是NULL。
因此,在这个结果集中,我们看到Apple公司的股票记录都返回了,而d.dividend字段的值通常是NULL,除了当天有支付股息的那条记录。
RIGHT OUTER JOIN
右外连接会返回右边表所有符合WHERE语句的记录。左表中匹配不上的字段值用NULL代替。

运行结果如下所示:
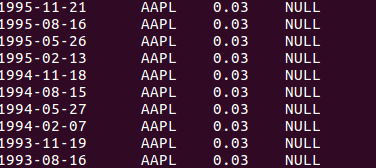
FULL OUTER JOIN
完全外连接将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
如果我们将前面的查询改成一个完全外连接查询的话,事实上获得的结果和之前的一样。

ORDER BY和SORT BY
Hive中的ORDER BY语句和其他的SQL方言中的定义是一样的。其会对查询结果集执行一个全局排序。这也就是说会有一个所有的数据都通过一个reducer进行处理的过程,对于大数据量,这个过程可能会消耗太过漫长的时间来执行。
Hive增加了一个可供选择的方式,也就是SORT BY,其只会在每个reducer中队数据进行排序,也就是执行一个局部排序过程。这可以保证每个reducer的输出数据都是有序的这样可以提高后面进行的全局排序的销量。
对于这两种情况,语句区别仅仅是,一个关键字是order,一个关键字是sort。用户可以指定任意期望进行排序的字段,也可以在字段后面加上ASC关键字,表示按升序排序,或加上DESC关键字,表示按降序排序。

下面是一个类似的例子,不过使用的是sort by:![]()
上面介绍的两个查询看上去几乎是一样,不过如果使用的reducer的个数大于1的话,那么输出结果的排序就大不一样了。既然只保证每个reducer的输出是局部有序的,那么不同reducer的输出就可能会有重叠的。
因为order by操作可能会导致运行时间过长,如果属性hive.mapred.mode的值是strict的话,那么Hive要求这样的语句必须加也LIMIT语句进行限制。默认情况下,这个属性的值是nonstrict,也就是不会也这样的限制。
含有SORT BY的DISTRIBUTE BY
DISTRIBUTE BY控制map的输出在reducer中是如何划分的。MapReduce job中传输的所有数据都是按照键-值对的方式进行组织的,因此Hive将用户的查询语句转换成MapReduce job时,其必须在内部使用这个功能。

运行结果如下所示:

distribute by和group by在其控制着reducer是如何接受一行行数据进行处理这方面是类似的,而sort by则控制着reducer内的数据是如何进行排序的。
需要注意的是,Hive要求distribute by语句要写在drop by语句之前。
CLUSTER BY
CLUSTER BY=DISTRIBUTE BY+SORT BY
如下所示:

运行结果如下:

需要数据源的留言留下邮箱地址